
While I'm developing (or just while I'm commuting to work) I usually love to hear some rock music.
I created some playlists on Spotify, but lately I'm stick to the same playlist, containing my favorite "Indie Rock" songs.
This playlist is made up of more or less 45 songs I discovered through the years in several ways.
Since I was starting to get bored about always listening to the same songs, last weekend I decided to analyze my playlist using Spotify APIs in order to discover insights and hopefully to find some new tunes I could add.
Here's what I did in more or less 300 lines of Python 3 code (boilerplate included).
You can find on github a Jupyter notebook with the code I used.
Setting up the environment
For my analysis I set up a Python 3 virtual environment with the following libraries:
In order to access the Spotify APIs I registered my app and then I provided the spotipy library with the client_id, the client_secret and a redirect url.
Analyzing my playlist tracks
After a first API call to get my playlist id, I got all the tracks of my playlist with another API call along with some basic information like: song id, song name, artist id, artist name, album name, song popularity.
With another API call I got some extra information about the artists in my playlist, like genres and artist_popularity.
Finally with another API call I got some insightful information about my tracks:
- duration_ms: the duration of the track in milliseconds;
- acousticness: describes the acousticness of a song (1 => high confidence the track is acoustic). It ranges from 0 to 1;
- danceability: describes the danceability of a song (1 => high confidence the track is danceable). It ranges from 0 to 1;
- energy: it's a perceptual measure of intensity and activity (e.g. death metal has high energy while classical music has low energy). It ranges from 0 to 1;
- instrumentalness: predicts whether a track contains no vocals (1 => high confidence the track has no vocals). It ranges from 0 to 1;
- liveness: detects the presence of an audience in the recording (1 => high confidence the track is live). It ranges from 0 to 1;
- loudness: detects the overall loudness of a track in decibels. It ranges from -60dB to 0dB;
- valence: describes the musical positiveness conveyed by a track (1 => more positive, 0 => more negative). It ranges from 0 to 1;
- speechiness: detects the presence of spoken words in a track (1 => speech, 0 => non speech, just music). It ranges from 0 to 1;
- key: describes the pitch class notation of the song. It ranges from 0 to 11;
- mode: the modality of a track (0 => minor, 1 => major);
- tempo: the overall estimated tempo of a track in beats per minute (BPM);
- time_signature: An estimated overall time signature of a track (how many beats are in each bar or measure).
The results of all these calls have been put inside Pandas dataframes in order to simplify the data analysis and then merged in a single dataframe using artist IDs and track IDs.
Some values (like song/artist popularity and tempo) have been normalized.
Explorative Data Analysis
After ensuring that the artists in my playlist all contain "Indie Rock" as genre, I saw (using shape, info and describe of the full dataframe) that my playlist consisted of 46 entries, containing all non-null values with these statistics:

Then I created some charts (distplot, countplot, boxplot) using Seaborn:
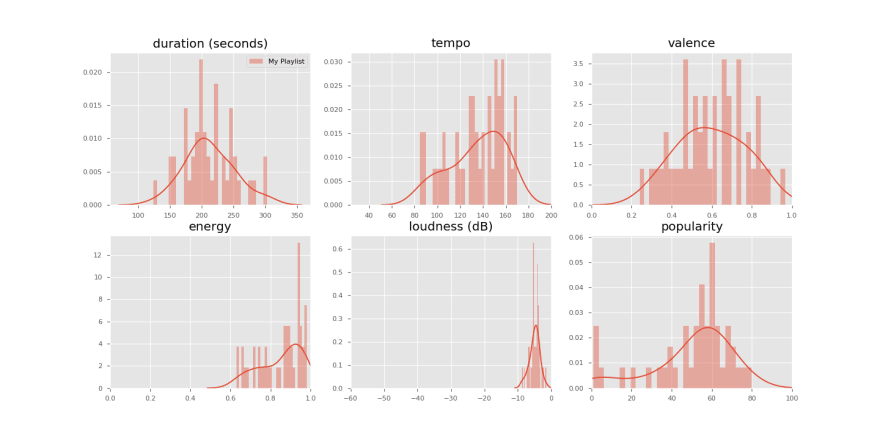

All these graphs show that I like songs with low acousticness/instrumentalness/speechiness, high energy/loudness/tempo, high artist popularity and duration of more or less 200 seconds.
Valence and song popularity span on a wide range, meaning that I have in my playlist both well-known and unknown songs, and both positive and negative ones.
But how my playlist compare against the Indie Rock genre?
Comparing my playlist with a sample of the genre
I used some calls to the search API with 'genre:"Indie Rock"' as a keyword and 'type=tracks' to get a sample of the Indie Rock genre (5000 songs in total).
This API offers also some nice keywords like 'tag:hipster' (to get only albums with the lowest 10% popularity) or 'year:1980-2020' (to get only tracks released in a specific year range).
Then I repeated the same analysis on both my current playlist and the Indie Rock sample and I got the following charts:
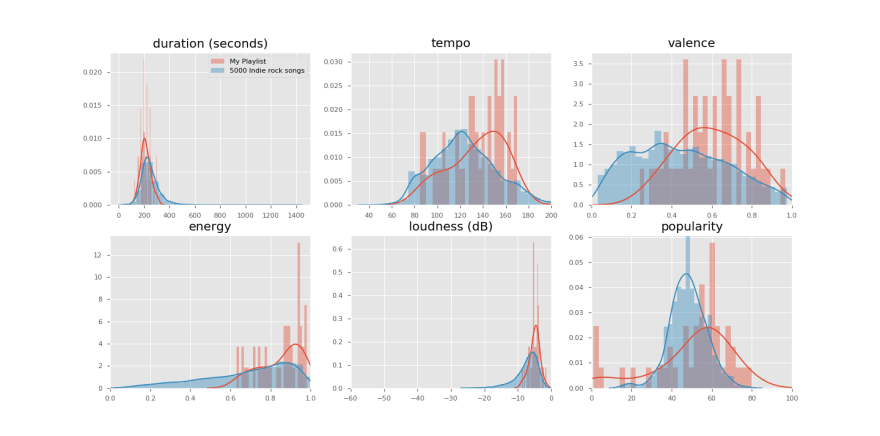
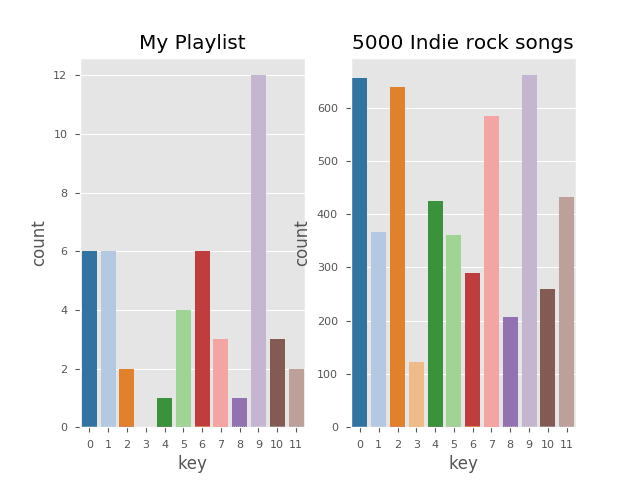
The graphs show that my playlist differs from the 5000 Indie Rock songs because:
- I like shorter songs
- I like songs with higher energy/loudness/tempo
- I don't like songs with too negative mood (valence > 0.3)
- I like songs mostly in key (0, 1, 6, 9)
The boxplot confirms the same insights and I agree with the outcome of this analysis.

Creating a new playlist with songs I potentially like
Using these insights, I applied some filters to the 5000 songs dataframe in order to keep only tracks I potentially like; for each step I logged the dropped songs to double check the filter behavior.
The first filter I applied was removing songs I already had in my original playlist, obviously.
The other filters were:
- acousticness < 0.1
- energy > 0.75
- loudness > -7dB
- valence between 0.3 and 0.9
- tempo > 120
- key in (0, 1, 6, 9)
- duration between 10% quartile of original playlist duration and 90% quartile (178s and 280s)
In the end I got a dataframe with 220 tracks and I created a new playlist using an API call
Conclusions and future steps
After a few days listening to the new playlist, I'm quite happy with the results and I'm already promoting some tracks to my original playlist.
This "recommendation" method is really simple and probably works well only in this specific use case (i.e. it's a well definable subset of a specific genre).
The standard recommendation method of Spotify is obviously much better because, apart from audio analysis, it uses also a mix of Collaborative Filtering models (analyzing your behavior and others’ behavior) and Natural Language Processing (NLP) models (analyzing text of the songs).
Next steps:
- Run the analysis again after a few months, in order to take into account new entries in my playlist and new songs in the 5000 sample
- Enrich the information I already got with something new using the Spotify APIs (e.g the Audio Analysis endpoint or other services. It would be nice, as an example, to detect musical instruments in a track (guitars anyone??) or the presence of some features like distortion, riffs, etc.
- Use the preview sample from the API to tag manually what I like/dislike on a subset of the 5000 songs and then run some ML algorithms in order to classify the music I like
- Analyze deeper my playlist using some ML algorithms (e.g. cluster my tracks)





Top comments (23)
Will you post this code on GitHub? I would like to test it against my own playlist :)
Hi Roger, I uploaded on github a Jupyter notebook:
github.com/eric-bonfadini/python-n...
I didn't realise Spotify has such an awesomely detailed API - you've put it to great use here Eric!
Just as an aside for anyone that likes the idea of tracking their music listening habits without writing code, there's a really cool service called last.fm (it's not as detailed as Eric's above analysis however)
The title of this post does not do justice to its awesomeness.
Thanx a lot Ben!
I even spent quite some time in finding a good title, but, after all, developers are not good in naming things! :-D
It's a very interesting concept. I make video tutorials for Packt Publishing. Would you be interested in discussing making a course?
Would be a great opportunity to showcase some of your awesome skills with Python.
Nice one! This is something I always had in mind but never got it done. I like the approach to use charts for visualization!
Also good that you linked the API documentations, makes it easier to implement the calls (saves some time on research).
Thanks for the post!
Super dooper nice! I like Pandas, too, and the ease it gives you for data analysis. If it comes to music I am also big fan of it so I will surely take a closer look to Spotify API.
BTW, why didn't you use pandas built-in charting capabilities? Was seaborn really needed here?
I usually like Pandas built-in capabilities for quick plots while I'm exploring data (therefore Seaborn wasn't strictly needed here).
Anyway I really love the APIs, configurations and plots offered by Seaborn, along with its simplicity and Pandas integration.
This is really awesome, dude.
Do you think it could be used to generate a playlist based on an analysis of multiple people to get a playlist with common interests between them?
It could help with some problems i've seen in parties.
Really liked this, i'm going to reread it later.
Awesome article :)
Im dipping my toes into data science for the first time since i took my intro class, but never could find a project that was interesting to do + scoped to my capabilities.
Ive created a programming music playlist and have set up the spotify api to get the track info.
Now the only part left is the data science analysis, so excited to tackle that today.
Playlist for anyone whos interested in Classical/Video Game music :
open.spotify.com/user/1250987938/p...
Hopefully the data is all in the same genre.
I knew Spotify has an API. I didn't know it could do "Tell me about the song", but considering the "Year in Music" stuff, I suppose I should.
I have Last.FM data going back almost a decade (I could've used the API, for which I have a key, but instead I used this web-based tool), and I could see adding "100 Most-Played Tracks in 2011" and the like, and tracking how often I played my favorites, but really, the "This is what a Fave Song looks like; give me more" is much more interesting.
I will have to dive into the APIs and your code.
But where is the fun in that? :)
dude, this post was awesome!
nice to know the detailed API Spotify has
Awesome idea ! Looks fun :)
This is absolutely wonderful Eric! Thanks for sharing.
And how are you gonna get anything similar with a YouTube search?
Awesome article.
@walker , I think you'll really enjoy reading this one.