DynamoDB is a key-value store and document database managed by Amazon Web Services (AWS). Usually, we use it when implementing a caching layer or an application with a simple data-model that uses key-value lookups to fetch data. The next couple of paragraphs walk you through some strategies and patterns to use DynamoDB to store your relational data.
Here is a quote that can be seen on the Amazon DynamoDB page.
Amazon DynamoDB is a key-value and document database that delivers single-digit millisecond performance at any scale. It’s a fully managed, multiregion, multimaster, durable database with built-in security, backup and restore, and in-memory caching for internet-scale applications. DynamoDB can handle more than 10 trillion requests per day and can support peaks of more than 20 million requests per second.
Since the pressure on data storage doesn’t increase overnight, the performance of DynamoDB at scale wasn’t the major selling point to use it.
However, I started considering DynamoDB due to the benefits associated with serverless architecture:
- Simple provisioning;
- Pay-per-use pricing;
- and, a straightforward connections to a database (no connection pools).
The rising curiosity led me to research more about DynamoDB and learn about the patterns and strategies you can use for a wide variety of use-cases. Overall, what contributed to a change of mind regarding this AWS service was the single-table design concept, a way to represent multiple entities and model a relational model.
Single-table design
As an example, let’s model an application where a user can write content and others can like it. An essential part of the process is to understand the data access patterns and the entities of your application as they are the primary resources to decide how to shape our data.
Data Access Patterns
- Create a post (organised by topic)
- User can like a post (one like per user)
- List the posts on a topic with the total number of likes
- View user and liked posts
Entities
Our application has topics, posts, users and likes.

Before we start to model our data access patterns and entities to our table, we need to know how to access data on DynamoDB. In DynamoDB to retrieve items from a table:
- You can get an item;
- You can query items;
- Or, you can scan every item on a table.
Let’s start by modelling the topic and their one-to-many relationship with posts. Unlike an SQL database, there is no way to join data from multiple tables. Still, there are multiple strategies to model one-to-many relationships being one of them, the one that we use, pre-joining your data into item collections.
Pre-join your data
To pre-join our data we use a composite primary key in our table (a composite primary key combines a partition key and a sort key).
In our case the partition key (PK) and sort key (SK) of topics and posts looks like this:
Note: A ksuid creates a sortable unique identifier.
We can use the topic PK and the query API to get a collection of items with the topic and the related posts.
The previous query returns the item collection highlighted in the image.
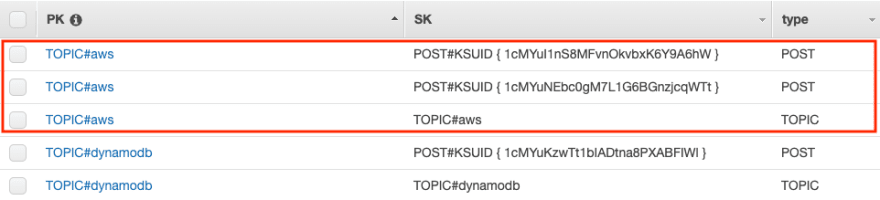
Note: Notice the existence of a type attribute on every item. The attribute makes our life easier when reading data or when we execute ETL tasks.
We can model the relationship between users and likes the same way we did for topics and posts to cover the “users can like posts” and ”view user and liked posts” access pattern. We use the same PK and SK to model this relationship.
There is, however, another access pattern related to likes, “list the posts on a topic with the total number of likes” that we need to model. We can’t use the item collection strategy because likes are in the users’ item collection, and posts are in the topics item collection (even if we could, scanning every item and count them isn’t optimal).
In a relational database, you solve this joining multiple tables and counting the likes regarding a particular post, in DynamoDB doing a scan to get this information is a no-go due to the told on performance (as your application scales, it gets slower) and in your wallet. The solution is to optimize your reads and keep a counter on the posts using a DynamoDB transaction.
Transactions in DynamoDB
DynamoDB provides an API to create transaction when reading and writing items to your table. In our case we use a transaction when writing a like to a post:
- Put a like item ensuring it’s not a duplicate;
- Increment the number of likes in the post.
With the previous snippet, every post has a counter with the number of likes on an item attribute available with every post. By using a small number of strategies and patterns, we were able to model a relational database into DynamoDB.
Let’s add one more access pattern so I can introduce you to another pattern and unlock new possibilities:
- View a post and list the users that liked it
We already overloaded our primary key, so we can’t use it to reflect this access pattern, although we can use a global secondary index.
Global Secondary Index
Global secondary indexes allow us to define new access patterns using a completely different key structure. In our case, we use a secondary index to create an item collection around our post and likes. Remember, we can set the same partition key, ensuring we retrieve the related item when using the query API.
Note: We prefix our global secondary index (GSI) and give it a number to better identify them.
To query the data we specify the index name and the partition key. The snippet below return an item collection related to the post we want to fetch.

Recap
Let’s recap our composite keys for our entities.
Entity convention for primary key and global secondary index.
Note: It’s an excellent practice to document how we map each entity into our indexes for future reference.
To model a relational model into DynamoDB and take advantage of its performance at scale:
- We used a single-table design with a composite primary key;
- We pre-joined our data into item collection so we could query related information;
- We used transaction to ensure our entities had relevant counters;
- We used global secondary indexes to query our data to fit different access patterns.
Our table can be created with the following snippet. Notice that we define every attribute we want to be part of the indexes but separate the key schema into different parts of the creation request.
Final Thoughts
In this post, we just scratched the tip of the iceberg about DynamoDB but in case you are using a serverless architecture, an event-driven architecture, a micro-service architecture, or a macro-service architecture consider DynamoDB in your next application. Consider using DynamoDB in one of the domains of your application, create defined boundaries and you can model one per table to keep them decoupled.
Some people raise concerns about vendor lock-in, but, is it even a real problem? Most of us rely on what we know to overcome the problem we are facing. If we are already using and invested in Amazon Web Services, the fear of lock-in shouldn’t be the reason for not giving a try to DynamoDB. If DynamoDB is a tool that allows us to deliver value and have an application live, let’s use it.
DynamoDB doesn’t clear you from knowing the entities of your application and the access patterns to fetch the data, but with the right patterns, you can have a fast and scalable database without the management burden and cost.





Top comments (3)
Nice article, but I'm a bit confused about the last access pattern (getting the users that liked a post):
wouldn't we have to update the transaction code that creates the like to also add a new item (POST#, LIKEPOST#) with the GSI1PK and GSI1SK fields?
Yes, I haven't included the attribute properties when
Puting an object.On the
Itemproperty we would need to specify the attributes for the different types.In the case of a Post:
And for the Like:
In case you already have items on your table you need a migration.
Depending on your use case:
brilliant, thanks :)