There are basically three common design patterns for Lambda functions: the Single Purpose Function, the Fat Lambda, and the Lambda-lith. In this post we're going to talk about a lighter-weight version of the Lambda-lith pattern. The diagram below shows a basic outline of what the lith pattern looks like.

The Lith pattern works well for small, limited APIs and microservices without too many routes or too much complex business logic. Everything is fit into a single lambda function and all routes are funneled to this function which determines how to handle the incoming request. In Node the routing is typically handled by a framework like Express or Koa. This pattern is simple and allows you to create an identical local development environment since your Lith is essentially just a containerized Express/Koa/whatever server.
But what if we don't want the overhead of using a framework just to handle a few routes? Express and other similar frameworks force us to deal with the request, response, and next objects which is usually far more than we need if we're just matching a route with a function to handle it.
Additionally, as functional programmers it should make us uncomfortable using this API since it is not type-safe, doesn't have any consideration for function purity, and it has us passing around mutable references to the Request and Response objects. Let's see if we can come up with our own method for routing that does consider these FP precepts. The end result should be a lightweight pattern for designing simple but robust microservices using AWS lambda.
Functional Programming in TypeScript
This post leans heavily on the fp-ts library. Teaching fp-ts is out of the scope of this post but there are many resources for learning functional programming in TypeScript and in general. Regardless you should be able to follow along even if you don't understand every line of code.
For routing we're going to use the amazing fp-ts-routing library built on top of fp-ts.
Basically this library allows us to parse a path string representing a route into a pre-defined type containing the data encoded in that route. Let's look at the example from the GitHub readme and walk-through each step.
//
// Locations
//
interface Home {
readonly _tag: 'Home'
}
interface User {
readonly _tag: 'User'
readonly id: number
}
interface Invoice {
readonly _tag: 'Invoice'
readonly userId: number
readonly invoiceId: number
}
interface NotFound {
readonly _tag: 'NotFound'
}
// (1)
type Location = Home | User | Invoice | NotFound
const home: Location = { _tag: 'Home' }
const user = (id: number): Location => ({ _tag: 'User', id })
const invoice = (userId: number, invoiceId: number): Location => ({ _tag: 'Invoice', userId, invoiceId })
const notFound: Location = { _tag: 'NotFound' }
// matches (2)
const defaults = end
const homeMatch = lit('home').then(end)
const userIdMatch = lit('users').then(int('userId'))
const userMatch = userIdMatch.then(end)
const invoiceMatch = userIdMatch
.then(lit('invoice'))
.then(int('invoiceId'))
.then(end)
// router (3)
const router = zero<Location>()
.alt(defaults.parser.map(() => home))
.alt(homeMatch.parser.map(() => home))
.alt(userMatch.parser.map(({ userId }) => user(userId)))
.alt(invoiceMatch.parser.map(({ userId, invoiceId }) => invoice(userId, invoiceId)))
// helper
const parseLocation = (s: string): Location => parse(router, Route.parse(s), notFound)
import * as assert from 'assert'
//
// parsers (4)
//
assert.strictEqual(parseLocation('/'), home)
assert.strictEqual(parseLocation('/home'), home)
assert.deepEqual(parseLocation('/users/1'), user(1))
assert.deepEqual(parseLocation('/users/1/invoice/2'), invoice(1, 2))
assert.strictEqual(parseLocation('/foo'), notFound)
The first thing we do is define a sum type representing the endpoints of our API. In this case there are four possible endpoints representing a
Location. Each endpoint is a tagged/discriminated union containing the required data for the respective endpoint. For example the route/users/1would be represented as an object conforming to theUserinterfaceconst user1 = {_tag: 'User', id: 1}
We also define helper constructors for eachLocation.-
Now we'll actually start using the features of Fp-ts-routing. For each route we need to build a
Matcherusing the provided combinators. A brief explanation of each matcher combinator:->
litmatches a literal string value, e.g.lit('home')matches/home->
intmatches an integer number value and stores it in the provided string value e.g.int('userId')matches'/10202'and the parser would return{userId: 10202}.->
thenallows us to chain together Matchers and thus
incrementally build up parsers for our routes. e.g. We
want our users route to be/users/:idand we can build a matcher for thatconst userIdMatch = lit('users').then(int('userId'))->
endjust matches the end of a route/. Without this combinator matchers likelit('home')would match'/home/otherstuff'instead of just'/home' Once we've constructed our matchers we can piece them together into a router that will parse a path string into a
Location. We do this using thealtmethod after constructing an 'empty' ('zero') parser making sure to pass in the sum type (Locationin this instance) that we're parsing to. Thealtmethod takes in theParserinstance for each matcher and returns a new parser comprising an amalgamation of all 'alternative' parsers.Finally we can use the parser and the helper function to parse path strings into our
Locationsum type.
Okay that was a lot. Let's talk a little bit about why this code as simple as it seems is actually very powerful.
Type Safety
The first thing we should mention is that our router is type-safe. That is we know and can account for all the possible states that the parseLocation function will return. Looking at the signature parseLocation(s: string): Location we can easily determine that this function takes a string and returns a Location. Given that Location is a sum type we know all possible valid states. This allows us to write trivially easy control logic by using pattern matching.
For example we might want to do something with the Location object parsed from the path string. We can pattern match on the _tag attribute of the Location object. TypeScript tells us all the possible values of Location! By writing our code this way we've offloaded the huge error-prone burden of keeping track of what states need to be accounted for in our control logic.
In fact if we've modeled our domain correctly only the states explicitly present in our Location sum-type are possible, meaning illegal states are simply not represented. In other words our code is guaranteed to be correct. I don't know about you but this makes me much more confident in the final product.
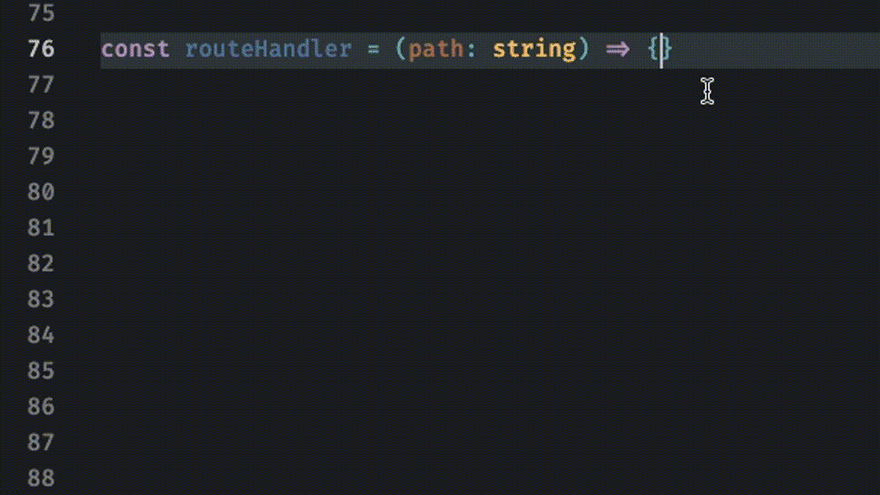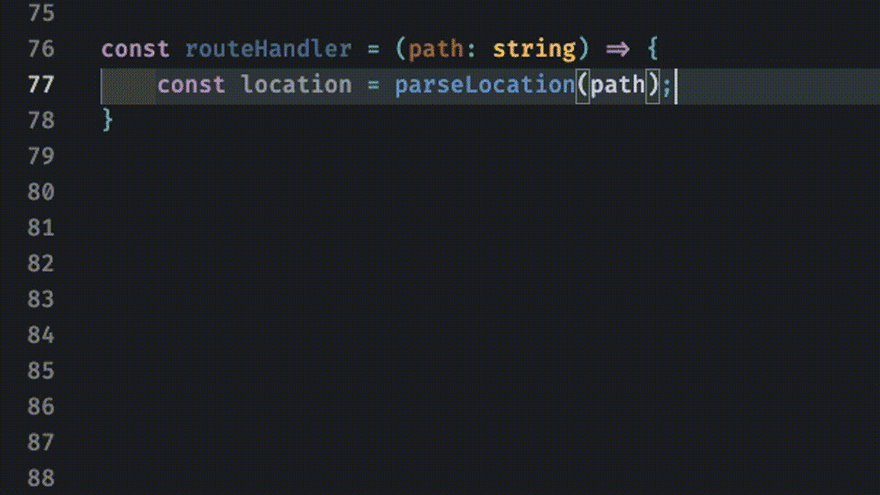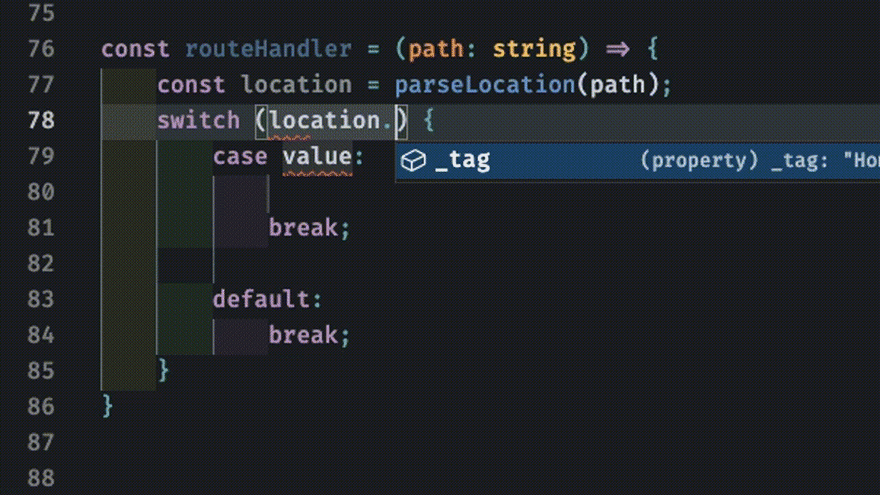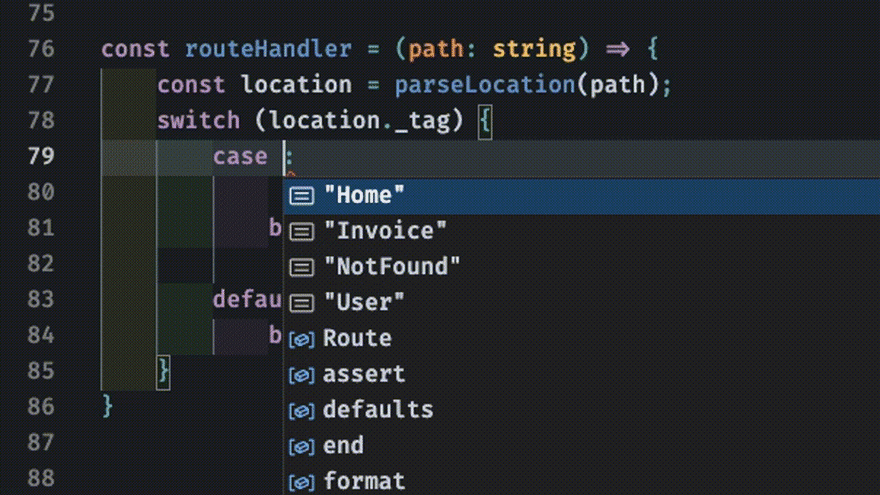
Exhaustiveness Checking
Generally a huge consideration when writing code for production is the understanding that what you're needs to be legible by others (or 'future you'). Writing type-safe code makes maintenance and code extension much easier. Function signatures and type definitions act as built-in documentation and turn the compiler into your own personal correctness checker.
One example of this is exhaustiveness checking. Consider the route handler example above. What happens if we didn't account for all the Location types? We may encounter unexpected behavior or a runtime error that crashes everything. But since we've modeled our API with sum-types we can use the powerful pattern of exhaustiveness checking.
If we define a function as follows:
const assertExhaustive = (param: never) => {}
All this function does is accept a parameter of type never and then... do nothing with it. That's because this function only exists to ensure that all cases in our switch statement are accounted for. Watch the gif below to see how this works.

By adding the assertExhaustive function to the switch statement we force the compiler to notify us if we are not handling a possible type of Location. This is very powerful as it ensures breaking changes (such as adding a new endpoint location) will not compile unless they are explicitly handled. The compiler is forcing us to write correct code.
Conclusion
So far we've been introduced to fp-ts-routing, we've seen how to define our API domain as a sum-type, and we understand why this allows us use the compiler to force code-correctness. In the next post we'll discuss composability and the monadic nature of our route parser. We'll see how from the simple building blocks that fp-ts/fp-ts-routing provides us we can build a type-safe, and robust router to power our AWS lambda microservice.





Oldest comments (0)