
Web scraping:
Web Scraping is a way to collect all sorts of publicly available data like prices, text, images, contact information and much more from the world-wide-web. This can be useful when trying to collect data that might take a person a lot of time to collect and organize manually.
Some of the most useful use cases of web scraping include:
Scraping product prices from e-commerce websites such as amazon, ebay or alibaba.
Scraping social media posts, likes, comments, followers or bios.
Scraping contacts from websites like yellowpages or Linkedin.
Puppeteer
While there are a few different libraries for scraping the web with Node.js, in this tutorial, i'll be using the puppeteer library.
Puppeteer is a popular and easy to use npm package used for web automation and web scraping purposes.
Some of puppeteer's most useful features include:
- Being able to extract a scraped element's text content.
- Being able to interact with a webpage by filling out forms, clicking on buttons or running searches inside a search bar.
- Being able to scrape and download images from the web.
- Being able to see the web scraping in progress using headless mode.
You can read more about puppeteer here
Installation
For this tutorial, I will suppose you already have npm and node_modules installed, as well as a package.json and package-lock.json file.
If you don't, here's a great guide on how to do so: Setup
To install puppeteer, run one of the following commands in your project's terminal:
npm i puppeteer
Or
yarn add puppeteer
Once puppeteer is installed, it will appear as a directory inside your node_modules.
Let's make a simple web scraping script in Node.js
The web scraping script will get the first synonym of "smart" from the web thesaurus by:
Getting the HTML contents of the web thesaurus' webpage.
Finding the element that we want to scrape through it's selector.
Displaying the text contents of the scraped element.

Let's get started!
Before scraping, and then extracting this element's text through it's selector in Node.js, we need to setup a few things first:
Create or open an empty javascript file, you can name it whatever you want, but I'll name mine "index.js" for this tutorial. Then, require puppeteer on the first line and create the async function inside which we will be writing our web scraping code:
index.js
const puppeteer = require('puppeteer')
async function scrape() {
}
scrape()
Next, initiate a new browser instance and define the "page" variable, which is going to be used for navigating to webpages and scraping elements within a webpage's HTML contents:
index.js
const puppeteer = require('puppeteer')
async function scrape() {
const browser = await puppeteer.launch({})
const page = await browser.newPage()
}
scrape()
Scraping the first synonym of "smart"
To locate and copy the selector of the first synonym of "smart", which is what we're going to use to locate the synonym inside of the web thesaurus' webpage, first go to the web thesaurus' synonyms of "smart", right click on the first synonym and click on "inspect". This will make this webpage's DOM pop-up at the right of your screen:
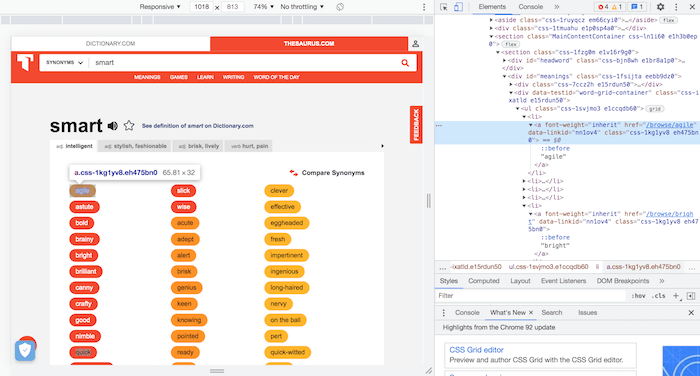
Next, right click on the highlighted HTML element containing the first synonym and click on "copy selector":

Finally, to navigate to the web thesaurus, scrape and display the first synonym of "smart" through the selector we copied earlier:
First, make the "page" variable navigate to https://www.thesaurus.com/browse/smart inside the newly created browser instance.
Next, we define the "element" variable by making the page wait for our desired element's selector to appear in the webpage's DOM.
The text content of the element is then extracted using the evaluate() function, and displayed inside the "text" variable.
Finally, we close the browser instance.
index.js
const puppeteer = require('puppeteer')
async function scrape() {
const browser = await puppeteer.launch({})
const page = await browser.newPage()
await page.goto('https://www.thesaurus.com/browse/smart')
var element = await page.waitForSelector("#meanings > div.css-ixatld.e15rdun50 > ul > li:nth-child(1) > a")
var text = await page.evaluate(element => element.textContent, element)
console.log(text)
browser.close()
}
scrape()
Time to test
Now if you run your index.js script using "node index.js", you will see that it has displayed the first synonym of the word "smart":
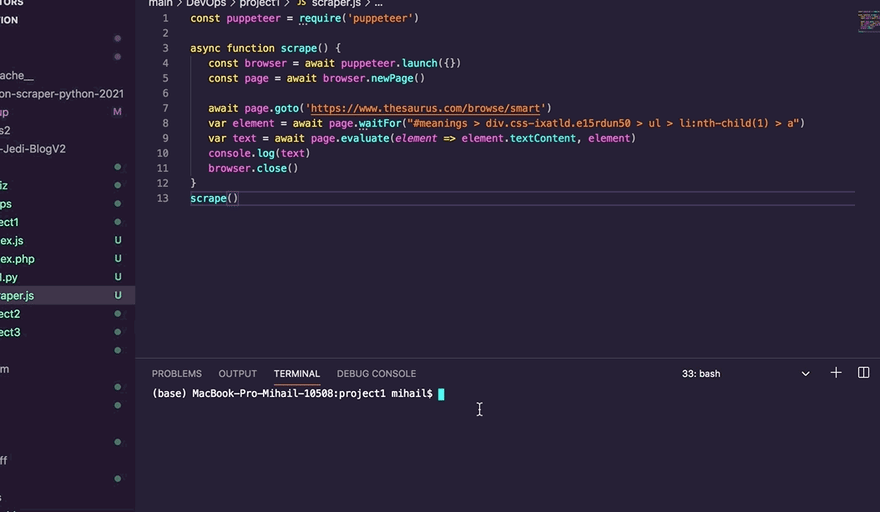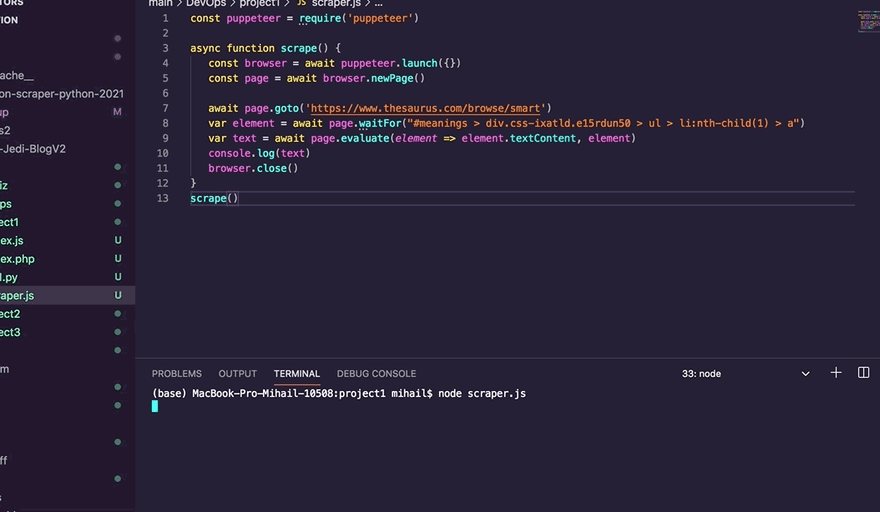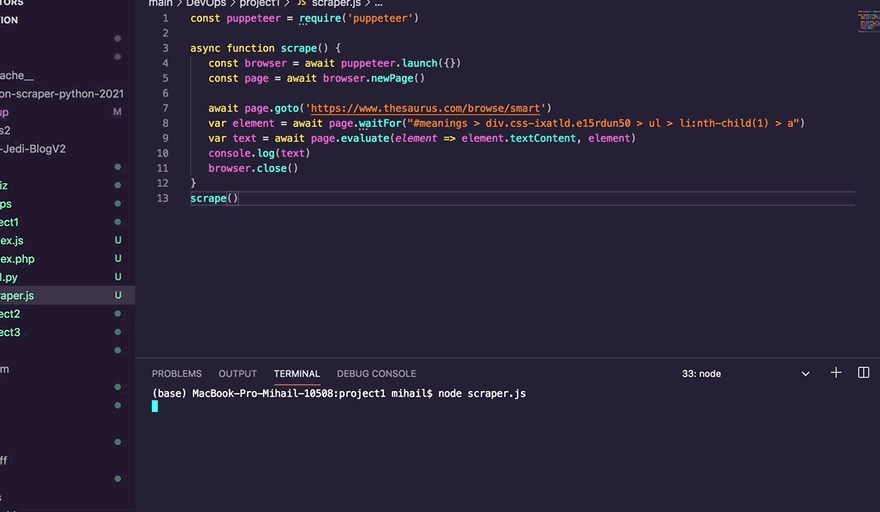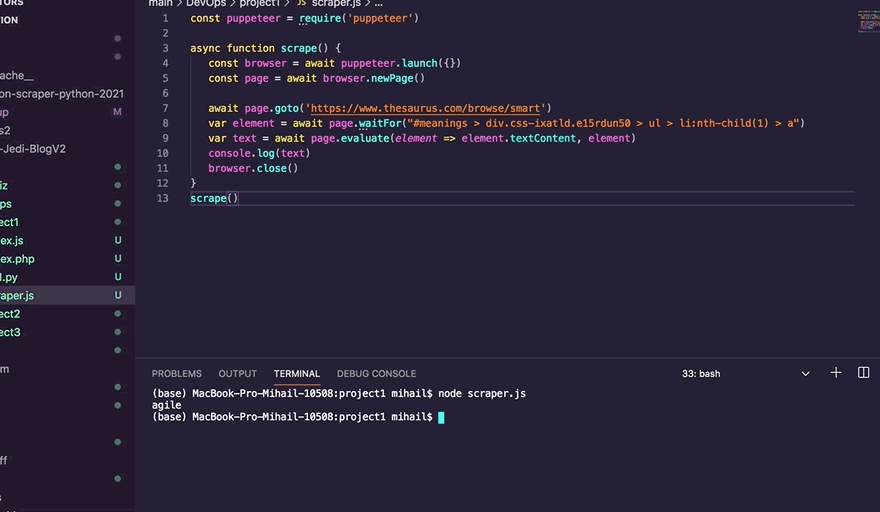
Scraping the top 5 synonyms of smart
We can implement the same code to scrape the top 5 synonyms of smart instead of 1:
index.js
const puppeteer = require('puppeteer')
async function scrape() {
const browser = await puppeteer.launch({})
const page = await browser.newPage()
await page.goto('https://www.thesaurus.com/browse/smart')
for(i = 1; i < 6; i++){
var element = await page.waitForSelector("#meanings > div.css-ixatld.e15rdun50 > ul > li:nth-child(" + i + ") > a")
var text = await page.evaluate(element => element.textContent, element)
console.log(text)
}
browser.close()
}
scrape()

The "element" variable will be: "#meanings > div.css-ixatld.e15rdun50 > ul > li:nth-child(1) > a" on the first iteration, "#meanings > div.css-ixatld.e15rdun50 > ul > li:nth-child(2) > a" on the second, and so on until it reaches the last iteration where the "element" variable will be "#meanings > div.css-ixatld.e15rdun50 > ul > li:nth-child(5) > a".
As you can see, the only thing that is altered in the "element" variable throughout the iterations is the "li:nth-child()" value.
This is because in our case, the elements that we are trying to scrape are all "li" elements inside a "ul" element,
so we can easily scrape them in order by increasing the value inside "li:nth-child()":
li:nth-child(1) for the first synonym.
li:nth-child(2) for the second synonym.
li:nth-child(3) for the third synonym.
li:nth-child(4) for the fourth synonym.
And li:nth-child(5) for the fifth synonym.
Final notes
While web scraping has many advantages like:
Saving time on manually collecting data.
Being able to programmatically aggregate pieces of data scraped from the web.
Creating a dataset of data that might be useful for machine learning, data visualization or data analytics purposes.
It also has 2 disadvantages:
Some websites don't allow for scraping their data, one popular example is craigslist.
Some people consider it to be a gray area since some use cases of web scraping practice user or entity data collection and storage.
Wrapping up
Hopefully this article gave you some insight into web scraping in Node.js, it's practical applications, pros and cons, and how to extract specific elements and their text contents from webpages using the puppeteer library.





Top comments (7)
Very helpful and straightforward. I did find that
waitForis deprecated. In this instance I made use ofwaitForSelector. Thanks!waitForwill be deprecated as mentioned in this GitHub issue of Puppeteer and by ESLint, usewaitForSelectorinstead.Just tested it and works.
excellent article.... i tried several "scraping" suggestions (that is a new concept to me) and your code is the only example i could find that works. thank you so much for providing this.
a couple points/questions:
waitForis giving deprecation messages, maybe usewaitForSelectorinstead?github.com/puppeteer/puppeteer/iss...
let elements = await page.waitForSelector(cssSelector);what does the
, element)part do? is this the same thing?let text = await page.evaluate(element => { return ( element.textContent)})shortcuts can be a bit confusing sometimes.
EDIT:
let text = await page.evaluate(element => { return ( element.textContent)})well that did NOT work at all. 😣 however, this worked for me (below) - the word
elementused multiple times is confusing my newbie brain:let elements = await page.waitForSelector(cssSelector); // note 'elements' - plural
let text = await page.evaluate(element => element.textContent, elements);
but i am still confused on how the
await page.evaluate(element =>line works. is this some sort of shortcut? its like "elements" is being used, but i cannot figure out how?Thanks for the article. I've been looking into web scraping for some time but everyone out there uses Python, which I don't command. I never thouught of using Node. I'll try this.
Good luck, I've been web scraping using Node.js for 3 years now and I can say that you won't be disappointed!
To the point web scraping quick tutorial. I was wondering if you edit your Article and update "waitFor" to waitForSelector because waitFor is depricated and giving a warning in the terminal.
Thank you @code_jedi for this outstading tutorial. I was doing web scraping in python previously and i wanted to shift to nodejs but nodejs seems to slower than python bs4. I scraped this data which is a post of technewztop from internet. I am using python for scraping and php for auto posting. Please tell if i can auto post from nodejs instead of php? is it possible? Can we increase the speed of web scraping in nodejs? Please do reply me.