
A couple of weeks ago I was talking to one of my oldest database colleagues (and a very dear friend of mine). We were chatting about how key/value stores and databases are evolving, and how they always seem to be revolving around in-memory solutions and cache. The main rant was how this kind of thing doesn’t scale well, expensive and complicated to maintain.
My friend’s background story was that they are running an application that uses a user profile with almost 700 million profiles (their total size was around 2TB, with a replication factor of 2). Since the access to the user profile is very random (meaning, users are fetched and updated without the application being able to “guess” which user it would need next) they could not use pre-heating of the data to memory. Their main issue was that sometimes they get peaks of over 500k operations per second of this mixed workload and that doesn’t scale very well.
 User Profile use case summary
User Profile use case summary
In my friend’s mind’s eye, the only things they could do is use some kind of a memory based solution. They could either use an in-memory store — which, as we said before, doesn’t scale well and is hard to maintain, or use a traditional cache-first solution, but lose some of the low latency required, because most of the records are not cached.
I explained that Aerospike is different. In Aerospike we can store 700 million profiles, 2 TB of data, provide the said 500k TPS (400k reads and 100k writes, concurrently) with a sub 1ms latency, but without storing any of the data in memory. The memory usage would then be very minimal — under 5 percent of the data for that use case.
My friend was suspicious: “What kind of wizardry are you pulling here?!”
So since I am not a wizard (yet, I am still convinced my Hogwarts acceptance letter is on its way — I’m almost sure it’s just the owl delayed), I went ahead and created a modest demo cluster for him, just to show him my “magic”.
Aerospike Cluster: Hybrid Memory Architecture
In this next screenshot, we can see the result: a 6 node cluster, running 500K TPS: 400k reads + 100k writes, storing 1.73TB of data but only utilizing 83.45GB of RAM.
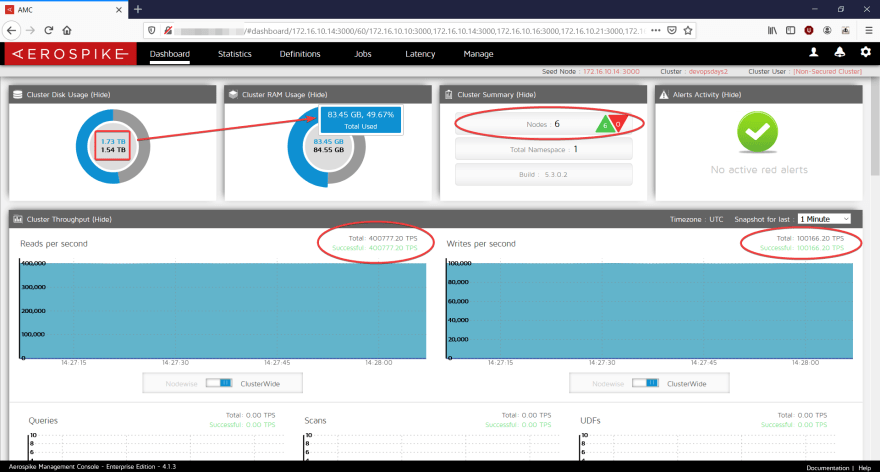 Running a 6 node cluster: 1.73TB of data, 84 GB of RAM
Running a 6 node cluster: 1.73TB of data, 84 GB of RAM
This cluster has not specialized hardware of any kind. It’s uses regular 6 nodes of AWS’ c5ad.4xl, which means a total of 192GB RAM and 3.5TB of ephemeral devices, cluster-wide. From the pricing perspective it’s only about 1900$ a month, way less than what they pay now (and I price-tagged it before any discounts).
Obviously, if the cluster as a total of 192GB of DRAM, the data is not being stored fully in memory. In this case 0 percent of the data was fetched from any sort of cache — so, for 1.73TB of data, the memory usage was under 84GB (even though the Linux kernel would allow for some caching if needed, which makes things even better when using other access patterns like common records, or read after write).
The cool thing is the performance. Predictable performance is something every application needs — and for the peaks described earlier, we can see in the next screenshots a latency of under 1ms for both reads and writes!
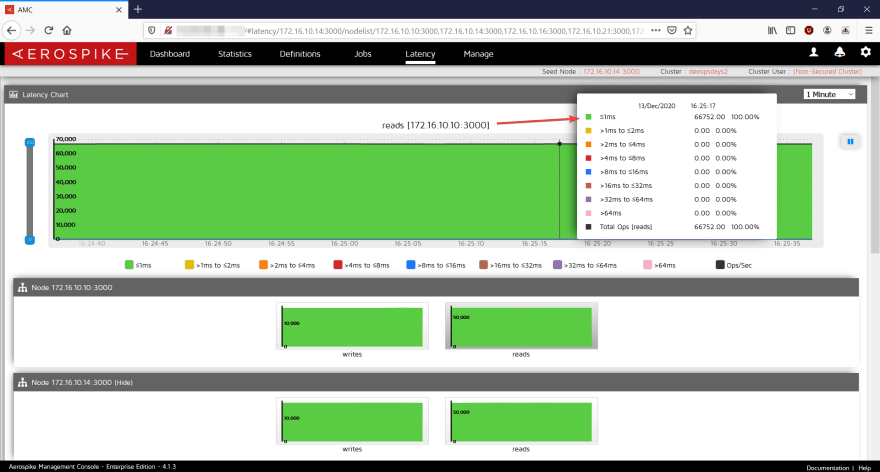
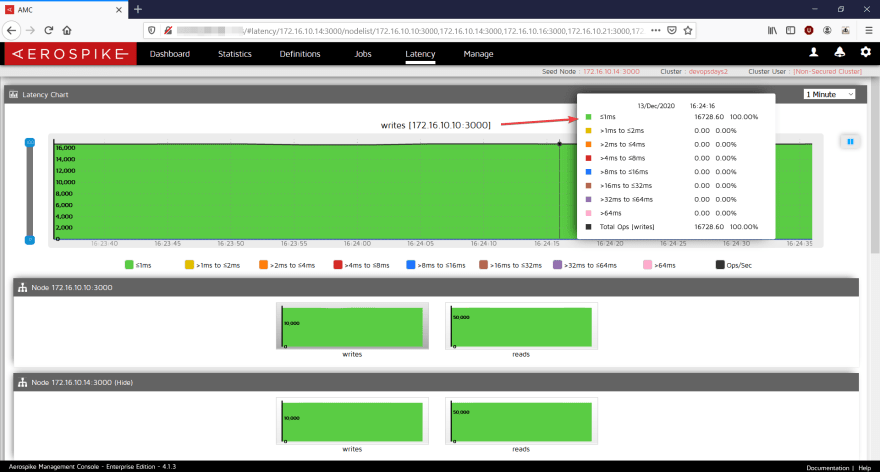 Reads and Write latency, on a mixed load, sub 1ms
Reads and Write latency, on a mixed load, sub 1ms
So, this is not trickery and not a magic show — Aerospike is different. It is utilizing a variety of registered flash optimization patents and a special architecture called “Hybrid Memory Architecture”. This mean the data is not expected to be stored in memory — it is stored on a flash device (SSD, NVMe, or Intel’s Persistent Memory) and the memory is only for storing the primary index (pointers) to where the data is actually is on disk. The data is evenly distributed between the nodes, so scaling up (or down, I don’t judge) is super easy.
 Data is evenly distributed, easy to scale
Data is evenly distributed, easy to scale
More Information
If you would like to learn more about this, feel free to contact me or read more about it in this summary link.
Originally published on my Linkedin.




Top comments (0)