If you're working on a project or a company where SEO has a certain degree of importance for acquisition, there's a great deal of chance you've already asked yourself this question :
Should I route traffic to the remotely hosted (blog|faq|documentation) as a subdomain (blog.kactus.com) or as a subdirectory of my main domain (kactus.com/blog) ?
Deep down, we'd love the answer to be as a subdomain: set a CNAME record pointing to kactus.blogprovider.io and voilà ! But doing so could be detrimental to your overall domain SEO performance as it would suffer from backlink and keyword dilution. In a nutshell, it means that keyword matches and backlinks to your blog would not benefit your main domain as - from Google perspective - they are two different entities.
So subdirectory (or subfolder) strategy it is : we want to route all traffic from kactus.com/blog to our remotely hosted blog, kactus.blogprovider.io. Starting for our needs, what are our options ?
Using a Reverse Proxy
If you have access to your Web Server configuration, there's a great deal of chance you can perform the operation directly there. For instance for those using NGINX, one might configure the desired behavior as :
location ^/blog/(.*) {
proxy_pass https://kactus.blogprovider.io/$request_uri
}
At Kactus, we are a Ruby and Rails shop using Heroku to host our applications and thus we do not have access to the web server configuration. When the problem arised approximately 4 years ago - at the time of this writing - we didn't have many options apart from reverse proxying from the application server directly. We used a Ruby gem called rack-reverse-proxy which implements a Rack middleware used to proxy requests to a foreign service.
use Rack::ReverseProxy do
reverse_proxy(
/^\/blog(\/.*)$/,
"https://kactus.blogprovider.io$1",
timeout: 5,
preserve_host: true
)
end
It worked. Pretty well actually. However, as traffic grow up and the business got traction in the past couple of years, handling the proxy directly prove to be quite draining performance-wise :

Some weeks, reverse proxying to our blog accounted for close to 10% of server time, which, put into a more economic perspective, means we spent close to 10% of our server costs serving our blog pages from a remote server. Average response time was also quite bad, with an average of 350ms with peaks close to a second. We needed a new solution to scale.
Enter Cloudflare Workers
About a year ago, we setup Cloudflare as our edge server and CDN. All requests pass through it and are optimized to deliver a top notch experience to our users. Since Cloudflare sits in front of our application server, we wondered if there was any way we could route incoming requests to different endpoints, and stumbled upon Cloudflare Workers. Workers are serverless environments that can execute code on the Cloudflare network. Cloudflare docs have great examples of applications for this however the one that interests us is proxying requests.
As said before, all requests to our application servers pass through Cloudflare. To proxy requests to our blog, we need to :
- Catch incoming request starting with blog/(.*)
- Fetch the corresponding blog page on kactus.blogprovider.io
- Return the response to to the user
The first step is quite step forward. We set up a route pattern upon which our worker will be triggered, direclty on our workers dashboard :
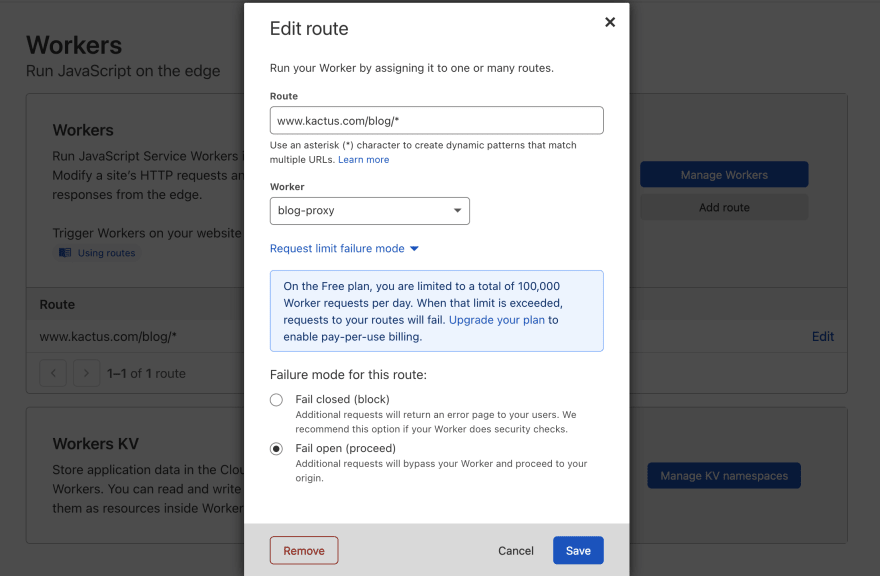
If you are on the free plan, you might want to update the request limit failure mode option to Fail open. In that case, if you overshoot your worker invocation quota, request will simply follow through to your origin. We kept our Rack::ReverseProxy implementation as a fallback on our end in the case workers broke down.
Now onto the code. Our blog-proxy worker is a javacript script that listens to the fetch event trigger (workers respond to only one other event which is scheduled for scheduled/CRON workers). A fetch event is triggered for every incoming request matching the previously set route pattern. We respond to this event by fetching the blog page and returning the response to the user :
const blog = {
hostname: "kactus.blogprovider.io"
}
async function handleRequest(request) {
// returns an empty string or a path if one exists
const formatPath = (url) => {
const pruned = url.pathname.split("/").filter(part => part)
return pruned && pruned.length > 1 ? `${pruned.join("/")}` : ""
}
const parsedUrl = new URL(request.url)
const targetPath = formatPath(parsedUrl)
return fetch(`https://${blog.hostname}/${targetPath}`)
}
addEventListener("fetch", event => {
event.respondWith(handleRequest(event.request))
})
The worker editor has a great interface to test and debug your workers before deploying them, and making sure everything runs smoothly :
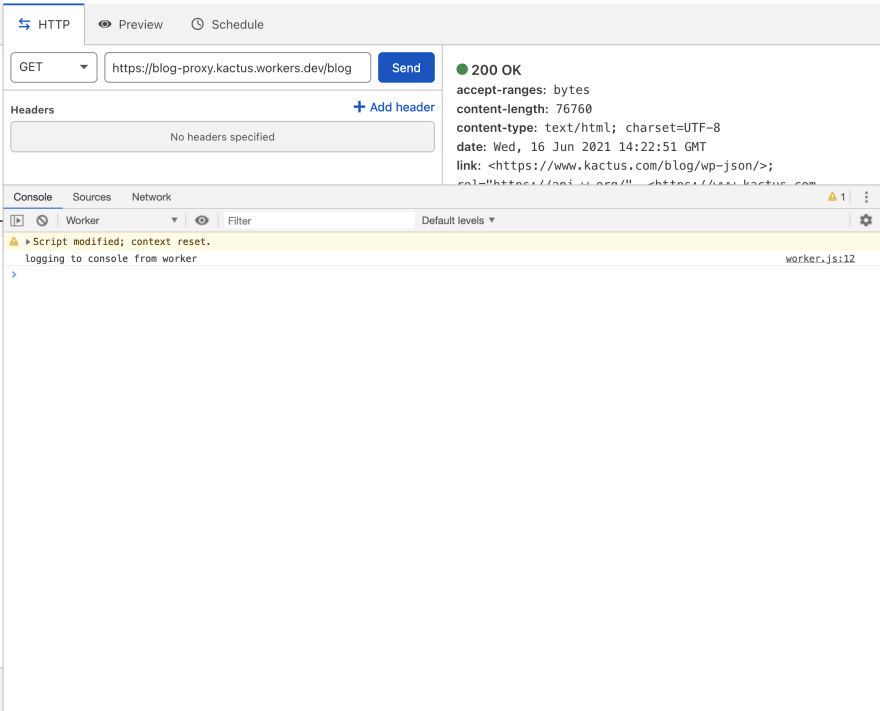
That's it, now our blog is served directly from our main domain as a subdirectory, and we can rip all the benefits from a strong SEO setup and improved performances !
Useful Links and Resources
Photo by José Martín Ramírez Carrasco





Top comments (0)