
Here’s a practice I use personally and encourage within my open source projects and any small teams I run for work. I’ve seen major elements of it presented under a few different names: Short-Lived Feature Branch flow, GitHub flow (not to be confused with GitFlow), and Feature Branch Workflow are some. Having implemented features I like from all of these with different teams over the years, I’ll describe the resulting process that I’ve found works best for small teams of about 5-12 people.
A protected main branch
To support continuous delivery, no human should have direct push permissions on your master branch. If you develop on GitHub, the latest tag of this branch gets deployed when you create a release – which is hopefully very often, and very automated.
One issue, one branch, one PR
You’re already doing a great job of tracking future features and current bugs as issues (right?). To take a quick aside, an issue is a well-defined piece of work that can be merged to the main branch and deployed without breaking anything. It could be a new piece of functionality, a button component update, or a bug fix.
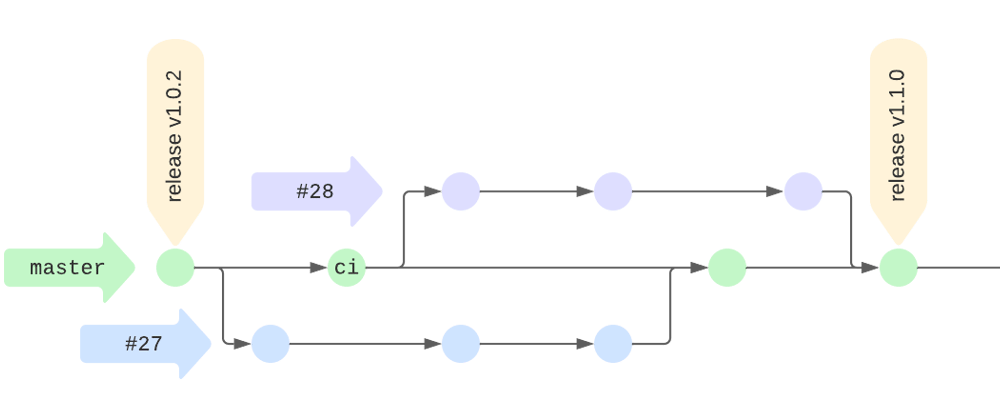
Author's illustration of issue branches and releases from master.
A short-lived branch-per-issue helps ensure that its resulting pull request doesn’t get too large, making it unwieldy and hard to review carefully. The definition of “short” varies depending on the team or project’s development velocity: for a small team producing a commercial app (like a startup), the time from issue branch creation to PR probably won’t exceed a week. For open source projects like the OWASP WSTG that depends on volunteers working around busy schedules, branches may live for a few weeks to a few months, depending on the contributor. Generally, strive to iterate in as little time as possible.
Here’s what this looks like practically. For an issue named (#28) Add user settings page, check out a new branch from master:
# Get all the latest work locally
git checkout master
git pull
# Start your new branch from master
git checkout -b 28/add-settings-page
Work on the issue, and periodically merge master to fix and avoid other conflicts:
# Commit to your issue branch
git commit ...
# Get the latest work on master
git checkout master
git pull
# Return to your issue branch and merge in master
git checkout 28/add-settings-page
git merge master
You may prefer to use rebasing instead of merging in master. This happens to be my personal preference as well, however, I’ve found that people generally seem to have a harder time wrapping their heads around how rebasing works than they do with merging. Interactive rebasing can easily introduce confusing errors, and rewriting history can be confusing to begin with. Since I’m all about reducing cognitive load in developers’ processes in general, I recommend using a merge strategy.
When the issue work is ready to PR, open the request against master. Automated tests run. Teammates review the work (using inline comments and suggestions if you’re on GitHub). Depending on the project, you may deploy a preview version as well.
Once everything checks out, the PR is merged, the issue is closed, and the branch is deleted.
Keep it clean
Some common pitfalls I’ve seen that can undermine this flow are:
-
Creating feature branches off of other feature/issue branches. This is a result of poor organization and prioritization. To avoid confusing conflicts and dependencies, always branch off the most up-to-date
master. - Letting the issue branch live just a little longer. This results in scope creep and huge, confusing PRs that take a lot of time and mental effort to review. Keep branches tightly scoped to the one issue they’re meant to close.
-
Not deleting merged branches. There’s no reason to leave them about – all the work is in
master. Not removing branches that are stale or have already been merged can cause confusion and make it more difficult than necessary to differentiate new ones.
If this sounds like a process you’d use, or if you have anything to add, let me know in the comments!





Top comments (35)
UNIX mindset.
I think branches that take time and diverge from the main branch are always problematic. There are best practices and software to resolve conflicts, and regular merges from master can ease the pain, but, in my experience, it's often time-consuming, especially when there are lots of contributors and workflows on the same app.
All the points you mentioned, like having a good naming convention and stick with it or delete merged branches, are critical.
For old branches, it occurred to me that some organizations like to keep them for various reasons I won't mention here, but if you have lots of branches, it will impact the size of repo for sure, which may impact CI/CD processes as well.
Tags are really handy to contextualize.
Did you use
filter-branchfor cleanup? What strategies did you use?I started by removing lots of unused old branches and tags. I extracted all heavy files that had nothing to do with the git workflow.
Yes,
filter-branchwith an additional option I don't remember to ignore some commits like delete commits.I made a full backup before all operations, as it's kinda risky even when you know what you're doing. After some time, it was possible to get rid of the backup.
That matches things I've done in the past too. Thanks for all the answers.
Also, what were repository sizes at which CI/CD started to be impacted? In which case, what was the checkout strategy you used on the CICD builders?
Lots of useless hundreds of MB ^^. I did not use any checkout strategy, I cleaned the repo.
You may experience such configuration when cloning famous open-source projects without a high-speed connection.
Was this because of larger files in the repository? delta-compressed gzipped text-source blobs are usually ridiculously small. But I get your point. At my last gig the monorepo was around 1.5 GB big, which was still manageable. For another big repo (which had a fair amount of binaries because of the app itself, and we had bad experience git-lfs), we used a separate "single clean history" for CICD purposes
various causes but, yes PSD, etc, without LFS, also years and years of commits + some libraries added "as is" without package manager.
how? another repository with the builds?
Exactly. Do normal development on the main fork. Then when a build needs to be made, squash push to the other fork. I'm not sure exactly how we scripted cutting off the history to avoid "blowing" up the other repo, but there was a check in place.
It's a valid approach, but the only inconvenience is indeed the scripting part, as you have take all edge cases into account.
this happened after I was less involved with that one project inside the company. I would probably have tried to rewrite some of the history, but I'm not sure how badly it would have impacted say, the JIRA <> github referencing, exicting pull requests, which is information I would have liked to keep. Maybe noone ever uses that information either, who knows.
hum, dunno how it could impact hosting providers. I would say you cannot erase everything unless you remove the entire repo, but I'm not sure. In doubt, I recommend asking questions to everyone involved in the process, including "non-technical" people, to determine what should be kept.
What do you think takes time in branching?
naming lol, sometime my developers take a lot of time to think about naming
Pretty good sign. Naming is a critical step!
Longlasting branches take time. You sometimes have to handle lots of conflicts especially with dependencies or recipes, possibly migrations, etc.
I would one more thing: branch naming conventions, e.g.
feature/28-add-settings-pageorbugfix/issue-28. This can easily be enforced with Git Hooks and in case of Node, with packages like enforce-branch-nameVoted for this. Protected branch is really essential for centralized workflow like this. Github didn't have this in the beginning (now it has) and it made us moved to bitbucket. It really headache when everyone has to fork the repo because we can't allow them write access to the main repo.
makes sense. my background is in embedded where branches i guess have more reasons to exist than in a CICD setup. We usually have sidebranches trigger integration tests however. Every commit pushed gets run.
locking down main is the best thing you can do for any team. we are all human and make mistakes. I often hit the protected branch error and think "whew that was close, glad its protected".
I've worked in very similar workflow to this and it's the best thing I've learned from my coworkers. We used a develop branch rather than master, and master was our release branch. Only the most stable and thoroughly tested software was merged to master, which was also when we released software to clients. We've also made sure to always make a code review before merging to develop branch and that made our codebase so much cleaner, the workflow faster and less prone to bugs.
After experiencing different approaches I'm never letting go of that workflow and I try to introduce every team I work with to it.
Thank you for such a great write up, I'll be able to show it to my co-workers :D
My last post on git got a lot of attention, which led me to start thinking a lot about how people understand git, use them in their workflow. I started gathering a list of questions that I would like to send out as a questionnaire. I would love some feedabck about the questions themselves, and if you can think of other interesting questions to ask:
gist.github.com/wesen/26982b2c7e16...
I use a very similar flow, although I often try to rebase the feature branch instead of merging in master. I will sometimes resort to merging in master when rebasing is just too confused and multiple merged features interact with the work done on the side branch.
If no feature touched a similar area, rebasing is of course trivial. If some slight conflicts occured, this means a few conflicts, and it makes to review them by hand and figure out what is going on. If things are really bad, it's time to stop, consider why the conflicts happened at a team workflow level (why were multiple people working so heavily on the same code area without coordination).
Very good stuff
Thanks for posting
Great article.
Branching can be hell.
The faster code is in the master, the better.
What do mean by hell exactly in this context? (I'm working on an article where I try to understand why people adopt different workflows, and what their experiences with source control are). My latest article got so much engagement that I realized there is a lot to talk about here.
Is that to save the effort to create a branch and code review?
Awesome post
To avoid swapping branches when merging master, I tend to do this instead:
Excellent read