This is re-publish of an article that I had written for my blog.
This article is just about describing how I perceive programming. The main purpose to write this article, is a constant stigma that I have come across that being programmer is a big deal, programming is hard to learn and understand. Also, from my personal experience, there have been numeral scenarios when people actually asked me, “Do you need to be a CS graduate to become a programmer? Why is programming is difficult? How do you learn it?,… so on and so forth”.
 |
|---|
| A problem? Oh! I can solve this |
Programming is a simple daily process that we do as humans. On day to day activities that we do, there are several situations that we come across scenarios that requires the skills needed to become programmer.
Philosophy I :
” Programming is art of thinking,
decision making and problem solving “
In simple way to put it up, Programming is a simple process of thinking, decision making and execution. The root of programming starts from you. The way you think, process and react to a certain situation to overcome that, is the simple philosophy behind programming.
I would like to take a simple instance to describe the above philosophy.
Assuming you are a coffeeholic person; and badly want to prepare a cup of instant coffee for yourself. What would you do?
 |
|---|
| Yes, I want to prepare a coffee for myself |
Let me put it down here as sequence of steps :
Wash the vessels that you want to use.
- Take required amount of milk in vessel.
- Heat up a cup of milk in the vessel.
- Add 1-2 teaspoons of instant coffee powder to vessel.
- Add required amount of Sugar required.
- Stir well until sugar dissolves.
- Serve yourself with Coffee in a Coffee Mug.
So, if you have ever done this, you are already a programmer. Wondering how? This was a simple process of making a coffee for yourself. But then there was a lot of things that you handled to make the coffee.
Let us re-collect ; once you decided to drink coffee, you washed the vessel required along with adding required amount of milk.
Also, added coffee powder and sugar as well, and stirred it well until the sugar dissolved.
You might wonder, How and why does this make you a programmer already?
Philosophy 1:
Programming is an art of Thinking,
Problem Solving, Decision Making
and Executing to resolve the issue.
If you take the the above instance, you wanted a coffee, was the problem statement;
how would you make a coffee was a critical part of your thinking and thought process.
Upon deciding to make a coffee, the decision you take up add sugar or coffee powder
not to make it too sweet or bitter is part of making decisions.
Finally, complete process from washing vessels to making coffee was the
execution from your part.
This was a simple example, and there are several such scenarios that you deal with, on a daily basis which needs a little amount of critical thinking, problem solving, decision making and this whole process is what defines the philosophy behind the art of Programming.
Philosophy II :
” Programming is a science of communicating with a Machine “
Now, thinking of the philosophy behind programming, technicality wise, programming is a way to communicate.
Communicate? How?
 |
|---|
Programming is a medium to communicate with the Machine. In another words, Programming is a technique how we can talk to machine, hence, making the machine do the thinking, decision-making and execution for us.
 |
|---|
Taking the same instance as above, for preparing a decaffeinated coffee, now with a Coffee machine. How would a machine deal with it assisted partially by us?
Let us chart it down:
- Add water reservoir of the Coffee Machine with water.
- Add the coffee filters to it.
- Click the switch on the machine to prepare the coffee.
- Collect the decaf and add sugar.
- Stir well.
Philosophy 2:
Programming is a science of telling the machine how to ingest, process and
store that data, thereby, resolving the issue.
*If you take the above instance with Coffee Machine into the picture, you wanted
a coffee prepared with Coffee Maker, was the problem statement; where machine
would prepare the coffee/decaf for you.
How the machine was designed to understand the problem and correspondingly
process it. Upon processing it, sequential execution to provide an end product
decauf to consume, was possible as the system/machine was programmed to do so.*
The part where programming plays very important role, is, we write instructions that machine will follow. Machines are very literal; they will take our instructions as laid and follow them same way.
Here comes Programming languages into play. You must be quite familiar with names like COBOL, C++, C, Pascal, Python, Java so on.
But there’s an big problem here!!
| |
|
|:--:|
| Well, no!!!!! |
Machines understand Machine-level languages, which is otherwise called as binary language, basically the complete representation of the instructions are in bits, i.e., 0’s and 1’s.
 |
|---|
| Basically how Coffee-Machine Instruction would look like in Machine Language |
For a human to write such instructions/programs would be a very tedious work. Hence to eliminate this trouble, they come up with an idea of High Level Languages. High level languages are programming languages to interact with the Machine, These languages were pretty much closer to human language; and not having the tedious work of dealing with bits like you do with Machine Languages.
Every programming language have some set of grammatical rules called Syntax that we need to follow, no matter what.
Just like how there is certain grammatical rules we should follow and take care of, no matter whether you are speaking French, German or English.
One major factor that plays an important role amidst this, is compiler/interpreter.
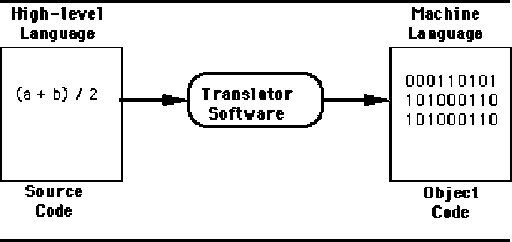 |
|---|
| Translator Software is called as Compiler, converting High Level Code to Machine Level Code |
Translator Software is called as Compiler, converting High Level Code to Machine Level Code
Compiler is a simple system software that is responsible for your High Level Programming instructions to be translated to Machine Level Instructions for the Machine to execute.
Coming back, Programming, at the prime, is taking a big problem and breaking them down to compact and smaller problems until they are small enough that we can tell the machine to resolve that for us.
Those are my ideologies about programming. I believe that programming is a very fundamental thing that every person does on day to day basis.
From waking up early morning and deciding what to do next, to going off to sleep in the night, there are several scenarios where you play the role of Programmer dealing with problems, solving them and making things happen and work. Also, I believe that programming should be taught to us from our elementary, because Programming means “We are thinking, making decisions, learning and most importantly letting our brain actively execute“.
If you like the article, hit the like button, share the article and subscribe the blog.
If you want me to write article on specific domain / technology I am provisioned in, feel free to drop a mail at shravan@ohmyscript.com
Stay tuned for my next article on The Programming Principles.
That’s all for now. Thank you for reading.
Signing off until next time.
Happy Learning.





Top comments (4)
Nice read,but even more for new comers. I believe it would be a good idea to see a second article about team building software, how these ideas scale when a team is working together to build something.
Thank you for the feedback.
I would try to make sense of machine language as well, if Computer Science is my major concern. I believe, through the knowledge of Assembler languages and hardwares. (Something like this, more than mere 01, I guess. -- also I think people do can read HEX, rather than binary.)
I personally see programming as creating things. But you also have to be reliable as well as responsible to do mission-criticial programming... It's more about responsibility. I do see another side though -- public facing side, and the priorities will be different.
Well said