
In the spirit of sharing failures and learning from them, I'd like to tell you a story about a time a younger me helped create a "clever" system to organize a content hierarchy. This cautionary tale is mostly for fun, but also to document some of the neat things and painful lessons I learned along the way. Names and entities have been changed to protect the innocent 😜
But ...why?
Long, long ago in a product team far away, there existed a project to create a new, more flexible hierarchy for collections of books. Originally, our data was set up like so:
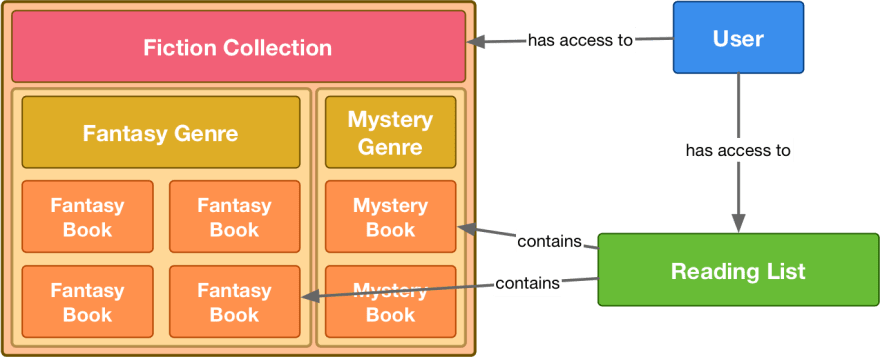
A user had access to a collection of books ("Fiction" in this case); a collection contained several genres, which in turn contained individual books. A user could be granted access to see everything within a collection, and could create "reading lists" so they could favorite/categorize books based on their own criteria.
This worked well - a user could see all the fiction books in the collection, and they could even add these books to a personalized reading list. Later on, however, our product team started testing out a new collection:
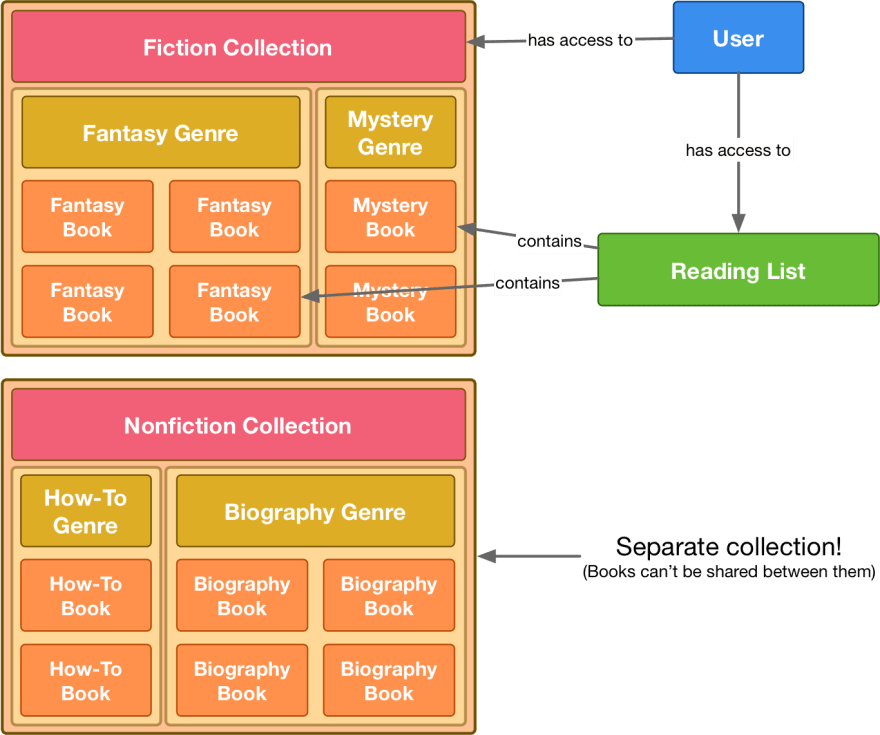
We didn't initially want to allow all users to access the new "Nonfiction" collection, so we granted access to that separately.
We had a few issues - mainly that a user could only access and create reading lists from one collection at a time, and they had to switch between them manually in the UI. This worked well when we only had one collection, but lacked flexibility when we started adding more. Additionally, if a book appeared in more than one genre, its entry would need to be duplicated - our data structure didn't expect a book to have more than one genre 😬 Users were also prevented from adding books to their reading lists that didn't belong in any of our collections at all yet. If they wanted a one-stop shop to track what they were reading, they'd be out of luck.
The idea was that as we added more collections, we needed a better way to categorize our content and avoid duplication. Folks from across the organization worked together to create a new content structure:

Rather than segmenting our content into "collections," we'd house everything in a mega-collection - called the "library" - and allow books to appear in multiple genres. We hoped this would make our content more discoverable in searches, less duplicative, and would allow users to have reading lists with both fiction AND non-fiction titles on them.
Technologies
We were already working with some tried-and-true technologies in this application:
- Postgres database (most SQL databases have some form of support for database views)
- ActiveRecord within a Ruby on Rails application as an ORM
Now, our job as engineers was to implement the product vision and provide the tools our coworkers needed to interact with this new model. We had a choice: Do we create a series of discrete tables linked to each other by standard relations, or do we try something new?
(spoiler alert - we tried something new.)
Going Graph
It didn't take us long to decide that if we were going to create this new "world view," we wanted to play with some cool new technology along the way - and to be fair, it did seem like a graph model would serve the current use case well. We drew out some concepts of what we expected our entities and relations to look like.

Users would be able to add their own books to their reading lists if they so chose - but that didn't mean they belonged in the library's collection.
That done, we discussed implementation - how would we bring this into our application? How would this fit into our current codebase? After some research and exploration, it was decided that we'd avoid bringing in a true graph database (like Neo4j, OrientDB, etc.). Cost was potentially an issue, and we wanted to avoid forcing our developers to learn new concepts and a new query language until we were sure this model was something that we really wanted to stick with.
That having been decided, we drew up our approach to storing our graph entities and relations ("nodes" and "edges") in our relational database:

The Good
Once we got our new hierarchy set up, rendering nested relationships became simple. We could easily convert a higher-level model (like a genre) into a tree-like JSON representation (in the real world, we had several additional levels to deal with - think category, subcategory, etc. - so this was pretty helpful).
library.to_json
# =>
{
id: 1,
name: 'Library',
genres: [{
id: 1,
name: 'Fantasy',
books: [{
name: 'Book 1',
id: 10
},{
name: 'Book 2',
id: 20
}]
}]
}
Interacting with the data also became pretty simple - our nodes all had the same attributes, so we used pretty generalized views and services to display, create, and edit everything from the library and reading lists to genres and books.
<h1>Editing <%= @node.name %></h1>
<%= render 'node-edit-form', node: @node %>
Another bonus was getting to understand graph structures pretty well. We learned how to traverse a graph, how to filter a graph, how to check for cyclical references - and more.
The Bad
Everything worked well in the beginning - when everything looked the same. Before too long, though, we found that we needed additional information in the payloads we sent down to the front end.
# Our data model started to become more complex...
{
id: 1,
name: 'Library',
genres: [{
id: 1,
name: 'Fantasy',
book_count: 2,
books: [{
name: 'Book 1',
available_for_checkout: true,
author: 'Bob Bobberson',
id: 10
},{
name: 'Book 2',
available_for_checkout: false,
author: 'Frances Farina',
id: 20
}]
}]
}
We started mixing behavior and additional attributes in with structure of the library hierarchy rather than allowing the graph structure to do what it was good at - defining the relationships of entities to one another. We started shoehorning in details about individual nodes, complicating the logic required to render our over-generalized views. These views quickly became complicated and full of switches on node type.
<h1>Editing <%= @node.name %></h1>
<% if @node.type == 'Genre' %>
<p>Book count: <%= @node.book_count %></p>
<%= render 'node-edit-form', node: @node %>
<% elif @node.type == 'Book' %>
<%= render 'book-node-edit-form', node: @node %>
<% else %>
<%= render 'node-edit-form', node: @node %>
<% end %>
After a while, it became clear that our application was a graph database that we'd smashed into the shape of a bookstore, instead of a bookstore that utilized a graph database to store data. Our codebase was littered with overly generic, meaningless methods and controllers that were difficult at best to understand.
# Instead of this...
def save_book(book_data)
# Clearly saving a book to the DB
save_to_graph(book_data)
end
# we ended up with this:
def save_node(node_data)
# What are we saving here??
Nodes.save(node_data)
end
The Awful
As the library grew in size, querying became downright awful. Queries ballooned in complexity; complicated preloading was required in order to avoid making hundreds of queries. Many of our services relied on recursion to generate serialized JSON or aggregate data, which added mental overhead when trying to figure out what your bug was, what was causing it, and where your extra queries were being made. When new devs joined our team, it was harder for them to ramp up on what we were doing, which caused frustration and wasted a lot of time. We used tools like recursive SQL views and terrifying "octo-UI" (see below) admin tools that caused more grief than joy.
This graph is similar to a stopgap admin interface we implemented to allow admins to interact with the graph - screenshot taken from the D3 example gallery
The last straw(s)
All told, we worked with this psuedo-graph structure for a little under a year before we gave up the ghost and started ripping it out. Some notable reasons:
- As mentioned above, writing services and views for a general idea of a "node" did not work well once our data model evolved
- This idea of graph-like structures stored in a relational database was certainly not supported by ActiveRecord - this resulted in inefficient and confusing queries
- Super importantly, we (as developers) didn’t create tooling that would have made these concepts easy to work with, for other developers and for the end users of our product.
Lessons learned
While I wouldn't do this again, I certainly learned a few things along the way.
- Recursive views are cool 🤓
- Never put your personal curiosity ahead of someone else's livelihood.
- Use the right tool for the job!
The next time you find yourself looking at a shiny new technology and feel the desire to use it in a product that's critical to your company's day-to-day business, I encourage you to consider your choices carefully.
Do I even need INSERT SHINY THING HERE? ...do I really?
Most often, it's in your best interest to choose "boring technology" (Choose Boring Technology, Dan McKinley) over "the new hotness." If you consistently opt for exciting, innovative technologies over longer-lived and widely-understood systems, you're going to increase the cost/headache related to onboarding new engineers and maintaining your entire system.
I would argue that this also applies to the patterns we use to build our software. When we hid the implementation details of our graph structure poorly, we introduced code that felt unintuitive and confused new developers. If we had done a better job isolating that code, it would have been much easier to swap out our "homegrown" version for the real thing later on.

The article linked above makes a great case for limiting the number of technical solutions you use as a team. Instead of spending your energy troubleshooting and maintaining a homegrown solution, you can choose to focus on solving business problems - actual people's problems. Add too many unfamiliar technologies, and you run the risk of having one or two "experts" (masters of the arcane) on how your application works rather than a straightforward codebase that most folks can get up to speed on in a reasonable amount of time.
If the honest answer to "do I need this?" is "yes, this is by far the best solution for my problem," ensure you have the time, support, team bandwidth, and expertise to do so. If these conditions are met, then you need to do your research - and please, use the right tools for the job 🙇♀️





Top comments (12)
Hi Anna, thanks for the post. It's a useful insight at the process of decision making in a team.
While I agree with the conclusion (going with the tested and tried way) I would argue that in a way you did exactly that by sticking with the techonologies you were using before and if this is not a case of "we should have actually tried plan b", in reality.
Initially you said:
which is perfectly reasonable but in the end you also said:
Couldn't this be a case of a well thought out structure (the graph idea) that had to be bent and implemented on top of something not designed for such?
I'm not saying that going the graph database route would have resulted in the perfect system, I can't know that. What I'm saying is that the team actually chose the boring technology, it might have been too boring for the business logic.
That's a really good point! I'd go one step further than boring technology, and include boring patterns. The biggest problem we had developing with the graph was that we allowed implementation details to leak out of our models into into other parts of the application. We created a codebase that felt unfamiliar and unintuitive to new developers, with pitfalls and traps that hamstrung them wherever they turned.
In our case, we thought we were setting ourselves up to try out something new - if it worked, we could just switch to a "real" graph database later on. Because we didn't do a good job of isolating the graph code in the database, we instead ended up with a hybrid Ruby/Postgres graph implementation that was near impossible to change or get rid of.
Thank you rhymes!
I feel you, you were probably drowning in self joins at the DB level and checks in the Ruby code to dance around AR. At least you now know the limitations of object relational models :-D
That's for sure! 😂💯
Thanks for your story. It was definitely interesting to read.
I do agree with your third lesson learnt that one should use the right tool for the right job.
And I tend to agree that nobody should use a shiny new technology just for the sake of using that shiny new technology. Even though in some cases it might be a good decision.
But, I think you use this idea showing that for you it was a bad idea to use a "shiny new technology". I think it would have been a good thing, but actually, you didn't introduce any new technology. If I understand well, you kept using Postgres and ActiveRecord that were not new at all to you.
On the other hand, you tried to implement an almost 300 years old concept (the one of graphs) with old tools and it didn't work out that well. Reading about the issues you had on your journey, those are the main reasons why one should consider using a native graph database.
Anyway, I don't want to judge old decisions, in hindsight many are clever. And it's always respectable to admit bad decisions, failures.
The main thing I don't agree with that you used anything new and shiny as the concept of graphs is far from new and you didn't use any new technology based on graphs.
I would rephrase it a bit: Do I even need INSERT SHINY THING HERE? ...do I really need it NOW?
enphasis should be on building evolvable software. Descisions of today should not be implemented in a way that they are set in stone - and all the pain and fear of making THE DESCISION will go away. Implementing graph in sql is a very good idea, as you try out new data structure without overhead of leaning how to run and query niché solution. When data structure was proven to pay off, you should have used all abstraction levels a good developer places here and there to swap it for more mature and flexible tool. This is what IoC is there for, remember all your interviews? “... well with ioc in orm layer we can change database from mysql to ...”
there are ways to achieve reasonable separation of concerns - by watching at abstraction levels you have in single module (as in class) and extract something that doesnt fit )
experimenting is awesome, but we all need to learn how to do it safely )
Hey @anna, thanks for sharing your experience. With one sentence, would you recommend using a real GraphDB (e.g. Neo4j) in this case. To be honest, I'm not sure what is your advice by just reading the Good/Bad/Ugly sections :D.
I'm asking as I'm considering endeavouring the GraphDB journey soonish...
Hi Stan, thanks for your comment! I'd recommend using a real graph database over a "fake" one, in any case. Our mistake in this case wasn't really "we should've used Neo4j instead of Postgres" - our mistake was that we didn't hide the implementation details well enough to make it easy to deal with. It also turned out in the end that the business needs didn't require something as robust as a graph organizational structure.
Regardless of which technology you go with, just keep in mind that you want to make it easy to swap out later if need be.
“After some research and exploration, it was decided that we'd avoid bringing in a true graph database (like Neo4j, OrientDB, etc.). Cost was potentially an issue, and we wanted to avoid forcing our developers to learn new concepts and a new query language”
=> Sorry but this decision is so stupid in many ways I cannot stay quiet...
Anyway well written and thanks for sharing. Conclusion is gold : right tool for right use cases. Architects are like vampyrs they do not like silver bullets.
Hi Cédrick - in hindsight, yes: it would have been worth it to use an actual graph database for this project. The cost wasn't the technology itself, but the cost of deployment, hosting, and instrumentation - and at the time, the PaaS we were using had less-than-stellar support for actual graph databases. The reasons we chose to implement the graph ourselves were flawed - and the whole reason I wanted to share :) Thanks!
really nice article
Good article.