
This post was written by Aaron Xie and was originally published at Educative.io
In today's tech industry, understanding system design is more important than ever. With applications becoming increasingly large, it's important to design architectural patterns that are both efficient and reliable. Now, system design is often a requirement to land your dream software engineering job.
Today, we will go over system design principles by designing Instagram and TinyURL.
You will be learning:
How to design TinyURL
How to design Instagram
Wrapping up and resources

How to design TinyURL
What is TinyURL
TinyURL is a URL shortening web service that creates shorter aliases for long URLs. When clicking the short link, users are redirected to the original URL. This service is useful because short links save space and allow users to type long URLs more easily.
Requirements and goals of the system
When designing a TinyURL-like application, there are some functional and non-functional requirements to consider.
Non-functional requirements:
The system must be highly available. If the service fails, all the short links will not be functional.
URL redirection should happen in real-time with minimal latency.
Shortened links should not be predictable in any manner.
Functional requirements:
When given a URL, our service will generate a shorter alias of the original URL. This new link will be extensively shortened so that it can be easily copied and pasted.
The short link should redirect users to the original link.
Users should have the option to pick a custom short link for their URL.
Short links will expire after a default timespan, but users are able to specify the expiration time.
Capacity estimation and constraints
Our system will be read-heavy. There will be a large number of redirection requests compared to new URL shortenings. Let’s assume a 100:1 ratio between read and write.
Traffic estimates: Assuming, we will have 500M new URL shortenings per month, with 100:1 read/write ratio, we can expect 50B redirections during the same period:
What would be Queries Per Second (QPS) for our system? New URLs shortenings per second:
Considering 100:1 read/write ratio, URLs redirections per second will be:
Storage estimates: Let’s assume we store every URL shortening request (and associated shortened link) for five years. Since we expect to have 500M new URLs every month, the total number of objects we expect to store will be 30 billion:
Let’s assume that each stored object will be approximately 500 bytes (just a ballpark estimate – we will dig into it later). We will need 15TB of total storage:
Bandwidth estimates: For write requests, since we expect 200 new URLs every second, total incoming data for our service will be 100KB per second:
For read requests, since every second we expect ~20K URLs redirections, total outgoing data for our service would be 10MB per second:
Memory estimates: If we want to cache some of the hot URLs that are frequently accessed, how much memory will we need to store them? If we follow the 80-20 rule, meaning 20% of URLs generate 80% of traffic, we would like to cache these 20% hot URLs.
Since we have 20K requests per second, we will be getting 1.7 billion requests per day:
To cache 20% of these requests, we will need 170GB of memory.
One thing to note here is that since there will be a lot of duplicate requests (of the same URL), our actual memory usage will be less than 170GB.
System APIs
We can use REST APIs to expose the functionality of our service. Below is an example of the definitions of the APIs for creating and deleting URLs without service:
createURL(api_dev_key, original_url, custom_alias=None, user_name=None, expire_date=None)
Parameters:
api_dev_key (string): the API developer key of a registered account. This will be used to throttle users based on their allocated quota.
original_url (string): Original URL to be shortened.
custom_alias (string): Optional custom key for the URL.
user_name (string): Optional user name to be used in the encoding.
expire_date (string): Optional expiration date for the shortened URL.
Returns: (string)
A successful insertion returns the shortened URL; otherwise, it returns an error code.
deleteURL(api_dev_key, url_key)
The url_key is a string that delineates the shortened URL that needs to be deleted. A successful deletion will return URL Removed.
Database design
Let's look at some observations about the data we are storing:
The service needs to store billions of records.
The service is read-heavy.
Each object is small (less than 1K).
There are no relationships between each record, except for storing which user created the short link.
Schema:
We need one table for storing information about the URL mappings and another database for the user's data who created the short links.
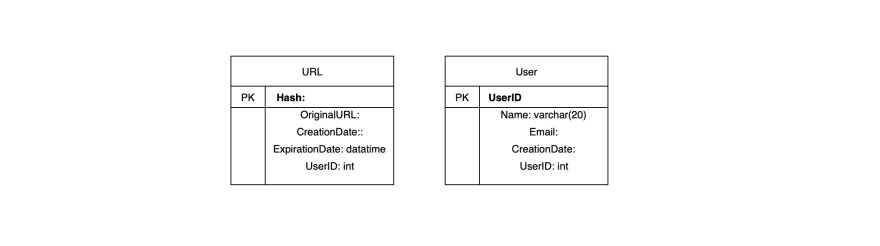
What type of database do we use?
The best choice would be to use a NoSQL database store like DynamoDB or Cassandra since we are storing billions of rows with no relationships between the objects.
Basic system design and algorithm
The biggest question for our service is how to generate a short and unique key when given an URL. The approach we will be looking at today is by encoding the actual URL.
We can compute a unique hash (e.g., MD5 or SHA256, etc.) of the given URL. The hash can then be encoded for display. This encoding could be base36 ([a-z ,0-9]) or base62 ([A-Z, a-z, 0-9]). If we add + and /, we can use Base64 encoding. A reasonable question would be, what should be the length of the short key? 6, 8, or 10 characters?
Using base64 encoding, a 6 letter long key would result in 64^6 = ~68.7 billion possible strings.
Using base64 encoding, an 8 letters long key would result in 64^8 = ~281 trillion possible strings
With 68.7B unique strings, let’s assume six letter keys would suffice for our system.
If we use the MD5 algorithm as our hash function, it will produce a 128-bit hash value. After base64 encoding, we’ll get a string having more than 21 characters (since each base64 character encodes 6 bits of the hash value). Now we only have space for 8 characters per short key, how will we choose our key then?
We can take the first 6 (or 8) letters for the key. This could result in key duplication, to resolve that, we can choose some other characters out of the encoding string or swap some characters.
There are some potential obstacles when taking this approach:
If multiple users enter the same URL, they will get the same short link.
Parts of the URL can be URL-encoded.
Workarounds: To solve some of these issues, we can append a number from a sequence to each short link URL. This makes it unique even if multiple users provide the same URL.
Another potential solution is to append the user id to the input URL. This would not work if the user is not signed in, and we would have to generate a uniqueness key.
Data partitioning and replication
Inevitably, we will need to scale our database, meaning that we have to partition it so that we can store information about billions of URLs.
-
Range-based partitioning: We can store the URLs in separate partitions based on the first letter of its hash key. So, we save all the URLs with the first letter of their hash key being
Ain one partition and so on.
This approach is problematic because it leads to unbalanced database servers, creating unequal load.
- Hash-based partitioning: With hash-based partitioning, we can take a hash of the object being stored and then calculate which partition to use. The hashing function will randomly distribute the data into different partitions.
Sometimes, this approach leads to overloaded partitions, which can then be solved using Consistent Hashing.
Cache
Our service should be able to cache URLs that are frequently accessed. We can do this through a solution like Memcached, which can store full URLs with respective hashes.
How much cache memory should we have? At first, we can start with around 20% of the daily traffic and adjust based on usage patterns. Based on our previous estimations, we will need 170GB memory to cache 20% of the daily traffic.
Which cache eviction policy should we use? Because we want to replace a link with a more popular URL, we can use the Least Recently Used (LRU) policy for our system.
Load balancer (LB)
There are three places where we can add a load balancing layer to our system:
Between clients and application servers
Between application servers and database servers
Between application servers and cache servers
At first, we could simply use a Round Robin approach that distributes the incoming requests equally among the servers. This is easy to implement and does not create any overhead.
If the server becomes overloaded with this approach, the load balancer will not stop sending new requests to that server. To handle this problem, a more intelligent load balancer solution can be developed that periodically adjusts traffic based on its load.
Master system design.
Educative's system design course teaches you various system design patterns for common interview questions, including Dropbox and Facebook.

Designing Instagram
What is Instagram?
Instagram is a social media platform that allows users to share photos and videos with other users. Like many other social media platforms, users can share their information either publicly or privately.
Today, we will be designing a simple version of Instagram, in which users can share photos, follow other users, and access the News Feed. This consists of the top photos of the people that the user follows.
Requirements and goals
When designing an Instagram-like application, there are some functional and non-functional requirements to consider.
Non-functional requirements:
The service should be highly available.
The acceptable latency of the system should be around 200 milliseconds for the News Feed.
The system should be highly reliable, such that any photo or video in the system will never be lost.
Functional requirements:
The user should be able to search based on photo or video titles.
The user should be able to upload, download, and view photos and videos.
The user should be able to follow other users.
The system should be able to generate a displayed News Feed consisting of the top photos and videos of the people that the user follows.
Some things that will not be within the scope of this project are adding tags to photos, searching for photos with tags, commenting on photos, tagging users, etc.
Capacity estimation and constraints
Let’s assume we have 500M total users, with 1M daily active users.
2M new photos every day, 23 new photos every second.
Average photo file size => 200KB
Total space required for 1 day of photos:
- Total space required for 10 years:
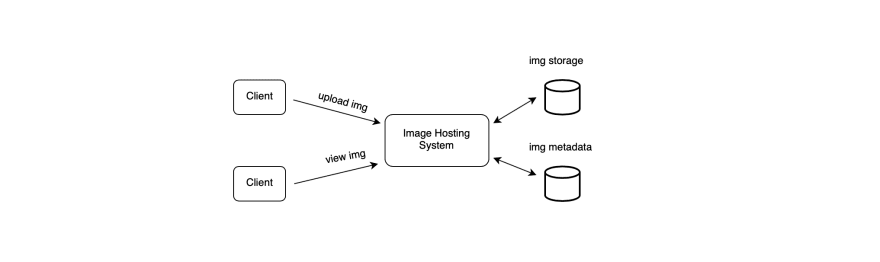
High-level system design
At a high-level, the system should be able to support users uploading their media and other users being able to view the photos. Therefore, our service needs servers to store the photos and videos and also another database server to store the metadata of the media.
Database schema
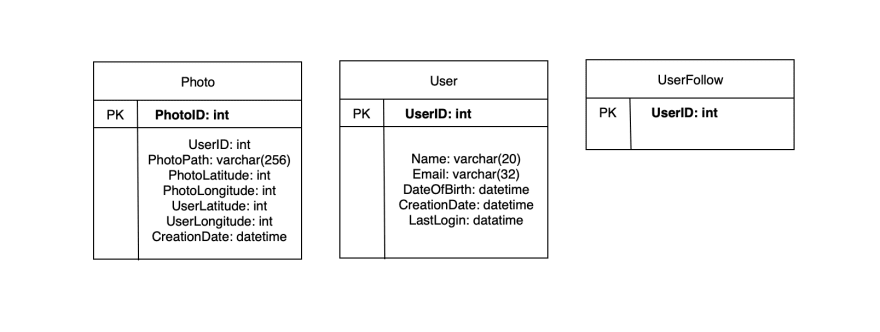
While we could take a straightforward approach by storing the above schema in a Relational Database Management System (RDBMS), some challenges would arise when using a relational database, especially when scaling the application.
We can store the above schema with key-value pairs utilizing a NoSQL database. The metadata for the photos and videos will belong to a table where the key would be the PhotoID, and the value would be an object containing PhotoLocation, UserLocation, CreationTimestamp, etc.
We can use Cassandra, a wide-column datastore to store the relationships between users and photos and the list of people who a user follows. The key for the UserPhoto table would be UserID, and the value would be the list of the PhotoIDs that the user owns, which will be stored in different columns. This pattern will be similar to the UserFollow table.
The photos and videos can be stored in a distributed file storage like HDFS.
Data size estimation
Let’s estimate how much data will be going into each table and how much total storage we will need for 10 years.
User: Assuming each int and dateTime is four bytes, each row in the User’s table will be of 68 bytes:
If we have 500 million users, we will need 32GB of total storage.
Photo: Each row in Photo's table will be of 284 bytes:
If 2M new photos get uploaded every day, we will need 0.5GB of storage for one day:
For 10 years we will need 1.88TB of storage.
UserFollow: Each row in the UserFollow table will consist of 8 bytes. If we have 500 million users and on average each user follows 500 users. We would need 1.82TB of storage for the UserFollow table:
Total space required for all tables for 10 years will be 3.7TB:
Component design
Photo uploads are often a slow process because they go to the disk, whereas reads are much faster. Uploading users will consume all the available connections because of how slow the process is. Thus, reads cannot be served when the system is loaded with write requests. To handle this bottleneck, we can split reads and writes to separate servers so that the system is not overloaded.
This will allow us to optimize each operation efficiently.
Reliability and Redundancy
Because the application emphasizes reliability, we cannot lose any files. So, we will store multiple copies of each photo and video so that even if one server dies, the system can retrieve the media from a copy server.
This design will be applied to the other components of our architecture. We will have multiple copies of the services running in the system so that even if a service dies, the system will remain running. Creating redundancy in the system allows us to create a backup in the midst of a system failure.
Data sharding
One possible scheme for metadata sharding is to partition based on PhotoID.
If we can generate unique PhotoIDs first and then find a shard number through PhotoID % 10, the above problems will have been solved. We would not need to append ShardID with PhotoID in this case as PhotoID will itself be unique throughout the system.
Want to read more about data sharding? Check out our What is data sharding shot to learn the basics.
How can we generate PhotoIDs? Here we cannot have an auto-incrementing sequence in each shard to define PhotoID because we need to know PhotoID first to find the shard where it will be stored. One solution could be that we dedicate a separate database instance to generate auto-incrementing IDs. If our PhotoID can fit into 64 bits, we can define a table containing only a 64 bit ID field. So whenever we would like to add a photo in our system, we can insert a new row in this table and take that ID to be our PhotoID of the new photo.
Wouldn't this key generating DB be a single point of failure? Yes, it would be. A workaround for that could be defining two such databases with one generating even-numbered IDs and the other odd-numbered. For MySQL, the following script can define such sequences:
KeyGeneratingServer1:
auto-increment-increment = 2
auto-increment-offset = 1
KeyGeneratingServer2:
auto-increment-increment = 2
auto-increment-offset = 2
We can put a load balancer in front of both of these databases to Round Robin between them and to deal with downtime. Both these servers could be out of sync with one generating more keys than the other, but this will not cause any issue in our system. We can extend this design by defining separate ID tables for Users, Photo-Comments, or other objects present in our system.
Load balancing
The service would need a large-scale photo delivery system to serve data to the users globally. We could push the content closer to the users using cache servers that are geographically distributed.
Wrapping up and Resources
Well done! Now, you should have a good idea of how to design an application like Instagram and TinyURL. Still, there are many more system design patterns to learn. Want to learn how to create the news feed generation service on Instagram? Check out our Grokking the System Design Interview course.
This course will cover other applications like Dropbox, Facebook Messenger, Twitter, and more! Learn the industry-standards of system design through real-world examples.
Resources
Grokking the System Design Interview (course)
Scalability and System Design for Developers (learning track)
The 7 most important software design patterns: Learn some of the most common design patterns before your next software engineering interview (article).





Top comments (4)
Thanks for the great article!
I just noticed, that there must have happened a a parsing error in your traffic estimates section:
The second formula is not displayed, but instead it says:
_ ParseError: KaTeX parse error: Can't use function '$' in math mode at position 2: _
Thank you for catching this! The error has been fixed
Great article!
Thank you for sharing, great article !