
“SQL, Lisp, and Haskell are the only programming languages that I’ve seen where one spends more time thinking than typing.“ — Philip Greenspun
Even with thinking more than typing SQL (Structured Query Language) we software engineers use it as a way to pull data only.
We usually don’t leverage SQL’s power of data manipulation and do the needed changes in code.
This is quite prevalent in software engineers who work in web applications. Another thing we miss is, if we do the manipulation in SQL directly the pulled data will be the same format for any programming language. This post aims to enlighten you about the powers of SQL you might know but generally don’t use.
](https://res.cloudinary.com/practicaldev/image/fetch/s--v3BpngoC--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1.medium.com/max/2000/0%2A5TyHwM3Q_6HSA4In.jpg) Tea Lights image from Pixabay
Tea Lights image from Pixabay
TLDR;
Use SQL to do math like sum, average etc. Utilize it for grouping one to many relational values like getting categories of product. Leverage SQL for string manipulation like using CONCAT_WS for concating first name and last name. Exploit SQL to sort by a custom priority formula. Examples below…
The Example
It will be easier to explain the superpowers of SQL putting it in action on an example. Below is a basic schema with 2 tables in MYSQL for a refunds microservice:
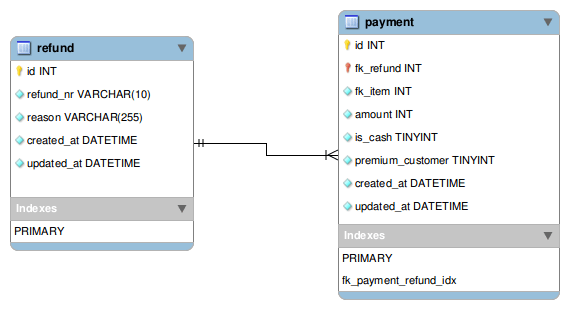
There are 2 refunds and 7 related payments as example data.
Some assumptions
For the refunds microservice example schema and applications following assumptions are made:
Refunds microservice and data structure store the fk_item (the id of the ordered/delivered item), but it is not a hard foreign key.
Item can be refunded in either cash or credit for the amount paid for the same.
Items can be refunded many times as long as remaining balance can cover requested refund amount for each cash and credit. For example, item was paid 50 in cash and 50 in credit. 2 refunds of 20 cash and 20 credit can be done. So after these transactions balance will be 10 cash and 10 credit for that item (50–20–20).
Each refund can have multiple items payment. Each payment can be of type either cash or credit.
All amounts are stored in cents so they are integers.
Now let’s use some SQL powers. You can find the example with related queries running on SQL Fiddle.
Do the math in SQL
As software engineers, let’s say if we need to find the total cash and credit amount refunded for an item what would we do? We would run something like:
SELECT fk_item, fk_refund, amount, is_cash
FROM payment WHERE fk_item=2001;
With current data, it will give 3 rows like below:
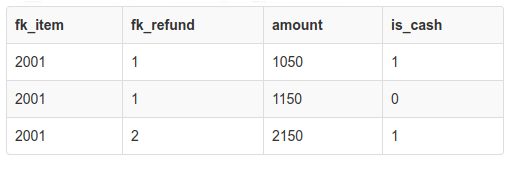
With these 3 rows, we would loop over them. If it is cash accumulate it to cashBalance variable, if not sum it up to creditBalace variable. Rather than that it would be a lot easier (probably faster) to do in SQL like:
SELECT fk_item, SUM(amount) AS total_paid, IF(is_cash = 1, 'cash', 'credit') as type
FROM payment WHERE fk_item = 2001 GROUP BY fk_item, is_cash;
Resulting in:
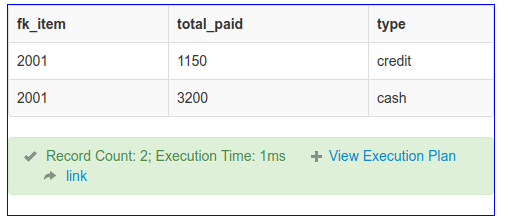
The result is easy now if you need the total refund for the item just change the GROUP BY to be on fk_item and it’s done. For 2 and 3 records it won’t feel significant. If there were say 20 refunds for that item, the first solution with a loop is writing more code with no gain. Like sum, other SQL functions can be used too. Simple math operations like sum, multiply, average etc can be easy with SQL. This means no more loops.
Use GROUP_CONCAT to fetch related 1:m relation values
Group concat is a robust operation in SQL databases. It is instrumental when you need to get data from one to many relationship. For instance, you want to get all tags for a blog post or you want to get all categories of a product. Concerning this refunds example, one item can be refunded multiple times. So we will get all the refunds associated with the item id. To get this we will run only 1 query and get it without any loops in the code like below:
SELECT fk_item, GROUP_CONCAT(DISTINCT fk_refund) refund_ids
FROM payment WHERE fk_item = 2001;
This results in:
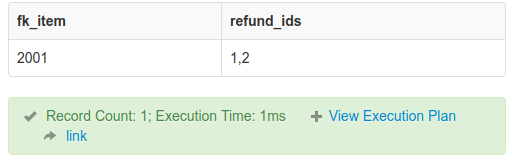
Now we know that item 2001 has been refunded twice for 2 refunds. It will be easy to explode the refund Ids with , and proceed with any related operation.
String manipulation
Many string manipulation tasks like substring, concatenation, change case, and string compare can be done in SQL. With this example, I am going to show the usage of CONCAT_WS. It is concat with a separator. It can also be used to select for instance first_name and last_name with space in between.
In case of having an optional middle name COALESCE can be used with CONCAT_WS. That is something for you to explore :).
In this example, I will select refund_nr with its related reason:
SELECT CONCAT_WS("-", refund_nr, reason) AS refund_nr_with_reason
FROM refund;
Resulting in:
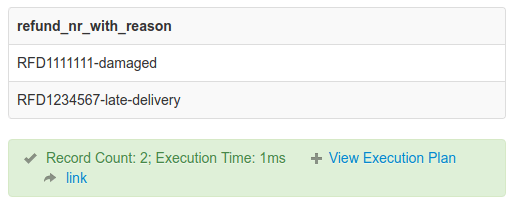
If this needs to be shown on the credit note document, for example, no extra code is needed to join the values again. SQL makes it one step easier again.
Sorting with a custom formula
All software engineers know you can sort based on a column. But if you are given a custom priority formula to sort, what would you do? Probably again resort back to code and loop to sort. So lets set the priority formula rules for above example:
Premium customer refunds get the highest priority (we hack it with a priority of 9999999999)
Other than premium customers cash refunds get a priority of amount * 25 for credit it is amount * 20.
As per above rules it is decided that premium customers and priority above 50000 (in cents) will be processed first. Then other refunds will be processes. Let’s get the priority refunds as below:
SELECT r.refund_nr, r.reason, p.fk_item, p.amount, p.is_cash,
IF(p.premium_customer = 1, 9999999999, p.amount * (IF(is_cash = 1, 25, 20))) AS priority
FROM refund AS r INNER JOIN payment AS p ON r.id = p.fk_refund
HAVING priority > 50000
ORDER BY priority DESC
The results are below:
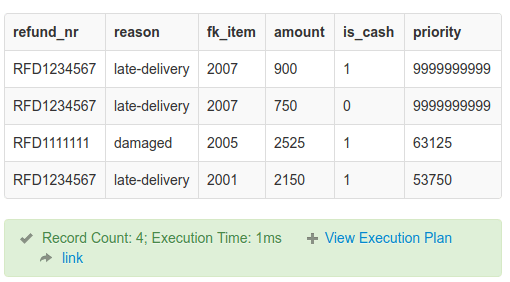
With proper use of IF in SQL sorting by a custom priority formula is a lot easier than trying to do it with loops in code. Notice that even smaller amounts like 7.5 (750 cents) and 9.0 (900 cents) came to highest priority as these refund payment amounts were associated with premium customers.
Use the superpowers of SQL to make your life easier as a software engineer.
You can play with the example and run your queries on SQL fiddle.
Conclusion
There are other tricks of SQL that can help you as a software engineer. Like, UPDATE with INSERT using ON DUPLICATE KEY UPDATE. Whenever you have an itch of doing some manipulation for data pulled in from database in code with loops, think again. The main takeaway from this story is:
Exploit the power of SQL to write less code because “the best code is the code that was never written”. If it is not written there is no need to maintain it.
Originally published at geshan.com.np.





Top comments (100)
Putting application logic into DB scope might end up with hard to maintain and troubleshoot code, though I can agree sometimes knowledge of SQL help you getting things done, but I'd leave this approach for custom reports based on SQL queries rather than for web application or something when you are free to process data in controller level.
Company I work for has exactly this issue. Literally all the logic (sometimes even presentational logic) is done in the database.
This is nightmare to maintain and now really difficult to refactor.
Also it's difficult to test SQL code due to lack of tools.
Probably as most of you agree it is a bad practice due to:
It is better to convenience the devs and mgmt to slowly move it out if possible.
First one is not true.
We successfully version database code using Git, have working pull requests, continuous integration and delivery.
Second is not true as well. For instance, T-SQL code can be tested using tSQLt framework. Yet again. This is more difficult and not a widely adopted practice, but it's possible and companies do it.
But in any case. Even though things are possible and can be done in database, it doesn't mean it should be.
Database testing is a nightmare I hope to never repeat. Just because a thing can be done do not mean that it should be done.
It's not true in anyway that DB code is hard to test. As long as the person is aware of DB based code units it's just the same.
Maybe you are right!
Thanks for the comment. I am not advocating putting any logic in DB. The code still stays in your git repo. I am just trying to demonstrate the power of SQL for simple tasks can be a lifesaver.
Not only that, but imagine wanting to move to a different database that doesn't have this features. Anyway, is sql a programming language?
I have never seen a company moving to another database. This is something that just does not happen.
I hope you're being sarcastic.
In case you aren't:
Why Uber Engineering Switched from Postgres to MySQL
Why we Moved From NoSQL MongoDB to PostgreSQL
From my mobile experience there is Parse who burned its developers 2 years ago. My personal app is still not working because i could not replicate in Firebase the query based on location coordinates. Since then i learned to use clean code and the database is switchable whenever i wish. I do have one right now where an iOS, Mac and command line app use the same codebase but different databases.
Of course, if you have something highly important no need to worry about this and better to implement how is more efficient.
Some things to keep in mind.
Depending on the SQL logic, this could add additional CPU resource pressure on the database server, a service that is hard to scale. Web servers are significantly easier to scale to handle the processing workload.
At least one of the examples looks like it may break the SQL query optimizer in MySQL or MariaDB, causes a full table scan, significantly harming performance. If tables are small, this is no issue, but even for small business workloads, I'm generally dealing with tables on the scale of 1mil to 100mil rows.
Others have noted that this could make parts of the database harder to maintain. Personally, I use some of these methods described above, but they're handled through a SQL query generator, the logic still entirely exists in the application layer, it simply generates and then passes the required SQL query string to the database to handle the operations.
I simply make these notes as someone who has crafted web sites with data processing times in the sub-100ms range, with the fastest now averaging 6ms.
You'll always want to keep in mind how your application is deployed and where you have the most resources.
One application I worked on was deployed on a provider with a pricing model where you paid for web server instances but the database itself was bundled in as part of the package. This lead to a design that off-loaded as much as possible onto the database as it was basically "free" compute. The database instance was far, far faster than any of the individual web servers.
In modern configurations you're going to have a lot of web instances and a few databases that you want to keep lightly loaded so they're responsive. This is especially true if leaning hard on your database means buying more ultra-expensive database server licenses.
It is a balance of trade-offs as it is usually in distributed systems. Choosing the right trade-off is one of the keys to success in our field.
If the concern is scalability of the database, as counter intuitive as it might sound, doing more work outside the database can make the database work harder then if that work was done inside the database.
This is not just an idle rant - here's a full exploration of that precise topic
youtube.com/watch?v=8jiJDflpw4Y
I like your point of view, databases are not easily scalable that's where managed services with load balancers come into play I suppose. About the full table scan, this is an example and setting indexes correctly would help tackle the problem. One can always run an
EXPLAINand plan next steps.About maintenance, I believe none of the code should be in the DB itself it should be in git managed repos. I am also not promoting writing triggers or unnecessary views. 6ms is impressive, at that point there should be a good amount of caching involved. Thanks!
6ms is with zero caching, that's all live database queries and html template processing.
The query in question about the SQL optimizer is the one with the HAVING statement. I'd have to check, but limiting the number of rows in a HAVING statement based on an IF statement in the column selector I believe requires a full table scan. The GROUP BY statements should all be good though, especially considering the advances in optimizing these in the past two years.
Sounds interesting for 6 ms.
For the having query it was just an elaborated example, if it was a real DB query I would have surely run an explain to see if that is the way to go. Thanks!
I find the unwillingness to properly leverage the power of the database very confusing. It's like having a firetruck with big, powerful hoses that you drive up to the fire and then use those hoses to fill little individual buckets that you carry over to throw on the fire one at a time :(
I have constant conversations with (mostly) younger devs who seem unwilling to learn some database design theory and some SQL that could save them huge amounts of messing about with ORMs.
Amazing analogy!
Well said :-)
Window functions are my favorite "hidden" super power. The intro of the linked article says it all:
Oh my lord, pagination.
I am so profoundly shocked by the concept of pagination I'm litterally SHYDDING MAISELF right now.
Not exactly Mihail, pagination is what you do with
LIMITandOFFSET, and has been there since forever.Window functions are useful to correlate different rows and building charts or leaderboard, giving them weights, using them as a state machine (since it's a rolling window you can know which row is "previous") and other stuff.
You can obviously do that all of that stuff using a programming language (and sometimes you should) but if you don't need to, why not use them ;) ?
No, I get it, I see how it is both useful and how it might be obscure even to those that write some SQL.
I was just making fun of the hyped up description.
I'm also in the camp that says SQL is over used. The two popular and malignant ways it's overused is when one DB is shared between many if not all microservices (regardless of how well written the stored procedures are), and ORMs when used mixed with procedural app code and not as query builders.
SQL can be an acceptable structured datastore (with logic) for a given service, alone or together with other sources of truth. But not every service would benefit from one of those.
But most importantly, it's a poor object store and an even worse inter-service communication channel. And I've seen it used as both a lot.
It took me a while to get it but I was actually writing a basic leaderboard and all of the "in language" solutions I tried were dog slow. Window functions instead use indexes :)
I don't know, it really depends on too many factors.
Eh eh yeah, say no to stored procedures 99.99% of the time. The only placed I worked at where we had those was at a financial company and they used procedures written in Python that did math calculations inside the DB. A mess to maintain but insanely fast.
Say no to microservices that synchronize through a shared DB. That's a distributed monolith :D
I meant stored procedures in SQL itself.
CREATE PROCEDURE.Yeah, let's avoid stored procedures if we can. Agreed
Not sure of this.
Ah ah I think it's just a hyperbole, but they really are useful
I hope they are! :)
They are, you can do a long way to calculate base statistics or setup things like leaderboards where you give rows scores based on some columns
Are we going to state the obvious elephant in the room? Going through the comments it's obvious that many developers do not know about SQL or databases in general. Its why they are getting in their feelings. The problem isn't the SQL code, it's probably because you don't understand the underlying data structure or know SQL well enough.
Putting application logic in SQL is good practice in my opinion. Maybe not all logic, but at least a good chunk. This makes your application faster and scale well. Adding more application servers would not make it faster or scale well for that matter. Understanding the underlying database and data structure would go a long way in scaling that application.
As for testing it's possible to test SQL code. I haven't seen people do autonomous testing of SQL code, but it's possible.
Agreed. Perhaps the biggest obstacle to any technology (SQL included) is rarely the technology itself, but people's comfort factor with it.
I'm just as guilty of that myself. I know that the best applications use database access (SQL) intelligently, they use middle tier functionality intelligently, and client tier functionality intelligently. But most apps have a strong bias in just one of these areas, simply because of the biases of the developer/development team involved.
Thanks for your viewpoint!
Well articulated and I share the same view.
Primary reason not to do SQL was SQL Injection and wrong way devs write SQL. That's why we shifted out from SQL to ORM, but for high performance queries, we ended up doing that in SQL. This creates testing nightmare.
You can use database wrappers rather than full ORMs. They let you to write queries in your programming language and then “translate it”” into the native db syntax. Elixir Ecto is an excellent example of this technique (or at least, the best I know of). I prefer this to, for example, Ruby’s ActiveRecord/ActiveModel.
My 2 cents
You can call database wrapper or full ORMs, but it is basically ORM of different sort when you don't write sql directly.
I'm sorry, but I disagree. An ORM is something different from a database wrapper.
An ORM is mostly peculiar of OOP languages, because it represents your database (tables, columns, etc...) in form of objects and they are very tighted between eah other. If your library also generates queries for you, that is a plus.
A database wrapper is simpler and more generic. I used a bad explanation in my last comment but the gist is that I use it to communicate with a db in a different way than an ORM. For example, I could write my query manually, then the library wraps/sanitizes it before talking with the db. How I map the result to my language data structure is a different problem, just like how it might generate a query for me.
"Primary reason not to do SQL was SQL Injection..."
That strikes me as like saying "We do not use the Math library, because devs keep using division instead of multiplication"
All languages are a tool for getting stuff done - use a tool intelligently and you get intelligent results. Use a tool poorly and you get a poor result. I don't see how SQL is any different to any other tool in that regard ?
For one man army with knowledge of SQL Injection, your argument is solid, but if you have 100s of developers, avoiding SQL Injection without ORM is impossible unless you have time to review every query ever written.
I can only speak from my area of expertise (Oracle) but in that instance, a single query will tell me where SQL injection risk points are.
connor-mcdonald.com/2016/05/30/sql...
Akash I really think that a basic crash course(or even a youtube video link) to
100s of developerson how to avoid SQL injections (eg by using say Prepared Statements ) is better than using a less optimized solution.Also, it helps the developers become better at their craft and you would be helping their growth in their careers.
Try it with 100 developers and let me know if all of them follow it correctly !!
Have you ever had a team of 100 backend engineers working on an API without each of them having to be in sub-teams with each team having a team lead before?
My argument is simple. It is the role of the team lead or more senior guys on a team to ensure that
SQL injectionthe most basic error while writing SQL does not happen. If they can't ensure that then the app would be buggy anywaysSerious question: Why are there 100 unique developers writing queries directly against the one same database, whether via SQL plaintext, query builders or even ORMs?
I see only two scenarios:
SQL injection is caused by underuse of SQL, not overuse of SQL.
If the logic was parameterized stored procedures in the DB, not queries string-built on the application server, there wouldn't be a vulnerability.
In most industries, it's ridiculous to allow arbitrary query access to production database.
If you put SQL in the db it might be hard to test but if it's in code it shouldn't be hard to test. Thanks!
Mocking is hard, creating unique instance of DB, seeding it, running 1000s of tests against it in parallel, all of that is hard, I never said it is impossible. It becomes terribly slow. I have created the tool to do it and we are doing it, but it is too slow compared to ORM's with in memory mocking.
Thinking of tesing with databae is hard, mocking it or at max using a in memory db is the better approach IMHO.
This is all good, but it leaves out a major point: Pulling directly from a database (or a filesystem) and exposing that to the consumer is not really scalable.
Sure, it works fine in a single application with its own database, but imagine 50 different webpages and services working off that same data. If one service makes a change to the database, then everyone needs to make changes to their code.
But, if everyone depends on a data accessor library (or service, or whatever), only the accessor needs to change! Everyone else's contracts will remain the same.
True, you're probably not going to swap out the entire underlying store all at once, (It happens, though... Especially early on in the lifecycle of the datastore.)
That being said, everything above is still applicable! Databases often are highly optimized for pretty much everything you pointed out (though sometimes full-string operations slow things down a LOT... I'm looking at you, Bob. I saw you put that
LIKEstatement on a multi-million row join. I warned you. I warned you about the stairs.)I'm looking at a bunch of BigQuery stuff right now at my current job, and I keep seeing these queries that over-use
with(). It's a simple join, Karen! It's not even aNOT INor fancy grouping! But BQ is usually fast enough that this doesn't even matter...Appreciate your views. As the example mentions it is a "microservice" so it is assumed that the DB is accessed by only one application. If you have 50 applications accessing one DB there is a bigger problem to solve IMHO. Not using SQL well is a different problem like you pointed to Bob for the like query. That could even run kinda OK if the indexes are placed logically. Thanks!
I would think that a database would be the one common thing when doing Mico services. Do you really scatter the data around like you do service endpoints. (my experience using and mocking micro services may not be representative.
Better to keep data central.
Keeping data central causes all the problems @jbristow mentioned.
And a "data accessor library" isn't a solution, it's just a bottleneck, in terms of flexibility if not even performance for your whole system.
Microservices should own their data, and communicate through APIs they expose, ideally through commands and events.
I've moved from ORM's to SQL guery generators. It gives a lot more freedom than most ORM's, let's you leverage the power of the DBMS, and promotes maintainability. I find it's a reasonable compromise for environments where the data isn't entirely stable and no REST api's are supported.
Good path taken, kudos!
There appears to be some angst in the comments which I feel are formed from some sort of professional bias. However I see the sentiment of your publication and I have to agree on a number of points. There appears to be a slight ignorance as to the benefit of using SQL to reduce complexities in application code but I believe the power of some languages has proliferated the tendency to pull all the data and manipulate it afterwards. Whilst this gives great flexibility it also brings with it real inefficient setups. I recently investigated some slow load speeds which turned out to be a developer pulling every column in on every query for simple search statements in a very wide table. Whilst the code looked really neat and the orm gave very shorthand code it feels as though there is little to no thinking about the database optimisations and even query optimisations that can be made. It's kind of treating an orm as just this magical gateway to fire hose data into the application.
Thanks for the support. ORMs need to be used wisely.
I have recently started putting logic in the DB, mostly when turning to Postgraphile which "turns" my DB into a GraphQL server.
Despite the slow start, I am starting to really feel the potential, especially when creating functions for inserts and special table joins.
Also, pgTAP makes testing quite simple.
GROUP_CONCATis cool, but I stopped using it in MySQL 5.6. Unfortunately, it has amaximum_lengthsetting which by default limits the return value to 1024 characters. It's the kind of bug that can go unnoticed for months, or only be evident with table growth. I wish it didn't have a limit (or that you could set no limit on it) and did not require fiddling with the DB settings. So beware! :)I'm not sure about newer versions though.
Good warning sign to take of.
True, SQL is indeed fast and powerful in data aggregation/manipulation.
We can also pre-compute these data aggregations/manipulations if they are queried frequently by users. I think running these aggregations queries, on the fly, on table with millions of records, by multiple users, maybe a slight overhead on CPU/RAM? No/Yes? Don't know.
That is where you need to profile the queries, run some explains, check the resource usage and decide where is it better to run it on the DB or code. Thanks!
True, event-updated projections are a much easier to conceptualize and scale than DB views.
To everyone here claiming that SQL is hard to test and troubleshoot: All SQL statements return a result-set. By using SQL Views, Functions and Stored Procedures you can test SQL code as you would test any other API call your code makes. Seriously, it's not an issue.
Agreed. A SQL statement is just code. It has an intended purpose and an expected result. That's pretty much what unit testing is designed to work with, no?
I'm trying hard, but I don't understand the concept of this post. From the purpose of databases to infrastructure management, I don't think I'd ever apply this method, even if it could cost me 10x in performance(in which case I would simply scale).
Use the superpowers of SQL to make your life easier as a software engineer.
Nope.
Hi @fjo_costa ,
it's the not the first time I hear this argument, and I'm not picking on you but I would honestly like to understand why you're against the idea of achieving 10x speed by using a well tested query or two.
I know it's harder to maintain if the specs change, but you can still swap the query for something else in the future, especially because ORMs tend to catch up to SQL features at some point.
Also, lots of languages have safe SQL generators, which mean you don't have to actually write the entire query, you can use tools like Arel.
I've built a query engine for composable conditions to select targets to send push notifications to once on it and I probably wrote two or three of pure SQL in total. I was still using the ORM, just augmented it through relational algebra, PostgreSQL json and basic geo support. It would have been immensely slower to do "in the app" (especially with hundres of thousands of devices). The engine was super fast and I had no caching.
I assure you I didn't anything special with tests, just tested that by selecting a condition, I had this or that device back, all inside the ORM.
I can agree to disagree :)
good post, probably the scenario could also be bigger: I was using everything but the group_concat which looks really useful, here is a so discussion about a postgres equivalent
stackoverflow.com/a/2561297/436085