
The transition from relational databases to the world of NoSQL is not easy. Literally, everything is different. Sometimes this can be so overwhelming that you don't know how to solve a problem so trivial that virtually nonexistent in the world of SQL databases.
Today, I want to tell you about such a problem.
Imagine that in your database you store Order records in the table. And you need information about the last (newest) order number. (Why? It's not relevant now.)
Last Order number in SQL
When using SQL this problem is trivial. All you need to do is write:
SELECT orderId FROM Orders ORDER BY orderId DESC LIMIT 1;
The query is simple and very efficient (especially when we have indexes). Well done SQL 👏
Last Order number in DynamoDB
And this is where it starts to be problematic. I won't give you a solution right away because to fully understand it some knowledge about DynamoDB is required.
A bit of theory about DynamoDB
Let's start by saying that the equivalent of SQL's SELECT in DynamoDB are two commands scan and query. Both are used to retrieve information from a table (in DynamoDB we only have the concept of a table, not the entire database). However, they are significantly different from each other. The scan method scans the contents of the whole table and returns it to us as a collection of elements.
For the following table scan returns 6 items because there are six orders in the whole table.
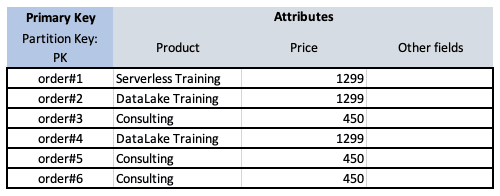
When using scan we could retrieve information about all orders and process them in the code, e.g. in the Lambda function, filter the data and return the last order number.
This approach is obviously the worst possible, as we are retrieving much more data from the database than we want (collection of Orders vs single Order number). This will affect the running time of our application, but also the cost because in DynamoDB we pay for each query / amount of data returned. To make matters worse, when dealing with large amounts of data, we have to page through the results.
So let us consider other options.
The query method is used to retrieve data from a local collection, that is, elements in the database that share a common (same value) Partition Key.
I'm trying to make this article concise and simple, so I'm not going to discuss how Amazon DynamoDB is internally designed. However, I strongly encourage you to learn it on your own, because it is simply a good architecture school and it will help you understand why this database is used the way it is.
In our order table (above), each order has a different Partition Key value, so using the query method simply doesn't make sense here since we don't have local collections.
On a side note, a local collection for an Order could be a list of goods in the single order. In that case, each item's Primary Key would consist of two values (a composite key):
- Partition Key
- Sort Key
The table would change to the state presented below. Then calling query with the parameter order#2 would return us two items because in this order someone bought two products: DataLake Training and Consulting.

However, this is a different data access pattern in DynamoDB, and I've presented it to you as a side note.
Let's move back to the main problem.
What can we do since neither scan nor query are suitable to return the latest Order number?
The GetItem method
There is also GetItem, a method that returns us a single item from the database when given a specific Primary Key value. It's kind of like getById(id) or in SQL:
SELECT * FROM Orders WHERE orderId = 'orderNumber';
That's cool, but how could we get this orderNumber if this is what we want to pull from the database in the first place? 🤔
Pointer strategy
This is where the pointer strategy comes in.
We can replace an unknown value with something known, some constant, and refer to the database through that constant. This element with the constant Partition Key will be only one in the entire table. Thus we can use it as a pointer to store the value of the most recent order.
To our first table, we add another element with a Partition Key of always equal to LAST_ORDER (our constant string). Such an element has one attribute named OrderId with the value of the most recent order. Each time we add a new Order to the table, we also update the value of the LAST_ORDER element to the value of the new orderId.
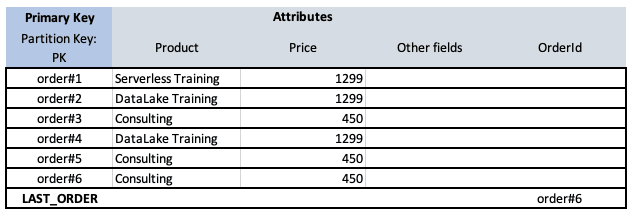
Now, all we need to do is call a simple getItem('LAST_ORDER') method that returns the last order number for us in an optimal way.
Advanced techniques
Taking into account that the DynamoDB table is usually part of a larger system, let's consider what happens when multiple processes write to the database in parallel (directly or through the SQS queue - doesn't matter). Certainly, at some point it will happen that the last item written to the database, will not be the last order. Then the LAST_ORDER pointer will wrongly point to an older Order.
We could solve this problem by using the SQS FIFO queue, but there is a much simpler and cheaper solution for this.
We just need to apply a ConditionExpression when saving a new version of the LAST_ORDER element, which will check if the new orderId value is greater than the one currently stored in the database. If it is it will update it, if not, it will not.
Thanks to this, using one write to the database, we can update the value without downloading and checking it on the code side. In addition, this method is idempotent (in case we get the same event multiple times, it will not change the database state on subsequent calls).
How to do it?
It's time for some code. My sample implementation in JavaScript:
async createPointer(orderId) {
const pointer = new Pointer({ orderId })
const params = {
Item: pointer.toItem(),
ReturnConsumedCapacity: 'TOTAL',
TableName: process.env.ordersTableName,
ConditionExpression: 'attribute_not_exists(#orderId) OR #orderId < :newId',
ExpressionAttributeNames: {
'#orderId': 'orderId'
},
ExpressionAttributeValues: {
':newId': { N: `${orderId}` }
}
}
log('createPointer params', params)
try {
await this.dynamoDbAdapter.create(params)
} catch (error) {
if (error.code === 'ConditionalCheckFailedException') {
log(`LAST_ORDER pointer already exists and is greater than ${orderId}. Skipping update.`)
} else {
log('Error', error)
throw error
}
}
return pointer
}
Code listing explanation:
-
Line 4 - the Pointer class implements a method that converts a
Pointerobject into the JSON that the DynamoDB API expects. Below is the implementation of this method. -
Line 7 - conditional expression: when to write to the database and when not to? The
attribute_not_exists(#orderId)is needed so that when the database is empty, the code also executes and writes the item for the first time. From this point on, only the second part#orderId < :newIdof the condition will have meaning. -
Line 19 - if the condition is not met, the DynamoDB API returns a
ConditionalCheckFailedException, which in our case is expected sooner or later.
And here is a Pointer class implementation.
class Pointer {
constructor({ orderId, createdAt = new Date() }) {
this.orderId = parseInt(orderId)
this.createdAt = createdAt instanceof Date ? createdAt : new Date(createdAt)
}
key() {
return {
PK: { S: 'LAST_ORDER' }
}
}
static fromItem(item) {
return new Pointer({
orderId: item.orderId.N,
createdAt: item.createdAt.S
})
}
toItem() {
return {
...this.key(),
orderId: { N: this.orderId.toString() },
createdAt: { S: this.createdAt.toISOString() },
}
}
}
Please note, the style of this class is ripped off from Alex DeBrie 😃
He is an author of The DynamoDB Book which is the best thing to teach yourself how to use this database. Since I read that book I stared using many advanced techniques that he described. I highly recommend his book.
Summary
I hope this simplified, but taken from my real system, example helped you better understand how to use DynamoDB. I've only covered a small area of knowledge, but at the same time I've shown you how to solve a specific problem you may encounter in your projects.
I'm aware that DynamoDB has a steep learning curve - there's no denying that - but honestly, I can't imagine serverless systems without Amazon DynamoDB database. In 9 out of 10 cases, I would choose DynamoDB over AWS RDS (including Aurora Serverless).





Top comments (0)