
Sometimes teams struggle to identify which technical debt items
are worth investing into, or how to align them to company goals.
We recently had some internal sessions to discuss this topic,
and we came up with a simple strategy to classify and measure
technical debt across teams, while having a chance to align it
with our product needs. Three article series about how to manage
technical debt in a simple and fun way
Three article series about how to manage technical debt in a simple and fun way
Introduction
Recently, I met with a team to share ideas about how they (engineering and product owners alike) could raise
awareness of the importance of their tech-debt, but also how to take ownership of it.
For some reason, this team had heavy churn, and the engineers could not find a way to remove or tackle their pain
points during their sprints.
With other team members, we had already identified some items in various repositories and services, but we had
not been able to onboard everyone on the importance of them. For example, there were some code smells, some
services had tons of legacy code (with few tests or no documentation) and other stuff that usually is considered
technical debt.
The most senior or historic engineers on the team did not consider lack of documentation or tests as technical debt
(after all they were the technical experts and owners of the repositories), but the product owners were seeing some
slowness onboarding new engineers on the team.
On the other hand, the product owners had not noticed some technical deficiencies (or if they were they thought there
was almost no impact) as technical debt, but the engineers were not happy with some old tools, libraries and patterns
used.
Although when reading the above examples it might be clear a relationship exists between the pairs, it needed external
feedback to make the whole team aware of it.
It was not a problem of communication between engineers and product owners, it was just that they were not able to align
themselves nor see the impacts of each other's worries or the relation with parts of their code.
So we gathered together again, this time hands-on to try to find the best approach to the problems they were facing:
- How to identify if something was really tech-debt or just a false positive
- How to measure the impact of each tech-debt item
- How to reach consensus within the team (including product owner) that a given piece of software needed some love 😍 ♥️ ♥️ ♥️
Basically we were going to observe, measure impact and raise awareness.
The first iteration
We tried to start small, with specific examples and use cases, in order to then iterate over them trying to find
generalizations.
So we started with a very basic question:
What things do we have that we believe are tech-debt right now? (aka what are our current pain points?)
We identified some of them (and left some for the next iterations):
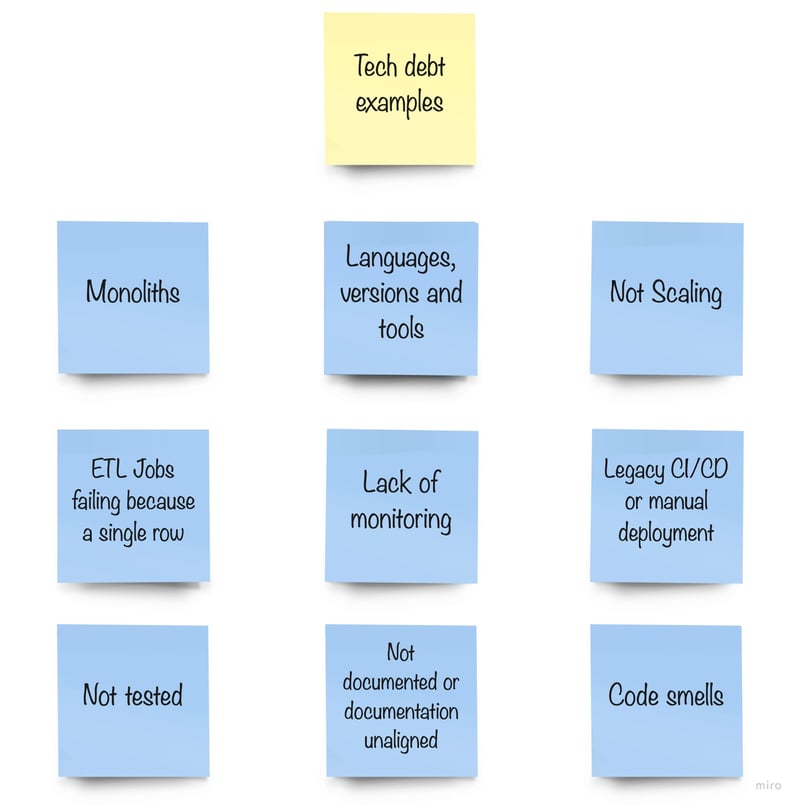
We intentionally left some stuff aside as at this point we already began to discuss that some pain points were
consequence of others; for example, slow onboarding was a direct consequence of not having good enough documentation.
We decided to follow that line of thought (consequences and impacts) later on, instead focusing at that moment on extracting
common information from our items by grouping or classifying them.
In order to classify something, you need a criterion. Our criteria were not clear then but became clearer when
we saw the impacts, much later on. At this stage we just tried to group it, and we saw some
"architectural deficiencies", some "things related to production" and finally other stuff related to
"how fast and happy the team was" while working on certain repositories.
We used the initials A, O and S to tag our items:
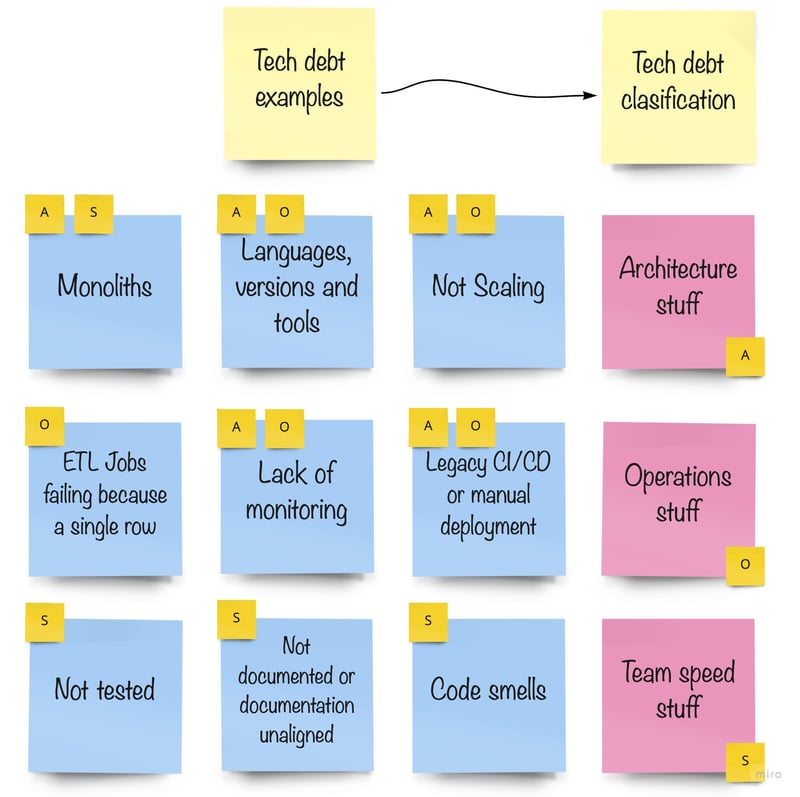
We had reached a stage where we could simply add some tags to given tech-debt items that gave some inspiration to
categorize them, but most importantly, we were able to extract the impact.
Effectively, how we were categorizing an item told us about its impact.
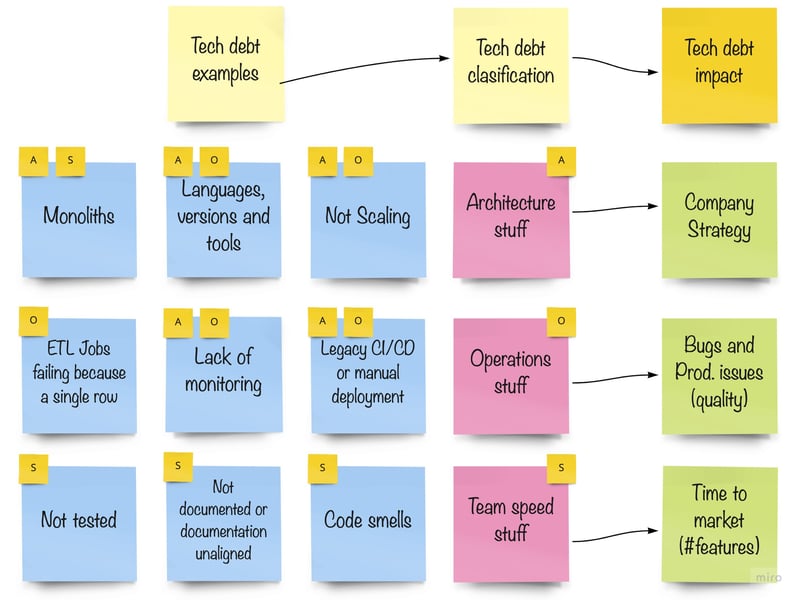
Retrospective
This very first iteration was so powerful! We were really happy, as this gave us great insights but also offered
opportunities to establish some technical debt goals within the team. We could focus on specific themes (using the
impact) according to the upcoming user stories and thus was a great way to align everyone, from product to engineering,
into dealing with technical debt.
We did a small retrospective, and we all agreed that while it was powerful to raise awareness, we could benefit even more if
we dug deeper on the framework we were creating.
Some examples
Let's say there are new features involving integrating with third parties that will consume our fancy new API, that was
just built in a hurry for a PoC, in the next quarter. We had identified some tech debt related to speed on that part of
the codebase, like not enough tests, documentation, or some code that needs refactor because it was just a PoC.
We know that this will impact the time to market, so we can anticipate and just focus as a technical goal for the sprints
to "improve the time to market for new API features" while working on the user stories. Focusing only on that goal (for
example omitting any big architectural refactor) we could tackle our codebase at the same time we were delivering new
value.
Maybe our Company is expecting a peak in our # of requests because of some sales goals (go sales, 💰 go!),
and we need to focus on improving our operations stuff, like monitoring, scaling or making the jobs resilient and
parallelizable. This way, we could introduce technical parts to the user stories (for example, the big architectural
refactor that we omitted before) that were aligned with the company goals or certain user stories.
Technical Debt
What is Technical Debt
How do we know that something is technical debt? Because we are afraid to work on it. Or because it hinders product
development by not being able to achieve the speed we want. Or maybe because it breaks too much. Or it is not aligned with
the company strategies...
Sounds familiar? Basically it is what the second image above illustrates: Team Speed Stuff, Operations Stuff and Architecture
Stuff. In other words:
- Techdebt doesn't allow product owners to deliver features at the speed they want: It slows development teams
- Techdebt are also pieces of software that we cannot maintain any longer (obsolete technology, tools or lack of experts): it is not aligned with company strategies
- Techdebt is also present when some products break too often or even don't work as expected: products already running in the company that have a high operational cost
Basically, it is a slow poison, draining resources from the company or increasing the cost to deliver new value.
What is the formal definition?
From Wikipedia:
The formal definition states that technical debt reflects the implied cost of additional rework caused by choosing an
easy (limited) solution now instead of using a better approach that would take longer. Technical debt can be compared
to monetary debt. If technical debt is not repaid, it can accumulate 'interest', making it harder to implement changes
later on. Unaddressed technical debt increases software entropy. Technical debt is not necessarily a bad thing, and
sometimes (e.g., as a proof-of-concept) technical debt is required to move projects forward.
From: Martin Fowler:
Software systems are prone to the build up of cruft - deficiencies in internal quality that make it harder than it
would ideally be to modify and extend the system further. Technical Debt is a metaphor, coined by Ward Cunningham,
that frames how to think about dealing with this cruft, thinking of it like a financial debt. The extra effort that
it takes to add new features is the interest paid on the debt.
At this point we could use one of the wide known definitions of tech debt, but we decided to go with our own.
Why would we change it?
Simply, because software engineering has evolved a lot since the first of those definitions were introduced back
in 1992 by Ward Cunningham.
Now we use infrastructure as a code, microservices architecture, CI/CD, agile philosophy, and evolved technology stacks,
some of which were born just a couple of years ago and give a competitive advantage over old ones.
We have seen stacks rise and fall since then, and using those dead stacks was not considered technical debt at the time,
they were state of the art.
We consider that anything in engineering that induces a cost for the company to grow, deliver or build new features is
technical debt, be it new developments or things already in production.
From architecture to code but also, culture and training.
The above definitions define technical debt when the software is created, not when the environment changes.
This was our amendment to the classic technical debt definitions:
We do not consider technical debt only stuff made consciously, but also things made some time ago which needs
reconsideration based on current software engineering standards, tools and technology,
but also on updated company strategy and needs.
This updated definition helped us to revisit our projects periodically to make sure they are aligned with company
strategy but also helps us to deprecate things we are going to evolve when their stacks become obsolete.
How technical debt is born
Technical debt is not only born in the code. This is one of the biggest mistakes that startups make when thinking about
it. This also happens in established companies. According to our definition above it can be born in different ways.
Let's explore some examples:
- A stakeholder meeting establishing a plan for the company to duplicate clients or traffic will spawn a bunch of technical debt items to optimize performance, allow scalability or other evolutions that are needed to achieve that goal. Especially if scalability was not important for some services previously, and thus their architecture was not focused on that.
- Our company is not yet ready to use fully automated CI/CD pipelines, and we have some manual QA testing, and some teams keep detecting in their retrospectives that there is a problem there, needing additional environments or just evolving the pipelines and training the team to help them automate those tests.
- A new technology spawning in our market that gives an advantage to competitors and forces the company to switch to it, evolving architectures or tools, or just because there is a lack of engineers working in our previous technology stack.
- A merge is happening with another company, and we need to improve our ability to integrate with them, by improving our documentation, APIs and standardization.
- A library we were using in the past suddenly gets a new major version and drops support and compatibility with the previous one. While dead (maintenance mode) projects could keep using the library, keeping it on live/active projects could trigger a problem in the near future.
- A quick bug fix that did not pass a proper code review gets forgotten in the codebase. Also, this bug fix has unforeseen consequences
- ...
I stumbled recently upon this blog entry Intentional Qualities
from Roman Elizarov and would like to highlight a couple of paragraphs there:
See, the fact is that you cannot accidentally write a software that has a specific quality.
You cannot accidentally write fast code. Your code cannot be secure by an accident.
Accidentally easy to learn? Never heard of it.
[...]
Qualities are often lost by an accident, but are never accidentally acquired.
It is similar to the second law of thermodynamics. In order to maintain quality you have to be very conscious,
intentional about it. You have to constantly fight against losing it.
I love that statement! You can start writing code that follows a target (secure, fast, easy to learn or maintain) but
several iterations later, it only needs one small commit not focused on that -ility, and the code is not longer
secure, fast or maintainable.
As a recap, these are five examples of technical debt appears:
- At any time (dev, test, prod), detecting something that was not detected before (third party library bug, side effect...)
- During development, as a conscious decision or consensus in order to achieve a given goal faster (PoC or other)
- During development, by mistake (i.e. losing one or more of our software qualities)
- Because new needs / company goals turns something into not-ideal / not good enough / not aligned
- Because new tools / technology / patterns emerge that solves problems in a different and more efficient way
We never consider our bugs technical debt items (unless they become a feature),
but we might consider third party bugs, problems or missing features and other external things that we might need to invest
time into as technical debt if left unattended.
The second iteration
As a recap of our exercise above after the not-so-brief retrospective, we had already identified some tags (A, O, S) and
the impact of some technical debt items.
We had a starting point, and the feeling of being in the right path.
We started to look for existing standards about the tags we were using on our tech-debt items, but we were also aiming
to keep this simple enough to make it broadly used in the company.
I already mentioned early the Software Architecture -ilities (check some videos about them from Neal Ford
or Mark Richards), so we started straight with their recommendations.
Something was going to be tech-debt and not just false positives if it was lacking any of the important -ilities
for the company or team on a given point in time (important -ilities change overtime as company goals and tools
evolve).
There are some frameworks and acronyms that try to classify software according to their -ilities, like ACID
for transactions, RAS for operations,
FURPS for requirements...
We were inspired by them, and we decided to group the list of -ilities that were important for the company into one
or more of the categories we already had identified.
In the next entry of this series, we will
introduce an evolved version of this framework by further defining and grouping those illities,
while in the last entry of this series we will
dive deeper by using it to help not only the teams but also the company to make better decisions, to react to
changes and to reach its goals.
Originally published at Corner in the Middle
Also available at Medium
This post could not have been possible without some awesome coworkers





Top comments (0)