
On a Friday morning, slacking, you are thinking about the new Netflix shows to catch. Your boss comes over, asks you to write a parser for a Systemd unit file. She needs it by Monday.

You're nervous. Last time you were asked to write a parser, you went down the rabbit hole of the web, Copying and Pasting Regex Formulas Until It Worked™.

You take a sip of your boba tea to calm yourself down. You google up Systemd and like... no, it's not as simple as you thought.

Your good 'ol regex copy-paste trick flies out the window. Chances of spending non-disruptive weekend to binge on shows are quickly going toward null.
PEG To the Rescue
Don't lose hope just yet. Let me introduce you to Parse Expression Grammer (PEG), an easy way to wrap your head around parsers and save your valuable weekend.
PEG is a readable way to write syntax rules and is quite similar to regular expressions, which is different from a Context-free Grammar counterpart such as Backus-Naur Form (BNF) in which expressions must be reduced to smaller symbols. Sorry, Noam Chomsky, maybe some other work days.
I will be using a Rust PEG parsing library called Pest, which is pretty awesome. If you haven't yet, I'll wait up while you go install Rust.

Getting Started
Let's kick off with a simple grammar for parsing a JavaScript-like variable declaration statement. We will start by thinking about a set of rules for valid inputs.
A declaration statement:
- begins with a keyword
var, followed by one or more identifier(s). - is white space insensitive
- ends with a semicolon (
;)
A group of identifiers:
- is preceded by a
varkeyword - is delimited by commas
- is white space insensitive
An identifier:
- can contains any number of digits, characters, and underscores in both lower and upper cases
- cannot start with a digit
- cannot contains any space
An identifier is a term, meaning it is an unbreakable piece of token. So are the var keywords and the semicolons.
Circle back a bit to BNF side, using Extended Backus-Naur Grammar (EBNF), you could formally define the above grammar like this:
<alpha> := 'a' | 'b' | 'c' | 'd' | 'e' | /* ... */ 'z'
| 'A' | 'B' | 'C' | 'D' | 'E' | /* ... */ 'Z'
<digit> := 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
<Decl> := 'var' <Idents> '\n'? ';'
<Idents> := <Ident> ('\n'? ',' <Ident>)*
<Ident> := <alpha>+ (<alpha> | <digit> | '_')*
The uppercase rule name represents a non-terminating symbol (i.e. can be broken down to smaller terms). The lowercase name represents a term.
For brevity sake, we leave out implicit white spaces from the rules. Basically, one or more white spaces can exist between every symbols you see.
Let's dig into it! The <alpha> and <digit> rules are self-explanatory, so we'll leave that to your guess.
<Decl> is the most complex rule for a declaration statement, featuring a var keyword, <Idents> symbol, optional new line, and ending with a semicolon. Basically, this rule says, "Any string input beginning with var, followed by one or more spaces, then a sub-rule <Idents>, followed by one or more spaces and finally ending with a single semicolon is valid and I'll happily chomp on them."
<Idents> can either be a single <Ident> symbol, followed by zero or more pairs of comma and <Ident>.
Finally, an <Ident> must begin with one or more character, followed by zero or more character, digit, or underscore.
Ok, Code please
Hold on, young Anakin! Hot-headed, you are. Lo and behold, with the grammar defined, we will be able to parse these statements:
var foo, bar, baz;
var foo_1, baRamYu,baz99;
var foo_x
, baroo
, bazoo
;
No, I didn't forget to format my code. It's valid JS, and it is for our parser too! Here is something our rules won't stand:
var 99Problems
Anyone care to guess what's wrong here? ✋ Leave your answer in the comment. (psss, if your answer is right, I'll follow you + 3 likes on your post 👍)
Enter Rust and Pest
Ok, I hope you already have Rust installed (In your terminal, trying typing which cargo and see if it comes up). Start by creating a new Rust binary project with
$ cargo new --bin maybe-js; cd maybe-js
Within the project folder, open up Cargo.toml file and add the following under dependencies, and run cargo update to install them.
[dependencies]
pest = "2.0"
pest_derive = "2.0"
Once that's done, cd into src and create a file called grammar.pest, and paste the following in it:
alpha = { 'a'..'z' | 'A'..'Z' }
digit = { '0'..'9' }
underscore = { "_" }
newline = _{ "\n" | "\r" }
WHITESPACE = _{ " " }
declaration = { "var" ~ !newline ~ idents ~ newline? ~ ";" }
idents = { ident ~ (newline? ~ "," ~ ident)* }
ident = @{ !digit ~ (alpha | digit | underscore)+ }
Now if I have had your attention for the last few minutes, it shouldn't be to hard to take a guess on what's happening here. (Oh, I haven't? Anyways... here we go)
The first five are all terms. They are sets of valid values. The | is called the Choice Operator, which is like "or-else".
first | or_else
When matching a choice expression, first is attempted. If first matches successfully, the entire expression succeeds immediately. However, if first fails, or_else is attempted next.
The newline rule has a quirky _ before the bracket, which in Pest speaks means "silent" -- we simply don't want it as a part of our parsed tokens, but it is nonetheless part of a valid syntax.
The WHITESPACE rule has a special place in Pest. If you defined it, Pest will automatically insert implicit optinal white spaces (according to the WHITESPACE rule you define) between every symbols. Again, the _ says we want to silent it, since we don't want tons of white spaces as part of our syntax tree.
The declaration rule is very similar to the EBNF counterpart we learned before. The tildes ("~") simply mean "and then". The rule starts with a "var" keyword, followed by anything that isn't a newline (the "!" does what you intuitively would have guessed - negating a rule), followed by a sub-rule idents, an optional newline, and ends with a semicolon.
The idents rule is again similar to the EBNF example. It is either an single ident, followed by zero or more comma-separated idents.
The ident rule is a little special. The "@", known as Atomic, in front of the bracket is there to say, "I don't want implicit white spaces to apply to this rule." We sure don't want to include any space in our variable name. Moreover, marking a rule as atomic this way treats the rule as a term, silencing the internal matching rules. Any inner rules are discarded.
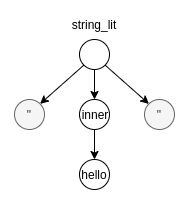
string_lit = { "\"" ~ inner ~ "\"" }
inner = { ASCII_ALPHANUMERIC* }
Note that ASCII_ALPHANUMERIC is a convenient built-in rule in Pest for any ASCII characters and digits.
If we parsed a string "hello" with this rule, this will yield first a string_lit node, which in turn has an inner node containing the string "hello", without quotation marks.
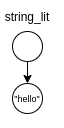
Adding a "@" sigil in front of string_lit bracket:
string_lit = @{ "\"" ~ inner ~ "\"" }
inner = { ASCII_ALPHANUMERIC* }
We will end up with a flat string_lit node containing "\"hello\"".
A similar sigil "$" known as the Compound Atomic, protect implicit white spaces inside the rule. The difference is it allows internal matching rules to parse as normal.
The !digit part protects the rule from going forward if it starts with a number. If it doesn't, any one or more combinations of characters, numbers, and underscores are fine.
But wait, where's the code?
Dang, my clever explorer! You seem to corner me at every move. Yes, that wasn't code at all but a Pest grammar definition. Now we have to write some Rust code to parse some text. Fire up src/main.rs and add the following:
/// You need to do this to use macro
extern crate pest;
#[macro_use]
extern crate pest_derive;
/// 1. Import modules
use std::fs;
use pest::Parser;
use pest::iterators::Pair;
/// 2. Define a "marker" struct and add a path to our grammar file.
#[derive(Parser)]
#[grammar = "grammar.pest"]
struct IdentParser;
/// 3. Print the detail of a current Pair and optional divider
fn print_pair(pair: &Pair<Rule>, hard_divider: bool) {
println!("Rule: {:?}", pair.as_rule());
println!("Span: {:?}", pair.as_span());
println!("Text: {:?}", pair.as_str());
if hard_divider {
println!("{:=>60}", "");
} else {
println!("{:->60}", "");
}
}
fn main() {
/// 4. Parse a sample string input
let pair = IdentParser::parse(Rule::declaration, "var foo1, bar_99, fooBar;")
.expect("unsuccessful parse")
.next().unwrap();
print_pair(&pair, true);
/// 5. Iterate over the "inner" Pairs
for inner_pair in pair.into_inner() {
print_pair(&inner_pair, true);
match inner_pair.as_rule() {
/// 6. If we match an idents rule...
Rule::idents => {
/// 7. Iterate over another inner Pairs
for inner_inner_pair in inner_pair.into_inner() {
match inner_inner_pair.as_rule() {
/// 8. The term ident is the last level
Rule::ident => {
print_pair(&inner_inner_pair, false);
}
_ => unreachable!(),
}
}
}
_ => unreachable!(),
}
}
}
It's ok if you don't understand most of the thing here. Let's run it with cargo run in your project directory and look at the printed output.
Rule: declaration
Span: Span { str: "var foo1, bar_99, fooBar;", start: 0, end: 28 }
Text: "var foo1, bar_99, fooBarBaz;"
============================================================
Rule: idents
Span: Span { str: "foo1, bar_99, fooBar", start: 4, end: 27 }
Text: "foo1, bar_99, fooBarBaz"
============================================================
Rule: ident
Span: Span { str: "foo1", start: 4, end: 8 }
Text: "foo1"
------------------------------------------------------------
Rule: ident
Span: Span { str: "bar_99", start: 10, end: 16 }
Text: "bar_99"
------------------------------------------------------------
Rule: ident
Span: Span { str: "fooBar", start: 18, end: 27 }
Text: "fooBarBaz"
-----------------------------------------------------------------
The most important concept here is a Pair. It represents a matching pair of tokens, or equivalently, the spanned text that a named rule successfully matched.
We often use Pairs to:
- Determining which rule produced the
Pair - Using the
Pairas a raw&str - Inspecting the inner named sub-rules that produced the
Pair
let pair = Parser::parse(Rule::enclosed, "(..6472..) and more text")
.unwrap().next().unwrap();
assert_eq!(pair.as_rule(), Rule::enclosed);
assert_eq!(pair.as_str(), "(..6472..)");
let inner_rules = pair.into_inner();
println!("{}", inner_rules); // --> [number(3, 7)]
a Pair can have zero, one, or more inner rules. For maximum flexibility, Pair::into_inner() returns Pairs, which is an iterator type over each pair.
💡
Pair::into_inner()is very common idiom when working with Pest. Make sure you understand what aPairis.
Let's parse Systemd

Now it's time to put the work in. Here is an example of a Systemd unit file:
[Unit]
Description=Nginx
After=network-online.target
Wants=network-online.target
[Service]
Type=simple
Environment=PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/home/ec2-user/.local/bin
Environment=LD_LIBRARY_PATH=/usr/local/lib
Environment=PKG_CONFIG_PATH=/usr/local/lib/pkgconfig
ExecStart=/usr/local/sbin/nginx-runner.sh
Restart=on-failure
RestartSec=0
KillMode=process
[Install]
WantedBy=multi-user.target
The file is grouped into sections, each with a name enclosed by a pair of square brackets. Each section contains zero or more pair of property name and value, seperated by an equal sign "=".
Let's try to flesh out a set of rules. Create a new rust project with cargo new --bin systemd-parser, then create a file named src/grammar.pest with the following rules:
/// Implicit white spaces are ok.
WHITESPACE = _{ " " }
/// Set of characters permited
char = { ASCII_ALPHANUMERIC | "." | "_" | "/" | "-" }
/// name is one or more chars. Note that white spaces are allowed.
name = { char+ }
// value can be zero or more char, plus = and : for path variables.
value = { (char | "=" | ":" )* }
/// section is a name, enclosed by square brackets.
section = { "[" ~ name ~ "]" }
/// property pair is a name and value, separated by an equal sign.
property = { name ~ "=" ~ value }
/// A Systemd unit file structure
file = {
SOI ~
((section | property)? ~ NEWLINE)* ~
EOI
}
In the main.rs file, start with the following:
extern crate pest;
#[macro_use]
extern crate pest_derive;
use std::fs;
use std::env::current_dir;
use std::collections::HashMap;
use pest::Parser;
#[derive(Parser)]
#[grammar = "grammar.pest"]
struct SystemdParser;
/// Implement a simple AST representation
#[derive(Debug, Clone)]
pub enum SystemdValue {
List(Vec<String>),
Str(String),
}
// ...
As the first step, after the initial imports and setup, we define a SystemdValue enum as a simple representation of data type in a Systemd file. SystemdValue::Str(String) will captures a single property value, and SystemdValue::List(Vec<String>) will captures multiple property values with a duplicate property key name. For example, in the previous nginx.service file, there are several Environment properties.
Here is the main function:
fn main() {
// Read and parse the unit file.
let unparsed_file = fs::read_to_string("nginx.service")
.expect("cannot read file");
let file = SystemdParser::parse(Rule::file, &unparsed_file).expect("fail to parse")
.next()
.unwrap();
// Create a fresh HashMap to store the data.
let mut properties: HashMap<String, HashMap<String, SystemdValue>> = HashMap::new();
// These two mutable variables will be used to store
// section name and property key name.
let mut current_section_name = String::new();
let mut current_key_name = String::new();
// Iterate over the file line-by-line.
for line in file.into_inner() {
match line.as_rule() {
Rule::section => {
// Update the current_section_name
let mut inner_rules = line.into_inner();
current_section_name = inner_rules.next().unwrap().as_str().to_string();
}
Rule::property => {
let mut inner_rules = line.into_inner();
// Get a sub map of properties with the current_section_name key, or create new.
let section = properties.entry(current_section_name.clone()).or_default();
// Get the current property name and value.
let name = inner_rules.next().unwrap().as_str().to_string();
let value = inner_rules.next().unwrap().as_str().to_string();
// If the property name already exists...
if name == current_key_name {
// Get the section of the map with the key name, or insert a new SytemdValue::List.
let entry = section.entry(current_key_name.clone()).or_insert(SystemdValue::List(vec![]));
// Push the value onto the inner vector of SystemdValue::List.
if let SystemdValue::List(ent) = entry {
ent.push(value);
}
} else {
// Create a new SystemdValue::List and save it under name key.
let entry = section.entry(name.clone()).or_insert(SystemdValue::List(vec![]));
// Push the current value onto the vector, then set the
// current_key_name to the current name.
if let SystemdValue::List(ent) = entry {
ent.push(value);
}
current_key_name = name;
}
}
Rule::EOI => (),
_ => unreachable!(),
}
}
}
This is all good, but we didn't use SystemdValue::Str anywhere in the code. To keep code clean, we decided to treat every property as HashMap<String, SystemdValue::List(Vec<String>), where the key of the map is the property key, and the String vector stores the list of property values. If there is no value, the vector is empty. If there is one value, this vector contains that single value, and so on.
To make the API a little bit easier to use, we will write a small helper function to process all the single-valued Systemd::List(Vec<String>)s and convert them into Systemd::Str(String).
// Iterate over the nested maps, and convert empty and
// single-element `SystemdValue::List<Vec<String>>` to
// `SystemdValue::Str(String)`.
fn pre_process_map(map: &mut HashMap<String, HashMap<String, SystemdValue>>) {
for (_, value) in map.into_iter() {
for (_, v) in value.into_iter() {
if let SystemdValue::List(vs) = v {
if vs.len() == 0 {
let v_ = SystemdValue::Str(String::new());
*v = v_.clone();
} else if vs.len() == 1 {
let v_ = SystemdValue::Str((vs[0]).clone());
*v = v_.clone();
}
}
}
}
}
Now we are ready to print it out for the world to see!
fn main() {
// Our main code
pre_process_map(properties);
println!("{:#?}", properties);
}
Boom! Congratulations! You have just written a Systemd file parser, plus a mini JS one. 🤯 Now you will have some spare time to party away on your Friday night. With another afternoon, you might even figure out how to serialize your Systemd unit file into JSON to impress your boss on Monday.
You can check out the parser code implemented as a library in this repo:
 jochasinga
/
systemd-parser
jochasinga
/
systemd-parser
A minimal Systemd unit file parser
If you like how I helped save your weekend, don't be shy and upvote this post. Please follow me to get more meme-joy hackery like this one. All Q&As are welcome! Just leave your comment and I'll try my best to answer.






Top comments (8)
I could not get this to compile.
#[derive(Parser)]errors out with cannot find deriver macroParserin this scope, despitepest_derivebeing in Cargo.toml and the use statement bringing Parser in.I discovered this was for 2 reasons: 1) there was a typo in the .pest file that made the proc crash causing a compiler error; and 2) you need `#[derive(pest_derive::Parser)] to differentiate it from pest::Parser.
Hi, thanks for letting me know. You have to import the
Parsertrait frompestmodule withuse pest::Parserbefore you can derive it.Or if you have done the above, please check the following block:
You don't have to use
pest_derivedirectly, but you need the#[macro_use]attribute applied to the extern statement.You don't need the #[macro_use] attribute any more for 2018 edition of Rust.
You still need this block for Pest to generate the code for you. Omitting the block exactly reproduced the issue you had. You don't need the
extern crate pest;statement though.You don't at all.
#[macro_use]is not required in 2018 edition. I was able to compile it fine without it using only the 2nd change I described above. To be clear, the typo I described before was of my own doing and nothing to do with your code.Thank you for this great discovery, Pan Chasinga ! I was looking for something like that since a long time ago and looks like PEG and PEST make things easier than I found ! 🤩
I think I found a tiny typo :
fooBarin code becomesfooBarBazin output ?Thanks for the kind words and the correction.