
Chess is a great game. It’s even better if you’re good at it. Regrettably, I’ve never taken the time to learn chess strategy, so I decided to rely on the power of computation and game theory instead! As a fun side project, I have implemented a simple chess AI using JavaScript.
You can find the full source code for this tutorial in my GitHub repository.
The final product is playable at https://zeyu2001.github.io/chess-ai/.
](https://res.cloudinary.com/practicaldev/image/fetch/s--yQLYnGdd--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1.medium.com/max/2000/1%2Aj9HpWMAOCHXL5HuIV6IMzg.png)
Prerequisites
You should know basic programming and the general concept of a tree data structure. Everything else will be covered as part of this tutorial.
The two main algorithms involved are the minimax algorithm and alpha-beta pruning. These will be explained in-depth later on, and should be relatively simple to grasp if you have experience in programming.
First Things First…
Getting the GUI and game mechanics out of the way. This allows us to direct our focus towards only the most fascinating aspect of the application: the decision-making (AI) part! For this, we will be using external libraries:
chessboard.js handles the graphical interface, i.e. the chess board itself.
chess.js handles the game mechanics, such as move generation / validation.
With these libraries, you should be able to create a working chess game by following the examples (5000 through 5005 in particular) on the chessboard.js website.
Evaluation Function
Great! We have a functioning chessboard. But how do we implement an AI that plays (reasonably) good chess? Well, we’re going to need an evaluation function. Basically, we want to assign a ‘score’ to each chessboard instance (i.e. each set of positions of pieces on the board) so that our AI can make decisions on which positions are more favourable than other positions.

A Zero-Sum Game
Chess is a zero-sum game. Any advantages gained by Player A implies disadvantages for Player B. Advantages can come in the form of capturing opponent pieces, or having pieces in favourable positions. Therefore, when assigning a score from our AI’s perspective, a positive score implies an overall advantage for our AI and disadvantage for its opponent, while a negative score implies an overall disadvantage for our AI and advantage for its opponent.
A Simple Example
For instance, the score for the starting position is 0, indicating that neither side has an advantage yet. Later on into the game, we are faced with a decision between two moves: Move A and Move B. Let’s say Move A captures a queen, putting our score at 900, while Move B captures a pawn, putting our score at 100.
The AI will be able to compare between the two potential scenarios, and decide that Move A is the better move. Of course, this does not consider future ramifications — what if Move A gives our opponent the opportunity to attack? We will overcome this hurdle in the following sections by performing lookahead to anticipate subsequent moves.
Piece Weights
The first aspect of our evaluation involves assigning weights to each piece type. If our AI plays from black’s perspective, any black pieces will add to our score, while any white pieces will subtract from our score, according to the following weights:
Pawn: 100
Knight: 280
Bishop: 320
Rook: 479
Queen: 929
King: 60,000
Piece Square Tables
We now have a score based on which pieces exist on the board, but some positions are more favourable than others. For instance, positions that grant higher mobility should be more favourable. For this, we use *piece square tables *(PSTs), which assign an additional score delta to each piece based on its position on the board.
For instance, the PST for knights encourages moving to the center:

This is from white’s perspective, so it would have to be reflected for black.
I certainly am not a chess expert, so the piece weights and PST values are adapted from Sunfish.py. The following is my implementation of the evaluation function. Note that instead of iterating over 64 squares for each evaluation, we simply start from 0 and add or subtract from the score according to the latest move, keeping track of the previous score.
Minimax
Now that we have an evaluation algorithm, we can start making intelligent decisions! We will use the minimax algorithm for this, and I highly recommend reading up on the Wikipedia article to better understand this decision strategy.
Game Tree
We can represent chessboard positions as nodes in a *game tree. *Each node is a chessboard instance, and has children corresponding to the possible moves that can be taken from the parent node.

Minimizing Losses
Essentially, minimax aims to minimize the possible losses, assuming both players are rational decision makers. We can represent the possible moves as a game tree, where each layer alternates between the maximizing and minimizing player. We are the maximizing player, attempting to maximize our score, while the opponent is the minimizing player, attempting to minimize our score.
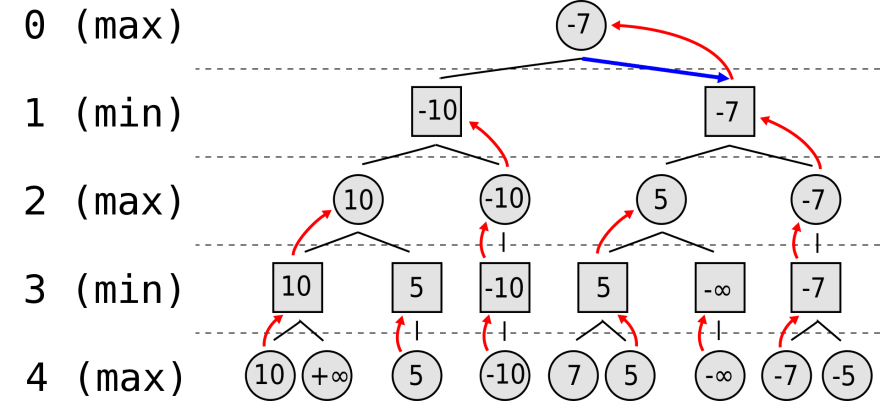
At the leaf nodes, the evaluated score is backtracked. Positive and negative infinity are wins and losses respectively. At each recursive layer, the maximizing and minimizing roles are alternated. Layer 0 is the current game state, and the goal is to maximize our score.
Alternate Moves
The question our AI has to answer is: “Out of all the possible moves at Layer 0, which guarantees the maximum score?”
This is the same as asking, “Assuming my opponent is always making the most optimal decisions, which move leads to the possibility of attaining the best possible score?”
If we want our AI to be any decent at chess, we would have to perform a lookahead to anticipate our opponent’s subsequent moves. Of course, we can only anticipate a couple turns in advance — it’s not computationally feasible to look ahead as far as the final winning or losing states. We will have to introduce a depth limit that corresponds to the number of turns we are willing to look ahead, and use our evaluation function to determine the favorability of game states once we reach the depth limit.
The Algorithm
This is a fun recursion problem, and I recommend trying to implement it yourself, although my implementation can be found below. If you're stuck, here’s the general idea:
We decide on a predetermined depth limit, k.
At Layer 0, we consider each of our possible moves, i.e. child nodes.
For each child node, we consider the minimum score that our opponent can force us to receive. Then, we choose the maximum node.
But to know the minimum score that our opponent can force us to receive, we must go to Layer 1. For each node in Layer 1, we consider their child nodes.
For each child node (possible move by our opponent), we consider the maximum score that we can achieve subsequently. Then, the minimum score that our opponent can force us to receive is the minimum node.
But to know the maximum score that we can achieve subsequently, we must go to Layer 2.
And so on…
At Layer k, the final board state is evaluated and backtracked to Layer k - 1, and this continues until we reach Layer 0, at which point we can finally answer: “What is the optimal move at this point?”
Here’s my implementation. Note that I used a slightly modified version of chess.js, which allows me to use game.ugly_moves() and game.ugly_move() to generate and make moves without converting them to a human-readable format, improving the efficiency of the algorithm. The modified version can be found here, but using the normal game.moves() and game.move() will work just fine too.
Alpha-beta Pruning
Our AI should now be able to make reasonably good decisions. The higher the search depth, the better it will play. However, increasing the search depth drastically increases the execution time. Alpha-beta pruning helps to improve the algorithm’s efficiency by ‘pruning’ branches that we don’t need to evaluate. An additional reading resource can be found here.
Core Idea
The core idea of alpha-beta pruning is that we can stop evaluating a move when at least one possibility has been found that proves the move to be worse than a previously examined move.
Suppose that the game tree is as follows:
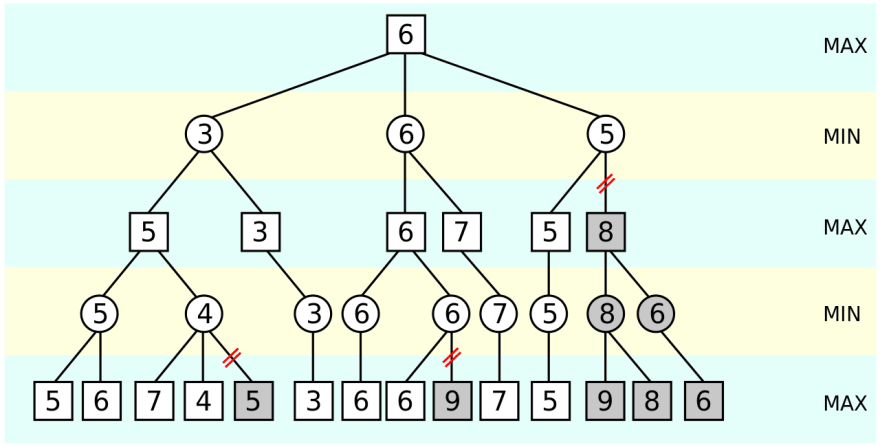
For brevity, let’s consider the following subtree:
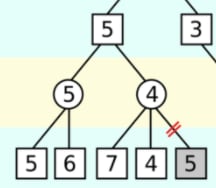
The maximizing player first considers the left child, and determines that it has a value of 5. Other paths will only be chosen if their value is x > 5.
Next, the right child is considered. The minimizing player, at the right child, has found the values 7 and 4 so far. But then this means that regardless of what the remaining value is, the minimizing player would end up with a minimum value of at most 4. We know the final value of this subtree would be x <= 4, regardless of the remaining value.
In order for this path to be relevant, x > 5. But we know that x <= 4. This is a contradiction, so the maximizing player wouldn’t choose this path and there is no point evaluating this path further.
The Algorithm
The same idea can then be extended to the rest of the game tree. We use two variables, alpha and beta, to keep track of the maximizing and minimizing values (5 and 4 in the previous example) respectively. This only requires minor modifications to the previous minimax function — see if you can implement it yourself!
Here’s my implementation:
Conclusion
That’s all! I hope you have enjoyed reading this article as much as I have enjoyed writing it. I’ve explained how I implemented my AI, and hopefully introduced several new and interesting concepts to you.
I’ve also implemented some other features, including pitting the AI against itself. You can play it at https://zeyu2001.github.io/chess-ai/, and refer to my GitHub repository for the implementation.





Top comments (15)
var?????
man this is 2020. almost 2021. come on!
cheers
I've taken Kyle Simpson's (Of You Don't Know JS) course and he has a lot to say about
varvslet/const. I don't agree with his thoughts, but it did gave me pause.His stance is that he uses
varpretty often and the problems people actually had versus what TC39's specified isn't solving the real problems.Again, I'm not super in agreement. But I definitely jumped off the bandwagon of declaring var as evil, and everything should be let/const. I wish I could find a public blog post where he articulates it better. But it's one (of his many) frontend master courses where he goes on that rant.
I'm working in the industry for 8+ years, writing frontend & backend javascript every day - all day since I've been taught.
I cannot mention enough how evil & unpredictable var can be. Especially if your team has a junior or two, it is guaranteed that var will lead you to problems.
I recommend you to replace them. Scoped variables are your friends.
If you insist to use var, I'm gonna tell you "I told ya"
I'm not disagreeing with you. And I can point to my industry experience as well if you want to go there. I'm simply sharing a perspective that made me reconsider my own stance.
And again, I disagree with a lot of his perspectives - but this one was something that made me ponder. Kyle Simpson also points out the reasoning for why he came about that, and I wish I could find the spot in his lecture. It was a fascinating perspective to say the least.
LOL
This is awesome and well written 😉
Next up: Go 👀
Maybe a rewrite in Go lang for faster results :D
Yeaaaah, about that :D
One implementation that I would use to further improve the evaluation is instead of randomizing the moves is arranging them intelligently, in general, moves of pieces with higher values are better, as well as moves that give checks, arranging this could improve even more the execution
Good explanations.
But, I think that as the king can't be taken (the game is over on the previsous move), there is no need to set a high score for the piece. If you set it to 0 it is the same.
He has to so the AI minimax algorithm prioritizes the king
epic🙌
Awesome!
Good... Thank you
learning a lot!, thank you