
Today, I’m going to walk you through using AppSync’s Direct Lambda feature. I helped build it this Summer after all, so I should be able to express how simple, yet effective, this feature is in allowing you to configure Lambdas for your API on AppSync.
Go ahead and jump to the section labelled Let there be an API! if you’d like to skip the bits about what the old workflow for a Lambda resolver was like.
I’d first like to make a point about why Direct Lambdas were necessary. Here's a picture to help demonstrate that point.

In order to set up a Lambda resolver for a field on AppSync, you’d first have to check out the resolver mapping template reference, then you’d have to set up your mapping templates in a language called VTL. These templates translate data back and forth between your Lambda. Finally, you’d be able to set up your Lambda to expect the data as translated by the mapping templates.
Notice that I mentioned that you had to write code in two separate places: the Lambda and the mapping templates, which might be in the Appsync console editors, uploaded through the SDK, or in a CloudFormation template. This introduces unnecessary coupling between your Lambda code and your mapping templates, which is probably not optimal for your code-base, nor your mental health.
This is where the problem lies: if it’s at all complicated, then it’s too complicated. The goal is to think less… Er, less about things that don’t matter, that is.
If only there was an easier way to configure a Lambda resolver on AppSync. If only there was a way to write less code and get more done.
There is now a way, Direct Lambdas.
Let there be an API!
I’d like to avoid making this tutorial dry and boring so I’ve decided that our API will be all about awesome, original, definitely-not-cringe dad jokes! Plus, we can utilize a friendly API called icanhazdadjokes that offers an unprecedented collection of definitely-not-cringe-worthy dad jokes for free. That’s a low price!
Let’s start off with a specification of what our API should do. I’d like to create an API that will allows a client to either get a random Joke or get a Joke specified by an ID.
What makes up a Joke?
joke: The content of the joke
id: The id of the joke
imageUrl: A permalink to the joke
cringe: A boolean that shows if the joke is cringe or not
Here’s how the entire thing will work:

If you’d like to follow along, go ahead and open up the AWS console and go to the AppSync service. Create a new API, click ‘build it from scratch’, and name it something accurate like, “Personality Generator”.
Pop into the ‘Schema’ tab and overwrite whatever is in the editor with this:
type Joke {
id: ID!
joke: String!
cringe: Boolean!
imageUrl: String!
}
type Query {
hurryAndGiveMeADadJoke: Joke
giveMeADadJoke(id: ID!): Joke
}
Then head over to the Lambda service, which is where we will create a Lambda function. Keep your region in mind. You can find it in the URL on the Lambda service dashboard. We will need it later on in the tutorial.
Go ahead and click on ‘Create function’ and fill out the name under the ‘Author from scratch’ selection with something like “Does_The_Thing”. Make sure that the selected runtime is Node.js 12.x, which is what we are using for this tutorial. Direct Lambdas are available in any runtime, so don’t fret if you’d prefer using a different language.
At this point. click ‘Create function’ at the bottom of the page and then put this starter code into the editor and click the ‘save’ button on the top right of the page.
exports.handler = (event, context, callback) => {
console.log(event);
};
Head back to the AppSync console and switch over to the ‘Data Sources’ tab. We’re going to create a new data source, which will point to the Lambda function we just created! Click on ‘Create data source’ and fill out the form like this:
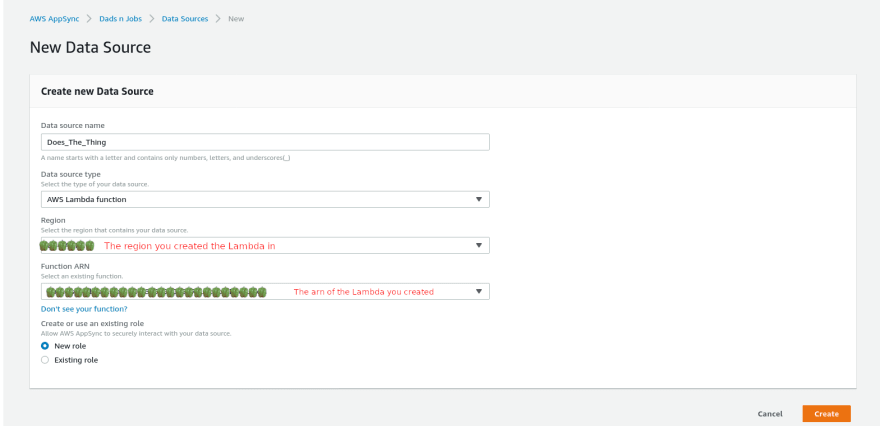
This will create a data source named Does_The_Thing that is connects to the Lambda function we created earlier. Then, it creates a role that will allow AppSync to use the Lambda.
Now, we get to do the fun stuff! We can configure this Lambda to be used as a resolver. Head on back to the ‘Schema’ tab. We’re going to attach this new data source to resolver of the fields imageUrl, hurryAndGiveMeADadJoke, and giveMeADadJoke. So, for all of those follow these steps:
In the Resolvers section of the Schema, go to the field you wish to attach the Lambda to.
Click ‘Attach’!
In the Resolver Editor Page, find and select our new Lambda data source from the drop-down.
Make sure that the two toggles are off, signalling that AppSync will not use any mapping templates.
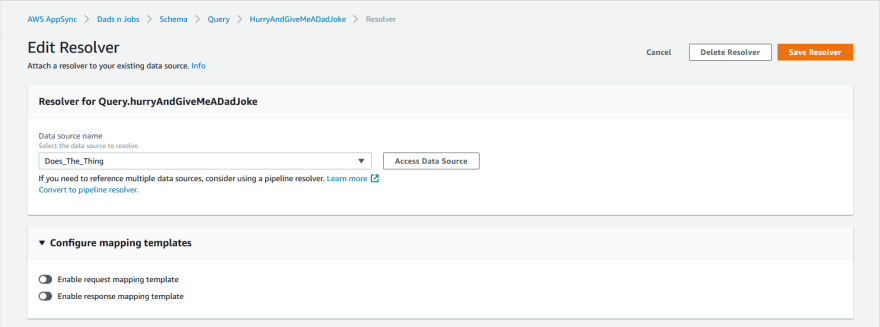
If it looks like the picture above, click ‘Save resolver’. Go ahead and do that same thing for the other two fields I mentioned earlier.
Now we can finally make a query! Head over to the ‘Queries’ tab on the AppSync console and put this into the editor:
{
hurryAndGiveMeADadJoke {
imageUrl
id
joke
cringe
}
giveMeADadJoke(id: "9EBljqWDAsc") {
imageUrl
joke
cringe
}
}
Then send that query off (at the time of writing, you just click the little orange play button) and… Oh no! We get this:
"data": {
"hurryAndGiveMeADadJoke": null,
"giveMeADadJoke": null
}
Luckily, this response was expected, since we never did anything useful with the Lambda. Right now, our Lambda only prints out the event object passed in from AppSync.
We should head over to the Lambda editor we left open earlier and then to the monitoring tab which allows us to view our logs from CloudWatch. The logs will show the event object we printed out when we made our last query. If you don’t want to click that many times, or are simply just following along here is what the event object looks like for me:

Now that you know what is contained in the event object when the cringe field is invoked (it’s just the AppSync Context object), we can go ahead and finish filling out the Lambda function in the Lambda console. Here’s some logic that should work for us:
const https = require('https');
/* The event object contains a bunch of special goodies!
Those goodies are explained in more detail in the AppSync Mapping Template Reference for Lambdas.
We will use only a few of the fields in this example. */
exports.handler = (event, context, callback) => {
console.log(event);
const options = {
host: 'icanhazdadjoke.com',
method: 'GET',
headers: { 'Accept': 'application/json' }
};
// The next line shows off how you can access the info object, which contains all sorts of exciting stuff
// pertaining to the GraphQL query.
switch (event.info.fieldName) {
case 'hurryAndGiveMeADadJoke':
console.log('Getting a random dad joke.');
getRequest(options, callback);
return;
// Here we use the arguments object passed in by AppSync.
case 'giveMeADadJoke':
console.log(`Getting the joke with ID: ${event.arguments.id}`);
options['path'] = `/j/${event.arguments.id}`;
getRequest(options, callback);
return;
// For this field, we get to use the source object!
// Source contains the data belonging to the parent object for this current field.
case 'imageUrl':
console.log(`Returning the image url for the dad joke ${event.source.id}`);
const imgUrl = `https://icanhazdadjoke.com/j/${event.source.id}.png`;
callback(null, imgUrl);
return;
case 'cringe':
console.log('All dad jokes are cringe.');
callback(null, true);
return;
default:
callback(`Sorry pal, we can't do anything for the field: ${event.info.fieldName}`);
}
};
// This thing uses https to get the info we need, then calls the callback we pass in!
// https is super clunky looking, but it's built into Node, so it's easy to use.
const getRequest = (options, callback) => {
https.get(options, (res) => {
let body = '';
res.on('data', (d) => {
body += d;
});
res.on('end', () => {
body.trim();
callback(null, JSON.parse(body));
});
})
.on('error', (err) => {
callback(err);
});
};
This will handle resolving all the fields that we currently have set up. One thing that I’d like to note is that the event object and the **callback **function are both sent from AppSync.
The callback responds with the result of the resolver, but the actual data is passed into the the 2nd parameter of the callback, the first parameter is used for responding with errors, as you can see in the default case within the switch.
The event object holds a bunch of goodies we checked out in the logs earlier! Here are some of the goodies that we used in our Lambda:
event.info holds the field name that is currently being resolved.
event.arguments holds all the arguments passed into query.
event.source has the data belonging to the resolved parent object for this current field.
To learn more about those goodies and all the other stuff in the event object, check out the Resolver Mapping Template Context Reference.
Hopefully, everything within the rest of the Lambda is easy to understand, but take a moment to read through and understand what’s happening when we invoke this Lambda.
Let’s head back to the Query page on the AppSync console. Run that same query we ran before and… hooray!
{
"data": {
"hurryAndGiveMeADadJoke": {
"imageUrl": "https://icanhazdadjoke.com/j/ciiNuXDY0wc.png",
"id": "ciiNuXDY0wc",
"joke": "Where did Captain Hook get his hook? From a second hand store.",
"cringe": true
},
"giveMeADadJoke": {
"imageUrl": "https://icanhazdadjoke.com/j/9EBljqWDAsc.png",
"joke": "What do you call a fish with no eyes? A fsh.",
"cringe": true
}
}
}
We’ve successfully set up an API that does everything we set out to do and we’ve done so without all the VTL for the resolver mapping templates! Now you know how to effectively use Direct Lambdas on AppSync.
If you’d like to walk through AppSync’s reference on Direct Lambdas, check out the Resolver Mapping Template Reference for Lambdas or the configuring Direct Lambda section in the AppSync documentation. Ed Lima, a Sr. product manager at AWS also created an awesome blog post that covered using Direct Lambdas in a few different languages.
Now, keep in mind, Direct Lambdas can only be used in Lambda resolvers and miss some of the awesome functionality the VTL allow, so there are still plenty of use-cases for it, even with the existence of Direct Lambdas.
I hope this example helps you figure out how to use AppSync’s Direct Lambda feature to create a GraphQL API. I believe that it allows developers to write less code and get more done. Let me know how effective you think they are!
Feel free to connect with me!





Top comments (2)
Awesome addition! Thanks for the write up. Very clear.
What would be the pros and cons vs vtl? Integration with supported services
seems nicer with vtl. What about performance? Can you expand on these?
Pros of VTL:
Cons of VTL:
More on that:
VTL has a lot of nice utilities built by AppSync. With it, you can do fine tuned time-stamping, string manipulation, batching, and other useful stuff like that. With the mapping templates, you also have the benefit of having full control over pre-invoke and post-response code execution. You have full control over the entire 'life-cycle' of the resolver.
With Direct Lambda, you have the option to relinquish a bit of that control and handle only the invoked Lambda. You can't do anything fancy before and after the Lambda, but you still have all the data that was originally available in the request mapping template, the Context object. If you can do it in VTL, you can do it in your Lambda. It's more about where the code is executed with this option.
About the performance, AppSync's resolver mapping template reference for Lambda touches on that briefly at the end of the page.
I take that as 'there is no VTL to execute, so there is no need to translate the data, and it is just passed through to the Lambda'. I believe that it can improve performance. By how much and in what cases? I'm not sure right now but that'd be a good experiment to run!