
Event-driven architectures in general and Event Sourcing in particular gain traction in the last couple of years. This trend is caused by the fact that we strive after building modular systems which are resilient und scalable. Microservices is the term which is used in this context quite often. In my opinion microservices are just one way to implement a Bounded Context. The heart of a modular system are the boundaries of a module and the most promising idea how to identify these boundaries is the Strategic Design introduced by Eric Evans' Domain Driven Design. It helps you to identify/discover your modules with their boundaries (Bounded Context) and describes the way how these Bounded Contexts are related to each other (Context Map).
Note: I will presuppose some foreknowledge about certain terms as I do not want to explain them for the thousandth time. I decided to link to the explanations of microservices.io, Wikipedia or Martin Fowler's Bliki, so it's up to you do dive deeper into a certain topic, if you feel uncomfortable with your knowledge.
Domain Events as the heart of the Ubiquitous Language
Although not explicitly mentioned in Eric's book Domain Events facilitate the idea of the DDD concepts quite well. Techniques like Alberto Brandolini's Event Storming shift the focus on events from a technical to a organizational / business level. We do not talk about some UI layer events like a ButtonClickedEvent, but about Domain Events which are part of the business domain and which are spoken and understood by the business experts. These Domain Events are first-class concepts and provide a great way to form the Ubiquitous Language which all participants (domain experts, developers,...) agree on.
Domain Events used for cross-boundary communication
Domain Events can be used for facilitating the communication between Bounded Contexts. Let's assume we have an online shop with three Bounded Contexts: Order, Delivery, Invoice.
A Domain Event of the Order context is Order accepted. The Invoice as well as the Delivery context is interested in the occurence of this event as it causes some internal processes to be started.
The decoupling myth
The usage of Domain Events helps you to develop decoupled modules. Modules might be offline temporarily. Domain Events do not care about unavailable modules, they describe something that happened in the past. It's up to the other modules how fast they process the events. What you get is a resilient system by design.
Beside temporal decoupling Domain Events promise another advantage, at least at the first glance:
The Order context does not have to know that the Invoice and Delivery context listen to its events. Actually it even doesn't need to know that those contexts exist.
That's cool, but the challenging part is the event payload. Which data do put into the event?
The simple answer: Event Sourcing!
Events are useful, so why not giving them as much power (and responsibility) as possible. That's the basic idea of Event Sourcing. You do not store the state of an aggregate by updating its data (CRUD) but by applying an event stream.
Beside that fact that you can replay events to rebuild the application state, one great feature of Event Sourcing is that you get a complete and reliable audit log for free. So when such an audit log is required, Event Sourcing should definitely taken in account while evaluating the persistence strategy.
Is Event Sourcing just a persistence strategy?
You might wonder why I came from Domain Events straight to persistence strategy as these concepts obviously work at different layers / abstraction levels.
... and that's my point: Event Sourcing is a local decision made by a single Bounded Context! The events should not be exposed to the outside world! Other Bounded Contexts do not know about each other's persistence strategy and therefore they don't know and don't care, if another Bounded Context uses Event Sourcing.
If you use Event Sourcing at global scale, you expose your persistence layer.
Your persistence becomes your public API. Every time a Bounded Context adjusts its persistent data, we have to deal with a public API change.
I'm pretty sure everyone agrees that it's a bad idea that different Bounded Contexts share data in a (relational) database because of development und runtime coupling. But where is the difference?
There is none. It doesn't matter if we share events or database tables. In both cases we share our persistence details.
There is a way out
I still argue that Domain Events are a perfect fit for the communication between Bounded Contexts, but these events shall not correspond to the events used for Event Sourcing.
My proposed solution is the logical consequence: Regardless whether you use a CRUD or an Event Sourcing approach for persistence you publish Domain Events to a global event store. These Domain Events are your Bounded Context's public API. If you prefer the usage of Event Sourcing in your Bounded Context you store these events in a local event store which only accessible from this Bounded Context
The freedom of choice
Having dedicated Domain Events in your public API opens up the possibility to decide how to model these events. You are not restricted to the layout which is predefined by the Event Sourcing events.
You have two options for each occurrence of a "real world event":
Open Host Service with Published Language
Publish exactly one domain event which contains all the data which might be needed by other Bounded Contexts. In DDD terminology one would call this an Open Host Service with a Published Language.
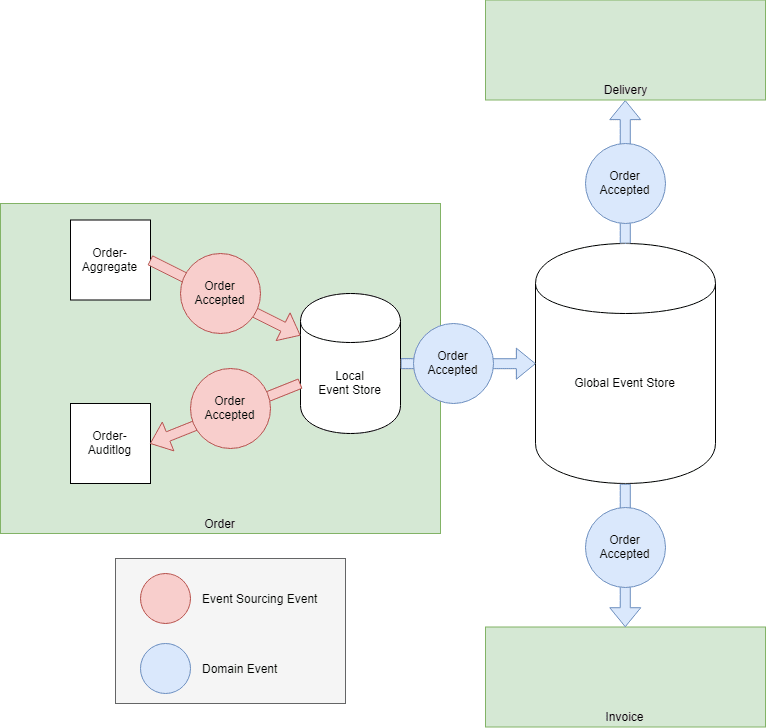
The occurrence of the real world event Order accepted leads to one published Domain Event OrderAccepted. The payload of this event contains all the data which Order expects other Bounded Context's to be interested in... so hopefully the Invoice and the Delivery contexts find all the information they need.
Customer/Supplier
Publish multiple dedicated Domain Events, one for each event consumer. You have to discuss each particular Domain Event with exactly one other party (the consumer) and don't have to define a shared model. DDD calls this relationship Customer/Supplier.
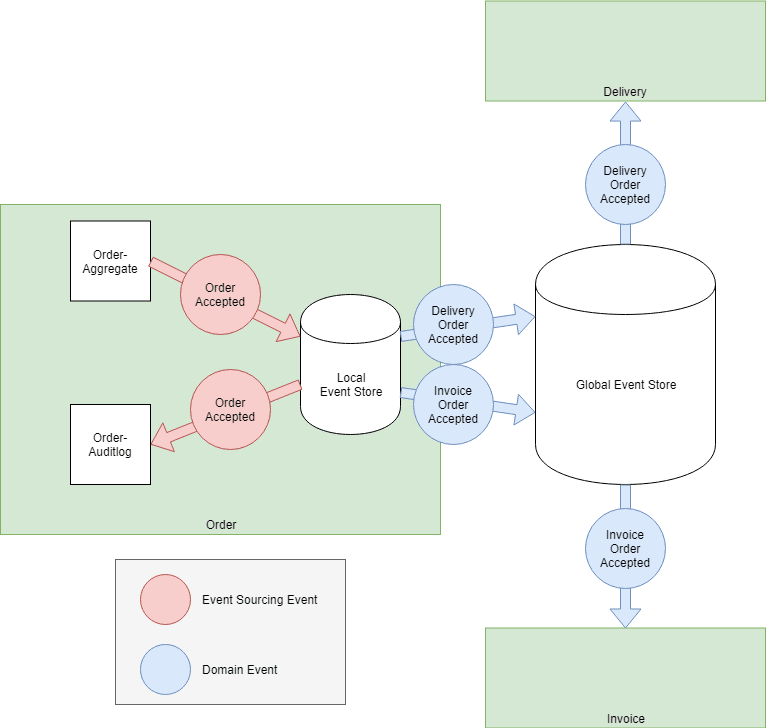
The occurrence of the real world event Order accepted leads to one published Domain Event per consuming Bounded Context: InvoiceOrderAccepted and DeliveryOrderAccepted. Each Domain Event contains exactly the data which is requested by the consuming context.
I do not want to discuss the pros and cons of the two options. I just want to highlight that you are free to choose the number of Domain Events and their payload.
This is a great advantage you should not underestimate, because you can decide how to evolve your Bounded Context's API and are not committed to the events you need for Event Sourcing.
Conclusion
Exposing persistence details to the outside world is a well-known anti-pattern. When talking about persistence we think about database tables in the first place, but I explained why the events used for Event Sourcing are just another way how to persist data. Therefore exposing these events is a anti-pattern as well.
 🖖Jochen Mader 🇪🇺@codepitbull
🖖Jochen Mader 🇪🇺@codepitbull A good developer is like a werewolf: Afraid of silver bullets.09:48 AM - 08 Oct 2016
A good developer is like a werewolf: Afraid of silver bullets.09:48 AM - 08 Oct 2016
438
538
Event Sourcing is powerful, if it's used in an appropriate (local) way. At first glance it seems to be the silver bullet for event-driven architectures, but if you look in deeper, you realize that it might lead you to a tightly coupled (distributed) system... and that's not your aim, for sure.
References
Beside my personal experience I got a lot of inspiration from different abstracts and conference talks. I would like to highlight the talk Event-based Architecture and Implementations with Kafka and Atom by Eberhard Wolff. Especially the chapters Event Sourcing and Whats's in the event? are highly relevant in the context of this blog post. The online shop example I chose is inspired by this talk.
There are some other resources you can consult if you would like to get some additional information:
- Domain Events vs. Event Sourcing by Christian Stettler, Blog post
- What they don’t tell you about event sourcing by Hugo Rocha, Blog post
- A Decade of DDD, CQRS, Event Sourcing (CQRS/ES is NOT a top level architecture) by Greg Young, Conference talk





Top comments (39)
The argument you're making, as I understand it, seems to fall along these lines:
Based on my experiences with Event Sourcing, I think we may disagree on a few things.
(1) On Event Sourcing being a persistence solution. I don't know if I would agree with this. Instead, I would suggest that Event Sourcing is a set of practices which begins with domain modeling and includes persistence, but is not solely persistence. If you ignore the DDD and modeling elements of Event Sourcing, then I think much of the value is lost.
This really leads to the next issue.
(2) Publishing Event Sourcing is akin to publishing your database. I read the reference article you provided on Domain Events vs Event Sourcing. When I look at the examples the author gives, the Event Sourcing events are named MobileNumberProvided, VerificationCodeGenerated, MobileNumberValidated. While these are technically "events", I would argue this is missing the point of Event Sourcing and are an anti-pattern. Let's call this technique Property Sourcing. Property Sourcing is not Event Sourcing. And if a team is using Property Sourcing, I'll absolutely agree that these events should not be published.
YMMV, from my experience with Event Sourcing, what should be persisted are true domain events like OrderAccepted from your example.
And since these are true domain events, I would expect that from within the BoundedContext, that no other name for OrderAccepted would be used e.g. ubiquitous language. So whether I'm using event sourcing or not, the code within the Bounded Context will be using these events to communicate. However, since I'm already writing these events, combing this with Event Sourcing is often very natural.
Which leads into the last point.
(3) Instead of publishing Event Sourcing events, publish X or Y instead. This may be semantics, but if you accept for a moment that Event Sourcing Events == Domain Events, then are many valid reasons that you may want to publish them as is: (a) analytics teams who want data in the streaming format that event sourcing provides, (b) security teams that may want to perform time critical operations on the data, and perhaps (c) even other micro services that have requirements for a high level of granularity. So saying publishing Domain Events is an anti-pattern probably goes too far. It depends.
Finally, as you point out, there are also many cases where a translation would be appropriate in which case generating Integration Events like those you've described would also be acceptable.
So while I think a number of the points you're making are valid, it sounds to me as if your assumptions are leading you to believe Event Sourcing is an anti pattern when in reality it's quite a useful pattern when applied appropriately.
Thanks for your valuable comment. I don't want to discredit Event Sourcing in general. I just want to point out that it's not a silver bullet and should be used with care.
You are absolutely right that Event Sourcing is more than persistence as it utilizes you in thinking about behaviour instead of data. Nevertheless it defines a way how to persist your application state.
In practice it's often required to be able to fix a typo. In an event sourced scenario you need to declare a corresponding event as it's not possible to persist the change otherwise.
The fix might be interesting for other bounded context, so you have to expose the change via an external event, but there is a change that some internal data is fixed and the other contexts don't need to know about it at all.
Anyway, I agree with you that Event Sourcing systems fail because people just use events without reflecting behaviour. They just trabsfer the CRUD mindset into events (OrderCreated, OrderUpdated, OrderDeleted).
I completely agree that having to fix already posted events is a pain. However, there are a few techniques that will typically offset this pain:
Use a serialization format that supports schema migration. I most often use protobuf, but avro is another good choice. This would take care of your typo issue without having to modifying any of the existing events.
Ensure that event includes just the facts and not derived information. For example, I might have a domain event Deposit which would includes the property, Amount. This is a nice fact that everyone can agree upon.
I could potentially include a Balance field in the Deposit event to indicate the balance after the deposit has been made, but because Balance is a derived value (the sum of all Deposits and Withdrawals), it's often subject to re-interpretation which might cause me to have to republish the event.
By sticking to facts, I find it greatly reduces my need to have to modify events. And most modifications for me are because my understanding of the domain has improved.
Matt, you mentioned that you use protobuf (or other serialization formats).
I have a small question about it:
Suppose you choose to publish domain events to the "whole system". Maybe for analytics or security features... I just want to clarify: would that mean, that both the event publisher and all the event consumers need to know the schema? (For encoding and decoding the buffer)
That's right. It would require you to maintain a schema registry somewhere either in code or as a service, but that's really no different from any other api.
Well, let's say that Pub/Sub is used between services. And let's say that we use Kafka as the event transport. And let's say that the configured retention period is set to some long period of time.
Is this ok? Because it's also an event sourcing implementation. The issue of shared infrastructure, shared schemas, and shared contracts is a totally separate issue that is ultimately a common denominator whether event sourcing is used or not.
We have to be judicious, as we would with any architectural style, about shared infrastructure, shared contracts, and shared schemas - irrespective of whether the schema is a wire schema or a persistence schema.
What's more critical is limiting the ability to write an event to a single authority, or single component. But that's the same constraint as apps connected by web services.
Microservices that are proximate and related can share an event store, just as they'd inevitably share a transport. Microservices that are distant - both in meaning and in space - likely should not. Or at least, we'd have to think through the tradeoffs to a much greater extent. But only a single component should eve have the authority to write to any given stream (or stream category).
Schema coupling is fine within a a locality, but increasingly risky outside of a locality. But messaging at a distance is still necessary and schema management will always be a factor. And events are just messages.
The judicious decisions we make about contracts and schemas have little to do with event sourcing or DDD. They're just the same old decisions we make in systems design and will continue to make for the imaginable future.
At the end of the day, if an integration is based on Pub/Sub, then there's events. And if there's events, you can do event sourcing.
In the end, it's not the database that is the unit of isolation. It's the stream.
Event Sourcing as a top level architecture is bad. It's meant to be used in a bounded context or in a business unit inside a bounded context. This has been said many times by Greg Young and Udi Dahan for almost a decade. udidahan.com/2012/02/10/udi-greg-r...
Exactly, the talk by Greg Young is linked at the end of the post. What I say is nothing new, it's just the combination of personal experience and existing references.
This ties in with how I’ve always thought of event sourcing in Microservices. I’ve never really heard of it being used as a communication pattern. We might share the same event store for services that use it, but each service would have its own event stream, which is perfectly fine, like multiple services using separate databases on the same dB server. But each service should definitely be responsible for storing and replaying its own events if event sourcing makes sense for that service.
Take a look at 5. Composing services becomes trivial from Event Sourcing: What it is and why it's awesome which is the first hit if you search for Event Sourcing at dev.to. The post has more than 100 likes.
I don't want to discredit the post, but it's an example for mixing the concepts of Event Sourcing and Domain Events.
Sorry this is my first time on this site so I never saw that post. I agree that part of that post is off where they seem to be conflating the benefits of an event driven system with the benefits of event sourcing, which is not correct. There can be some overlap, many times we will take a Domain Event that is received by a service and stick that in our event stream, so we can rebuild the state of that service by replaying all of the inputs to the service. But it depends on the nature of the service if that makes sense. And certainly we would not expose that event stream outside of that service.
For me, it boils down to "If you publish all of your events, you can never stop publishing them, because someone else might be relying on them. Even if you don't need them internally any more, having the data in new events!"
So having a translation layer, which at first can just filter events on type, is helpful to prevent this big maintenance problem.
Using a shared event store between bounded contexts is not like using a shared relational database at all.
If you share a relational database between services and then you change some schema of some table other services will blow up but if you share event store between services and you change schema of an event for example from V1 to V2 then nothing bad will happen. sharing an event store is more like sharing a queuing system as greg young mentions in this discussion:
groups.google.com/forum/#!searchin...
Ofcourse the two patterns that you mentioned in this article are perfectly valid but what i want to say is bounded contexts should only have private data therfore there is no antipattern about this, its only a trade off.
Having shared eventstore may have many advantages like having eventstore projections between multiple bounded contexts or simple event tracing via correlation id and causation id inside or between contexts.
There are many intresting talks around this subject by Greg Young , Chris Richardson and David Schmits.
Greg Young: talking about advantage of single event store around bounded contexts in µCon London 2017.
skillsmatter.com/skillscasts/11143...
Chris Richardson: Developing Functional Domain Models with Event Sourcing
youtube.com/watch?v=kQO0WnPo4sw
David Schmitz: Event Sourcing You are doing it wrong
youtube.com/watch?v=GzrZworHpIk
There is nothing wrong with a shared event store. I just argue that the events you produce in an event stored entity are rarely suitable for being exposed and shared.
Otherwise you are very limited in the freedom of evolving those events
I`m totally agree with you on this, but think about benefits that you may have when you publish all of your internal events to out world, for example simplicity of tracing events is a huge benefit when you have only one event store across all services and services dont have any local event store. If you separate local event store from global event store you may have challenges to trace what local event causes what global event and so on and this is only a simple example of many serious complexities that you may have.
I just want to say having one event store across all microservices without ES per service is not like shared relational database and also anti-pattern, it's only a trade off between simplicity and scalability.
You are right, but because of modularity a lot of challenges arise. Example: At first glance it might be easier and quicker to simply join two tables instead of thinking about an API.
Nevertheless it's better to modularize strictly as the benefits outdo the challenges.
Hi Oliver,
I agree that we should be careful with exposing Domain Events outside of the Bounded Context (this seems to be the main message of the article), but on the other hand it's fine to communicate between micro-services using Domain Events, as long as these micro-services are in the same Bounded Context, isn't it?
It's fine to expose domain events. You have to think about the payload. It's also wanted that other bounded context react in those events.
The main message is "Don't use fine-grained event sourcing events as domain events."
So far, I thought that the Domain Events are exactly the events that you source from. Is there a reason to distinguish between Domain Events and Event Sourcing Events? In other words, when you want to do Event Sourcing, shouldn't Domain Events be stored in such a way that you can later construct Entities from them?
In my opinion the article answers your questions.
Hmm, okay, I think I got some insight to where we disagree. In any case, thanks for the write-up, I'm new to this pattern and it triggered some interesting thoughts.
From the title, I was prepared to disagree with you. Because there is nothing wrong with using Event Sourcing inside a microservice. But I do agree with your conclusion. A service's persistence details should remain private. Anything that is shared publicly should be separate, because it is used for a different purpose and may change for different reasons. This is a core Separation of Concerns.
Also, thanks for the links. I look forward to reviewing some of these I haven't seen.
Thanks for your feedback. I adjusted the title to Why Event Sourcing is a microservice communication anti-pattern.
Good article I totally agree with what you said, Event Sourcing events are different from Domain Events (one is related to the functioning of aggregates while the other in the integration between bounded contexts) and should be treated as such
Good job at putting all of these togheter Oliver, this is a controversial and confusing topic for a lot of developers out there.
I cheekly identified this as being a naming induced problem, there is a big craze at naming everything events at the moment that most people confuse them as being scoped for out of system use whereas event is a better use of the term data or variable.
Regardless if the events are local or global they need to have a creation timestamp.
In general it's desirable to rely as less as possible on the order of events. While the events emitted by a single aggregate need to be handled sequentially, you should not make assumptions in which order events of other bounded contexts occur.
You've written that event sourcing events shouldn't be propagated outisde the bounded context.
I have a few questions.
Regarding 1. Yes, I think so. The scope of those events doesn't have to be restricted to a single aggregate.
Regarding 2. Good question. To be honest: I don't have an opinion on that one. It's a question of responsibility. And one can argue that it's the aggregate's responsibility to publish domain events, but you can also argue that it's sufficient, if the aggregate publishes ES events and another component translates it a domain event (if needed).
Hi Oliver,
I would like to hear your thoughts on "Event streaming as the source of truth":
thoughtworks.com/radar/techniques/...
I found it in the book "Designing Event-Driven Systems" by Ben Stopford, where he shares the concept for the "data outside", and how CQRS and ES implemented with Kafka streams and Materialised views can help you share data within your organization - I assume he means here outside of its bounded context, I could be wrong.
From the book:
"Summary
This chapter introduced the analogy that stream processing can be viewed as a database turned inside out, or unbundled. In this analogy, responsibility for data storage (the log) is segregated from the mechanism used to query it (the Stream Processing API). This makes it possible to create views and embed them exactly where they are needed—in another application, in another geography, or on another platform. There are two main drivers for pushing data to code in this way:
• As a performance optimization, by making data local
• To decouple the data in an organization, but keep it close to a single shared source of truth
So at an organizational level, the pattern forms a kind of database of databases where a single repository of event data is used to feed many views, and each view can flex with the needs of that particular team."
Sounds a bit opposite to what you are sharing, but that could be me as new with the Event-Sourcing.
What I'm struggling to understand is the comparison of the persistence layers, normal relational database IMO will be the bottleneck if you want to share between services - all the monolith problems with how to evolve the schema, etc.
But in cases like Kafka when you have a very scalable event store, with schema registry (validations and versioning) - well that removes the most painful problems.
Even if you share only Bussiness Events you still will need to have a good event schema versioning solution, and if you have one then maybe this eliminates the need to keep the event sourcing only local. If you expose it, now any new interested consumer/service will have access either to a fast snapshot or to the full history and consume it without asking the service for data (no need to know how to consume the service). Versus if the new actor has access only to the business event and needs additional data elements it will need to query (rest, etc) the service for that. Which makes it aware of the service and how to communicate with it. Potentially if the service does not expose the data elements the new service needs, it will have to introduce a new API change. Worst case if the data is needed as ES, as a log for replaying (AI, etc) then you have to expose your internal ES store vs API.
Maybe I'm missing something and your opinion is welcome!
I think the core underlying problem is that there is no standard for asynchronous communication among services. For example how is operation that can take long time is exposed and invoked. Queuing and event sourcing are attempts to workaround this limitation.
I think the real solution is to expose asynchronous service API explicitly and use an orchestration technology to implement the business transaction using such APIs.
I would recommend looking at Cadence Workflow open source platform that supports such orchestration using natural code.
U r right on the point event sourcing should be within the bounded context of the service otherwise it is an anti pattern.