"Serverless is a way to describe the services, practices, and strategies that enable you to build more agile applications so you can innovate and respond to change faster. With serverless computing, infrastructure management tasks like capacity provisioning and patching are handled by AWS, so you can focus on only writing code that serves your customers."
Definition of serverless, taken from AWS
For a long time, I had quite a close-minded view of Serverless. I made heavy use of AWS Lambda and DynamoDB and stitched it all together using an API Gateway. Development productivity was through the roof, life was great.
Until it wasn't.
I was working on a new project which had an extremely variable load (it could go for weeks without being used) but still needed really low latency when it was accessed.
Lambda is great and with provisioned concurrency enabled it was ok from a latency perspective, but the business wanted more. I was out of ideas.
My close-minded view of Serverless kept me banging my head against a wall of cold starts and application tracing to try and eek out as much performance as possible. It was a frustrating time. I knew Lambda was fantastic but couldn't quite meet the requirements of the customer.my def

Initial simplified architecture
A change in approach
That changed when I listed to an AWS podcast episode, specifically episode #448 talking about AWS Copilot. It struck me for two reasons:
- I've always been a big fan of ECS, but the cluster configuration, networking and general management was always a blocker. I'll openly admit networking and server management is a weak part of my skillset, and I've never learnt. Deploying from a CLI to an AWS best practice environment removes that blocker completely.
- There is more to Serverless than AWS Lambda.
And it's the second point that really struck me, there is more than one way to deploy an application in a serverless environment. I'm looking at you Fargate, and you App Runner.
Taking a line of text directly from the Copilot documentation - Request-Driven Web Service An AWS App Runner service that auto scales your instances based on incoming traffic and scales down to a baseline instance when there's no traffic. This option is more cost-effective for HTTP services with sudden bursts in request volumes or low request volumes.
Sudden bursts in request volumes or low request volumes - Doesn't that just sound like exactly what I am looking for?
So what does that give me? It provides a way for me to easily deploy an application that is 'always-on' from an easy-to-use CLI, without the need to worry too much about the underlying infrastructure.
This is when my definition of Serverless changed, and when the opening AWS quote made a lot more sense. Now I'd define Serverless as
"Any managed service that abstracts away operational complexity and allows developers and architects to focus on business value"
From AWS Lambda to Azure Functions to Heroku. All of these services provide a platform that removes a barrier for developers and allows them to just get their code out into the wild.
At a higher scale, there may be an argument for more fine-grained control. But for early startups and small companies, I cannot think of a better and more streamlined way of getting your product out there.
A change in architecture
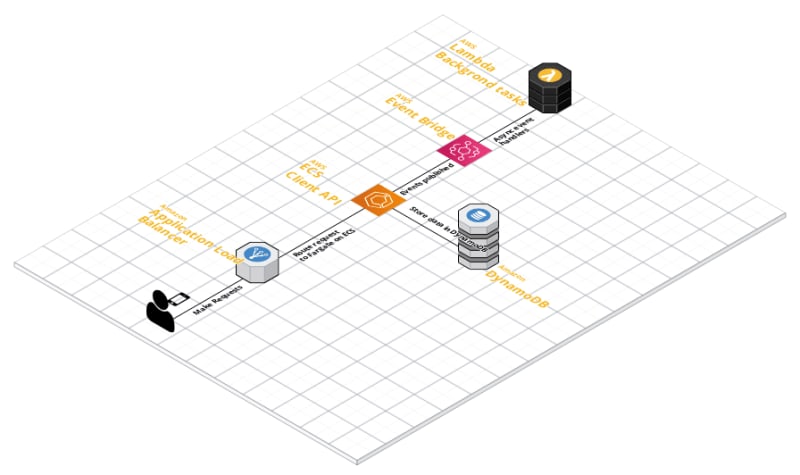
Whilst there isn't anything different at first glance, there is one really important distinction.
That distinction is AWS App Runner replacing the Lambda function that is handling client requests.
For people unfamilar with AWS App Runner, it's a fully managed way of running containers in AWS without the need for managing underlying servers. You simply configure the required amount of CPU and memory and off you go.
The rest of the architecture is identical. Any asynchronous event-driven tasks are still handled by Lambda. This feels like the use case for which Lambda was originally intended. A set of decoupled event handlers that sit doing nothing (and costing little money) until an event happens they are interested in that they react to accordingly.
What this means for the system, is that end users get a low latency API response no matter when they access the app. An App Runner task is 'always on' in the same way that running a server would be.
The trade-off here is an increase in cost, in that App Runner is charged per hour. The cost differs slightly when your application is actually processing requests vs sitting and waiting for a request to arrive. For a REST API, that is 24 hours a day 365 days a year. Slightly different than the Lambda model.
And what it comes down to is the age-old response of 'it depends'. Everything depends on the use case.
Lambda is a completely viable way to run an entire application, as long as a higher latency on the initial startup is ok. For high-volume API's, this is probably not an issue as the functions will always be warm.
However, for my specific use case of a low usage low latency application, the cost trade-off is something we are willing to accept to ensure the end-users have the best possible experience.
The customer always comes first.
For future applications, especially applications built in an event-driven fashion, this is becoming my de-facto architecture. Fargate / AWS App Runner for the client-facing applications, Lambda for the backend services that are less latency driven and more event-driven.
In Practice
Now for a quick example of just how easy it is to get started with AWS Copilot and AppRunner. For that, I'm going to use the order management service in my node-restaurant repository.
Originally, this application was built entirely from lambda functions. The REST API now runs as an express.js application, with any background event handlers running in Lambda. I already had a Dockerfile that I used for some local testing, so I can wire copilot up using that as well. So to get started with copilot, I simply run.
copilot init
The CLI gives a really great step by step walkthrogh, for reference I selected:
- Request Driven Web Service
- Name the application (order-api) Important note, AppRunner has a max length on the name field which is the application name plus the service name
- Select the Dockerfile (helpfully, copilot defaults as it's the only one I have)
- Yes to the test environment
After a minute or two you should start to see the output from the Docker build command and then the beginning of the deployment. A note here, the first time you push out to AppRunner it does take quite a while to provision the infrastructure. Go grab a coffee or something and come back later.
✔ Proposing infrastructure changes for stack node-restaurant-test-order-api
- Creating the infrastructure for stack node-restaurant-test-order-api [create complete] [317.2s]
- An IAM Role for App Runner to use on your behalf to pull your image from ECR [create complete] [17.9s]
- An Addons CloudFormation Stack for your additional AWS resources [create complete] [28.7s]
- An IAM role to control permissions for the containers in your service [create complete] [17.9s]
- An App Runner service to run and manage your containers [create complete] [285.9s]
Once complete, head off to the App Runner UI, and voila the API is ready to serve requests.
To come back around to my earlier point, everything always depends! There are benefits and trade-offs to every service, both AWS Lambda and App Runner are suitable for hosting an application. It just depends on the customer use case.





Top comments (0)