
Check out the updated version here
Introduction
This second episode follows what we started here and will be about cache writing techniques.
Please Note
If you're looking for an introduction about caching in general and reading techniques, you can go here
What?! Writing techniques?!
I am still food drunk. GIMME THE CODE
I totally see your surprise here. In the reading techniques we already mentioned how and when to write to Cache Layer, so why in the hell do we have a set of different strategies here?
We are calling reading techniques those which are actually concerned with reading actions. For example, get a list of transaction. So, even though we already performed some writing, we were actually performing writing only to serve the purpose of reading actions.
So, writing techniques are basically strategies used during write actions to populate or update Cache. The biggest part of the benefits you get out of them is, again, when you are going to read data afterwards. Examples of writing actions are: create a new transaction, edit user info and so forth.
As mentioned in the other article, we are going to speak about these patterns:
- Write Through
- Write Behind
- Write Around
As last time, these are the participants:
- Client: who needs data;
- Cache: where you store data;
- Resource Manager: delivers resources to the Client;
- Data Accessor: fetches data from outside the application.
Write Through (aka Write Inline)
Exactly as for Read Through (or Cache Inline), we have the Resource Manager sitting in line between Client and Data Accessor.
This diagram illustrates the lifecycle of a writing action using Write Through
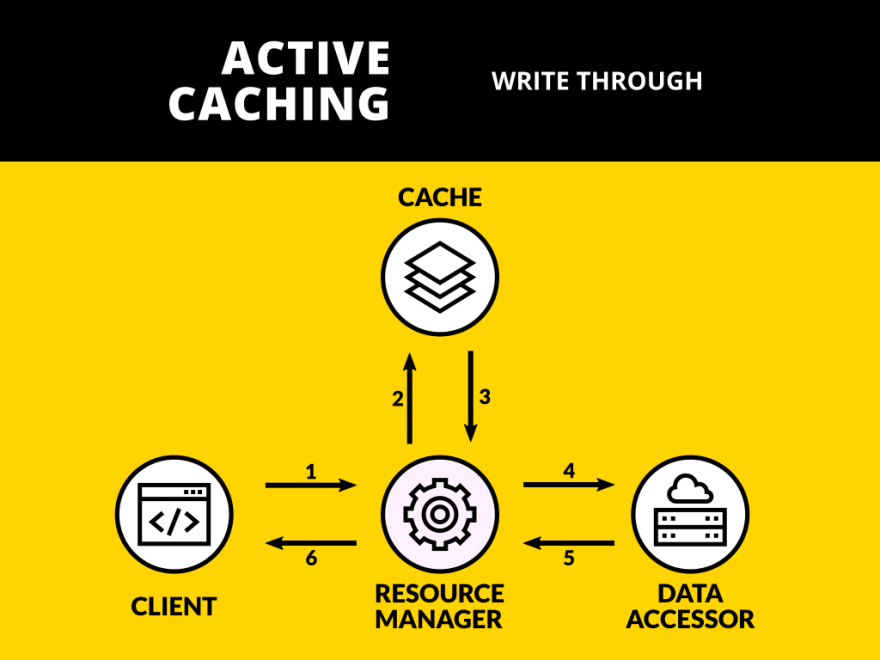
These are the steps:
- Client starts a write action calling the Resource Manager;
- Resource Manager writes on Cache;
- Resource Manager writes calling Data Accessor;
- Response is served to the Client.
Rationale
At first glance it doesn't look like the smartest move: we are in fact slowing down the request adding an extra step. What are we gaining from this strategy, then?
As we have said multiple times, one of the biggest problems with cached data is that they get stale. Well, this pattern solves exactly this problem.
In the other article we have seen that one way to deal with stale entries is using TTLs and that still holds true, but in that case expiration was the best way to solve the issue since we were not producing the data we were fetching. Now we are in control of data we want to read, then updating the Cache every time we write data will ensure that cached entries never gets stale.
Of course there is no light without shadows and besides the write latency1, this technique can turn detrimental when the Client doesn't need to read data that often. In this case in fact, you end up wasting the resources needed to keep alive and synchronizing the Cache without gaining the reading benefits.
Write Behind (aka Write Back)
This other technique still has the Resource Manager inline, but writing through the Data Accessor happens asynchronously.
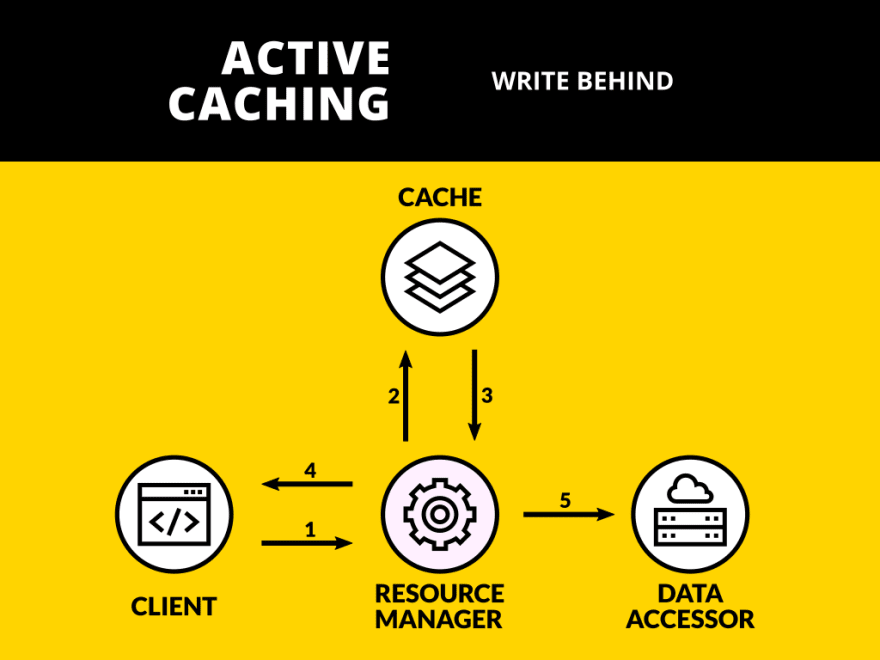
These are the steps involved in action life cycle:
- Client starts a write action calling the Resource Manager;
- Resource Manager writes on Cache;
- Response is served to the Client;
- Eventually Resource Manager writes calling Data Accessor.
Rationale
The best way to understand why and how this caching technique can be useful is to give an example.
Suppose we are now developing TrulyAwesomeBankAPI and we want to implement the Payment transaction creation using Cache. Payments need to happen as quick as possible, but Truly Awesome Bank backing our API is still on an old infrastructure which is not able to handle peaks very well.
We decide to use Write Behind. This means that every time we perform a Payment we save that transaction in Cache and return the response to the Client. Then we have another worker routine (running in background, in another process, based on a CRON expression or whatever...) which takes care of synchronizing our cached version of the ledger with the real ledger belonging to Truly Awesome Bank. This way we can provide responses quickly, regardless of how many requests Truly Awesome Bank is able to support at a given time.
We are then gaining on performance and stability, since we don't need to wait for external data sources. This makes the architecture on the whole more fault tolerant towards external services and thus opens new resilience possibilities: we could, for example, implement simple retry strategy or even a circuit breaker without affecting the client at all...
The price we are paying though is consistency: before worker completes the synchronization process real data (as in data living in Truly Awesome Bank) and data we serve (as in data living in the Cache) are different and the thing can get a lot more complicated if we start thinking about how to deal with error cases2.
Write Around
Well, just for sake of completeness we ought to mention Write Around, but to me it doesn't look like a real pattern. In fact, in the following diagram you won't find any trace of the word "cache".
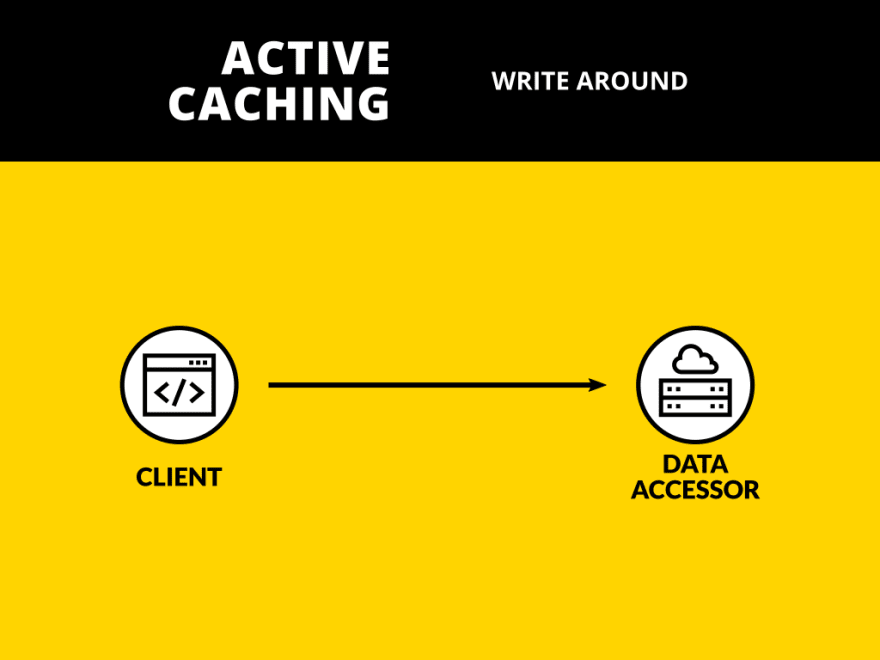
Basically, Write Around is "call directly Data Accessor and cache data only at read time" which to me means "apply any reading strategy without a writing one".
Rationale
The reason why you would use this non-pattern is just because none of the writing techniques above are good for you: maybe you need to have super consistent data or maybe you don't need to read data that often.
In those cases not applying a writing technique (or using Write Around, if you wish) works just fine.
Did you write some code?
You can find a more detailed version of these examples here
shikaan / design-patterns
Examples of usage of design patterns in real life code
design-patterns
Examples of usage of design patterns in real life code
These are the reference resources for this series of articles
Yes, I did. Python this time around.
The example I am providing here is simulating a slow writing external service using timers. In particular, we are about to simulate more or less what happens in TrulyAmazingBankAPI: we create a transaction we want to save.
Launch the app and in some seconds you are able to see exactly the trace of what happens during the Write Through and the Write Behind cases.
Let's examine the output case by case.
Write Though
>>> Save transaction
[14:59:17.971960] CacheManager.set
[14:59:17.971977] TrulyAwesomeBankAPIClient.save_transaction
>>> Get transaction
[14:59:19.974781] CacheManager.get
Here the first thing we do is saving the entry in the Cache, then we save it in the AwesomeBank and when after a couple of seconds we want to get the transaction we have just saved, we are using the Cache to retrieve it.
Write Behind
>>> Save transaction
[14:59:24.976378] CacheManager.set
>>> Get transaction
[14:59:21.978355] CacheManager.get
--------------------------------------------
| AWESOME BANK DATABASE (before sync) |
--------------------------------------------
{}
[14:59:26.974325] TrulyAwesomeBankAPIClient.save_transaction
--------------------------------------------
| AWESOME BANK DATABASE (after sync) |
--------------------------------------------
{
UUID('0f41f108-0859-11e9-a138-b46bfc6c5cb9'): {
'id': UUID('0f41f108-0859-11e9-a138-b46bfc6c5cb9'),
'transaction': {
'type': 'PAYMENT',
'amount': 100,
'currency': 'EUR'
}
}
}
If we call request the couple of actions "set transaction" and "get transaction", we can see from the output that during the whole life of the request the only involved participant is CacheManager.
The sole moment when we are calling the TrulyAwesomeBankAPIClient is 5 seconds after the end of the request, when we are completing the synchronization.
Please note that also the synchronization is a process purposely dumb and slow because of timers here. In real world synchronization process can be (and usually is) way more complicated than that and, in fact, it should be a major concern when data consistency is a game changer.
After synchronization, as you can see database is up to date with what we have in Cache. From this point on this entry is up to date and it will always be, until other writing actions happen.
Final words
Well, this closes active caching part.
First thing, thanks for feedback on previous article! Apparently naming wasn't so clear, so I updated it a bit here. I took the opportunity to revisit diagrams as well so that they won't make you eyes bleed. Not that much at least.
Please continue with feedbacks ❤
Until next time!
1. It's worth mentioning that users usually tolerate writing latency way better than reading latency. Unfortunately I can't remember where I got this data from, so I cannot show real metrics of this. Take this with a grain of salt.
2. These issues are all related to what is generally named "Eventual Consistency" and this is the reason why I used the word "eventually" in the last step of the action life cycle. The topic is big enough to deserve an article on its own, but you really want to get a grasp of what's going on check this out.





Top comments (0)