
I briefly introduced Range() in a previous article and, as promised, we're going to take a deeper look at it today.
This series assumes that you have a grasp on the basics. If you're new to FaunaDB and/or FQL here's my introductory series on FQL.
In this article:
- Introduction to range queries
- Multi-items boundaries
- Range and then filter
- Index and then range
- Combine indexes
- Range with index bindings
Introduction to range queries
The idea of range queries is to be able to filter results by providing two boundaries, expressed as start and end values. Since FaunaDB needs to be able to compare values to determine when a result should be included, these boundaries have to be scalar values such as numbers, strings, or dates, but not other FQL types such as booleans.
Let's create some data to see how Range() works:
> CreateCollection({
name: "Alphabet"
})
And let's add some documents with a Map() :
> Map(
[
{leter: "A", position: 1},
{leter: "B", position: 2},
{leter: "C", position: 3},
{leter: "D", position: 4},
{leter: "E", position: 5},
{leter: "F", position: 6},
{leter: "G", position: 7},
{leter: "H", position: 8},
{leter: "I", position: 9},
{leter: "J", position: 10}
],
Lambda(
"data",
Create(
Collection("Alphabet"),
{data: Var("data")}
)
)
)
We're also going to need an index to be able to query our documents:
> CreateIndex({
name: "Alphabet_by_letter_position",
source: Collection("Alphabet"),
values: [
{field: ['data', 'letter']},
{field: ['data', 'position']}
]
})
Do note that we've configured the index to return some values. Range() needs those values to be able to compare them with the boundaries. Check the CreateIndex() docs for more info on the values field.
By default, this is what our index returns:
> Paginate(Match(Index("Alphabet_by_letter_position")))
{
data: [
["A", 1],
["B", 2],
["C", 3],
["D", 4],
["E", 5],
["F", 6],
["G", 7],
["H", 8],
["I", 9],
["J", 10]
]
}
We're now ready to make our first range query. For each boundary, Range() accepts either a single scalar value or an array. Let's use these the single values of A and E for now:
> Paginate(
Range(
Match(Index("Alphabet_by_letter_position")),
"A",
"E"
)
)
{
data: [
["A", 1],
["B", 2],
["C", 3],
["D", 4],
["E", 5]
]
}
As we can see, Range() has filtered the results that fall within the defined boundaries by comparing the start and end values with the first item of each result.

Because the string "A" is superior or equal to the start value of "A" then ["A", 1] is included in the results. Likewise, because the string "F" is superior to the end value of "E" then ["F", 6] is not included in the results.
Instead of a single value for the boundaries, we could also use an array with a single item. The result would be the same:
> Paginate(
Range(
Match(Index("Alphabet_by_letter_position")),
["A"],
["E"]
)
)
{
data: [
["A", 1],
["B", 2],
["C", 3],
["D", 4],
["E", 5]
]
}
It's also possible to use an empty array to tell FaunaDB to use the first or last result as start or end values, respectively, for the boundaries. In this case we'll get everything between the first result up to "C":
> Paginate(
Range(
Match(Index("Alphabet_by_letter_position")),
[],
"C"
)
)
{
data: [
["A", 1],
["B", 2],
["C", 3]
]
}
Multi-item boundaries
An interesting aspect of Range() is that we can use an array with multiple values for our boundaries. The results might not be what you're expecting though!
See this example:
> Paginate(
Range(
Match(Index("Alphabet_by_letter_position")),
["A", 3],
["G", 4]
)
)
{
data: [
["B", 2],
["C", 3],
["D", 4],
["E", 5],
["F", 6]
]
}
The first time I ran that query I was confused since I expected each item in the start/end arrays to act as its own range filter, so to speak, but that's not how Range() works.
Each start/end array is actually used as a single value to determine which results are superior or inferior.
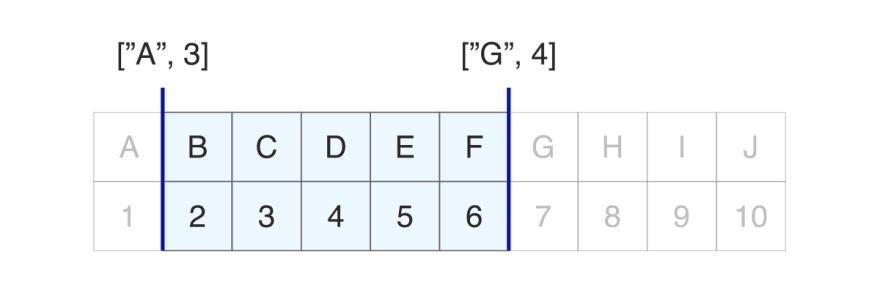
As you can see, FaunaDB considers ["F", 6] to be inferior to the upper limit of ["G", 4], but how does that work?
Think of it this way. If you were sorting strings alphabetically, which one would come first: "A8" or "Z1"? Obviously "A8" because A comes before Z, right? Since the first character has the highest priority when sorting we don't care about the second one to determine which string comes first.
This also explains why FaunaDB considers ["G", 7] to be superior to ["G", 4] and excludes it from the results. The first item is the same (the string "G") so only the second item affects the comparison.
Let's see another example. Imagine we had a collection of people with their age and name and we had an index that returned these results:
> Paginate(Match(Index("People_by_age_name")))
{
data: [
[27, "Alex"],
[33, "Abigail"],
[39, "Adam"],
[41, "Pier"],
[50, "Anna"],
[64, "Charles"]
]
}
If we now wanted to get all the people between 30 and 60 we could execute the following query:
> Paginate(
Range(
Match(Index("People_by_age_name")),
30, 60
)
)
{
data: [
[33, "Abigail"],
[39, "Adam"],
[41, "Pier"],
[50, "Anna"]
]
}
So far so good.
What if we now wanted to refine those results and get the names between A and B?
We wouldn't be able to use Range() to solve this for the reasons I explained before:
> Paginate(
Range(
Match(Index("People_by_age_name")),
[30, "A"],
[60, "B"]
)
)
{
data: [
[33, "Abigail"],
[39, "Adam"],
[41, "Pier"],
[50, "Anna"]
]
}
Even though the string "Pier" obviously comes after the string "B", FaunaDB is only taking the age into consideration to determine that [41, "Pier"] is inferior to the upper bound of [60, "B"].

Range and then filter
So how would we actually get all the people between 30 and 60 but also with names between "A" and "B"?
The solution is to simply iterate over the results of Range() and then express any needed condition using FQL:
> Paginate(
Filter(
Range(
Match(Index("People_by_age_name")),
[30],
[60]
),
Lambda(
["age", "name"],
And(
GTE(Var("name"), "A"),
LTE(Var("name"), "B"),
)
)
)
)
{
data: [
[33, "Abigail"],
[39, "Adam"],
[50, "Anna"]
]
}
Here we're using GTE() (greater than or equal) and LTE() (less than or equal) to compare the name and making sure both conditions return true with And().
We could refine this query even further by, for example, only listing people that also have an "n" or an "i" in their names:
> Paginate(
Filter(
Range(
Match(Index("People_by_age_name")),
[30],
[60]
),
Lambda(
["age", "name"],
And(
GTE(Var("name"), "A"),
LTE(Var("name"), "B"),
Or(
ContainsStr(Var("name"), "n"),
ContainsStr(Var("name"), "i")
)
)
)
)
)
{
data: [
[33, "Abigail"],
[50, "Anna"]
]
}
ContainsStr() will return true when a string contains the string defined in its second parameter, in this case an "n" or an "i".
These conditions can be as complex as you need them, we're really just scratching the surface. Here are some useful FQL functions you should check out to compare values and express conditions:
- And()
- Any()
- Or()
- Equal()
- GT() (greater than)
- GTE() (greater than or equal)
- LT() (less than)
- LTE() (less than or equal)
- ContainsStr()
- ContainsStrRegex()
- ContainsValue()
Index and then range
So far, in this article we've only used indexes that return all of the documents in a collection and then filtered those results using Range(). We can of course use indexes with terms that already select a number of documents before filtering with a range.
Let's create a new collection:
> CreateCollection({
name: "RobotRepairs"
})
And an index that allows us to filter by type and also provide the necessary terms to be able to use Range() :
> CreateIndex({
name: "RobotRepairs_startTs_endTs_type_by_type",
source: Collection("RobotRepairs"),
values: [
{field: ["data", "startTs"]},
{field: ["data", "endTs"]},
{field: ["data", "type"]},
{field: ["ref"]}
],
terms: [
{field: ["data", "type"]}
]
})
Now, let's also insert a couple of documents with this format:
> Create(
Collection("RobotRepairs"),
{
data: {
startTs: Time("2020-09-25T10:00:00Z"),
endTs: Time("2020-09-27T18:00:00Z"),
type: "CPU_REPLACE"
}
}
)
This is what this index returns when filtering by "CPU_REPLACE" :
> Paginate(
Match(
Index("RobotRepairs_startTs_endTs_type_by_type"),
"CPU_REPLACE"
)
)
{
data: [
[
Time("2020-09-22T11:00:00Z"),
Time("2020-09-23T13:00:00Z"),
"CPU_REPLACE",
Ref(Collection("RobotRepairs"), "278203011981902355")
],
[
Time("2020-09-25T10:00:00Z"),
Time("2020-09-27T18:00:00Z"),
"CPU_REPLACE",
Ref(Collection("RobotRepairs"), "278203042867708435")
],
[
Time("2020-10-01T17:00:00Z"),
Time("2020-10-01T19:00:00Z"),
"CPU_REPLACE",
Ref(Collection("RobotRepairs"), "278202807195009555")
]
]
}
So now, we could first filter by repair type, and then use Range() to only get the repairs done between two timestamps:
> Paginate(
Range(
Match(
Index("RobotRepairs_startTs_endTs_type_by_type"),
"CPU_REPLACE"
),
[
Time("2020-10-01T00:00:00Z"),
Time("2020-10-01T00:00:00Z")
],
[
Time("2020-10-02T00:00:00Z"),
Time("2020-10-02T00:00:00Z")
]
)
)
{
data: [
[
Time("2020-10-01T17:00:00Z"),
Time("2020-10-01T19:00:00Z"),
"CPU_REPLACE",
Ref(Collection("RobotRepairs"), "278202807195009555")
]
]
}
To get actual documents instead of arrays with values, we'd need to use Map() with Lambda() and Get() :
> Map(
Paginate(
Range(
Match(
Index("RobotRepairs_startTs_endTs_type_by_type"),
"CPU_REPLACE"
),
[
Time("2020-10-01T00:00:00Z"),
Time("2020-10-01T00:00:00Z")
],
[
Time("2020-10-02T00:00:00Z"),
Time("2020-10-02T00:00:00Z")
]
)
),
Lambda(
["startTs", "endTs", "type", "ref"],
Get(Var("ref"))
)
)
{
data: [
{
ref: Ref(Collection("RobotRepairs"), "278202807195009555"),
ts: 1601580160340000,
data: {
startTs: Time("2020-10-01T17:00:00Z"),
endTs: Time("2020-10-01T19:00:00Z"),
type: "CPU_REPLACE"
}
}
]
}
Range with index bindings
In a previous article, we learned about index bindings, which are pre-computed values on index results.
Let's create a new index, that returns the duration of each repair, using a binding for a particular repair type:
> CreateIndex({
name: "RobotRepairs_duration_type_by_type",
source: {
collection: Collection("RobotRepairs"),
fields: {
durationMinutes: Query(
Lambda("doc",
TimeDiff(
Select(["data", "startTs"], Var("doc")),
Select(["data", "endTs"], Var("doc")),
"minutes"
)
)
)
}
},
values: [
{binding: "durationMinutes"},
{field: ["data", "type"]},
{field: ["ref"]}
],
terms: [
{field: ["data", "type"]}
]
})
This is what this index returns by default:
> Paginate(
Match(
Index("RobotRepairs_duration_type_by_type"),
"CPU_REPLACE"
)
)
{
data: [
[
120,
"CPU_REPLACE",
Ref(Collection("RobotRepairs"), "278202807195009555")
],
[
1560,
"CPU_REPLACE",
Ref(Collection("RobotRepairs"), "278203011981902355")
],
[
3360,
"CPU_REPLACE",
Ref(Collection("RobotRepairs"), "278203042867708435")
]
]
}
We could now use Range() to only get the repairs that lasted less than 1 day (or 1,440 minutes):
> Paginate(
Range(
Match(Index("RobotRepairs_duration_type_by_type"), "CPU_REPLACE"),
[],
[1440]
)
)
{
data: [
[
120,
"CPU_REPLACE",
Ref(Collection("RobotRepairs"), "278202807195009555")]
]
}
Conclusion
So that's it for today. Hopefully you learned something valuable!
If you have any questions don't hesitate to hit me up on Twitter: @pierb





Top comments (1)
Looking for best curtains and blinds in newzealand, here I’ll introduced you Gargi home furnishings. We are based in New Zealand and home is your living place,we understand the importance of the look of a home, curtains and blinds play a important role in home decor.That's why you can get our top quality services at an affordable price. We offer a wide range of curtains and blinds at Gargi Home Furnishings including automated curtains and blinds.