
1.Introduction
With the rapid evolution of computing systems, the need for a fast, scalable, and fault-tolerant messaging system has grown significantly. Apache Kafka has emerged as one of the most powerful and widely used messaging systems, providing a highly efficient way to process large volumes of data in real time. Without requiring massive computational resources, Kafka can handle thousands of messages per second with minimal latency, making it a preferred choice for major tech companies like LinkedIn, Twitter, Mozilla, Netflix, and Oracle.
Modern businesses rely on data to understand trends, analyze customer behavior, and automate processes. Kafka plays a crucial role in real-time data processing and predictive analytics by reducing the time between event registration and system response. Originally developed by LinkedIn in 2011 as an open-source project, Kafka was later acquired by Apache and is now further developed by Confluent, founded by Kafka's original creators: Jay Kreps, Neha Narkhede, and Jun Rao.
Kafka's core philosophy revolves around treating data as a continuous stream rather than static storage. This approach is particularly useful in machine learning, security monitoring, and real-time video analytics, where data needs to be processed and responded to instantly.

1.1 Messaging Systems
Messaging systems facilitate communication between applications by transferring data asynchronously. They are categorized into two main types:
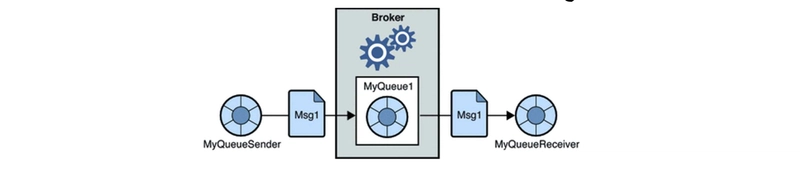
1.1.1 Point-to-Point(Queue-Based Messaging)
A producer sends messages to a queue, where a single consumer retrieves them.
Once consumed, messages are removed from the queue.
If the consumer is unavailable, the message remains in the queue until it is processed.
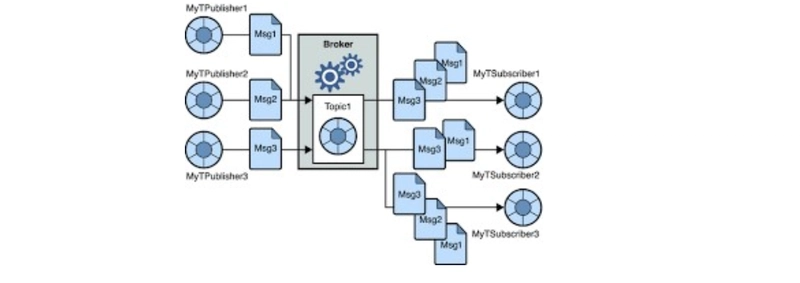
1.1.2 Publish-Subscribe (Pub/Sub)
A publisher sends messages to a topic, which multiple subscribers can read from.
Subscribers must be available to receive messages, or they may be lost.
Unlike the queue model, messages are not deleted after being read by one subscriber.
1.2 Apache Kafka Concept
Kafka is a distributed, real-time streaming platform designed to handle millions of messages per second. It processes continuous data streams by collecting, storing, and distributing records efficiently across different consumers.
Kafka offers three key functions:
- Message Publishing & Subscription: Stores and distributes records sequentially, ensuring reliability.
- Fault-Tolerance: Ensures system stability even in case of failures.
- Real-Time Processing: Supports instant processing of high-speed data streams.
1.3 Why Use Kafka?
Traditional messaging systems often face challenges like high latency and message buildup under heavy traffic. Kafka addresses these limitations with a modern, robust design that offers:
- High-throughput message storage that's both scalable and efficient.
- Fault-tolerant architecture that ensures no data is lost, even during failures.
- Real-time data streaming for instant processing and analytics.
- Unified platform that seamlessly combines messaging, storage, and stream processing.
1.4 Kafka Workflow
Even though publish-subscribe (pub/sub) and queuing are different messaging patterns, Kafka combines both to support various use cases. Sometimes, Kafka functions as a traditional topic-based pub/sub system, where data is sent to topics as a continuous stream of records. These records are structured in a sequential and ordered manner, and multiple subscribers (consumers) can process them independently.
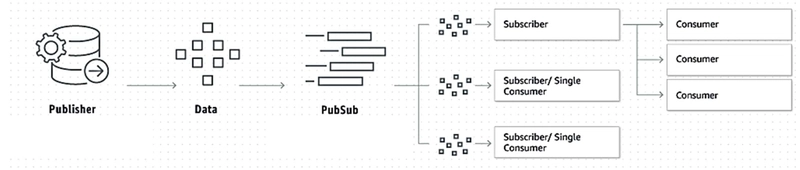
1.4.1 Pub/Sub
In the pub/sub model, an application (the producer) connects to Kafka and publishes messages to a topic. Kafka stores these messages in a structured log that is divided into partitions (segments). Multiple consumers can subscribe to a topic, and Kafka ensures that each consumer gets assigned a specific partition. When another application (consumer) connects, it reads and processes records from its assigned partition.
1.4.2 Queuing
In the queuing model, both producers and consumers connect to Kafka in a similar way. However, unlike pub/sub, queuing ensures that each message is delivered to only one consumer for processing. Messages are stored in a queue until a consumer retrieves them.
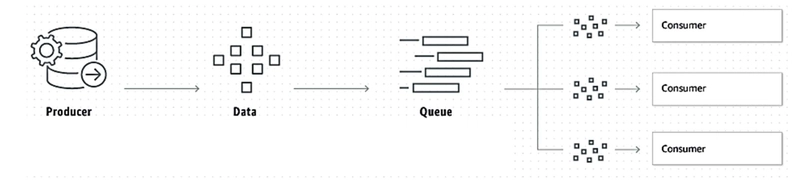
A key characteristic of this approach is that it does not support multiple consumers processing the same message simultaneously on a single machine. This design is ideal for workloads where requests need to be processed in a sequential manner rather than being handled simultaneously by multiple consumers.
For instance, in large-scale machine learning (ML) applications, requests are often processed one after another and then stored in a queue before being passed to the next stage. Since ML workloads can be computationally heavy, handling requests in a sequential pipeline ensures better resource utilization. This is where Kafka’s consumer API plays a crucial role in managing and distributing these workloads efficiently.
1.5 Kafka Cluster Architecture
Kafka consists of several core components:
1.5.1 Brokers:
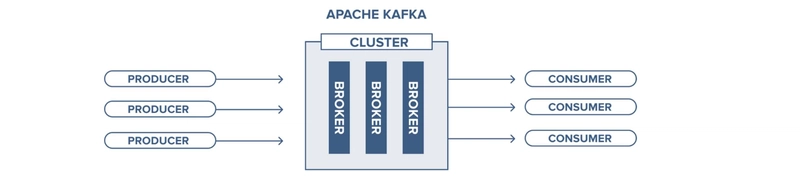
A Kafka broker is a server responsible for handling incoming requests and managing topics. It plays a key role in distributing and storing records efficiently.
In a Kafka cluster, there can be one or multiple brokers working together. Each broker holds a copy of the data and manages the topics created within the cluster.
Producers send records to a broker, which then forwards them to the appropriate topic. On the other end, consumers retrieve records from the broker as needed.
The primary reason for using multiple brokers is to take advantage of replication, ensuring data availability and fault tolerance within Kafka.
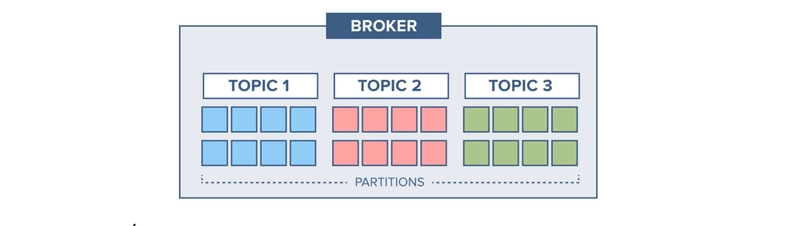
In Kafka, a topic is divided into 8 partitions to enable parallel processing and scalability. These partitions allow multiple consumers to read data concurrently, ensuring efficient data distribution.
Each broker in the Kafka cluster manages one or more partitions, balancing the load and improving fault tolerance. This partitioning mechanism enhances throughput and performance, making it easier to handle large-scale data streams.
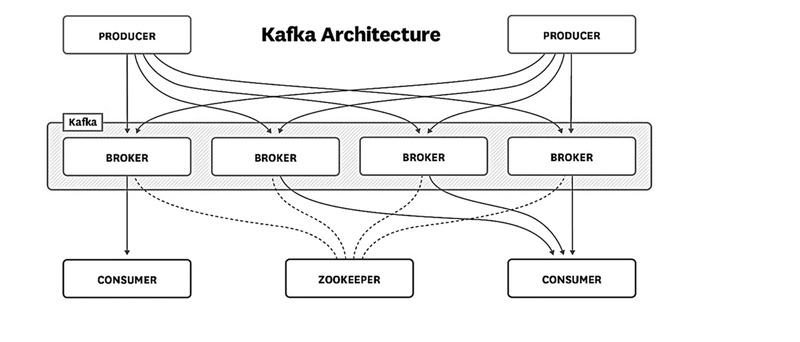
1.5.2 ZooKeeper:
Zookeeper is a distributed coordination service that Kafka uses to maintain synchronization and manage metadata across brokers. It ensures fault tolerance and efficient communication between Kafka components.
- Offset Management: Consumers use offsets stored in logs to keep track of their position while reading data.
- Cluster Coordination: If a broker fails or a new one joins, Zookeeper helps rebalance the cluster.
- Leader Election: It manages leader selection for partitions, ensuring smooth operations.
- Service Discovery: Producers and consumers use Zookeeper to locate active brokers and topics.
1.5.3 Producers:
Send messages to Kafka topics.
1.5.4 Consumers:
Retrieve and process messages from topics using offset tracking to ensure correct message order.
2. Install and Run Kafka
2.1 Installation
Kafka requires Java to run. Install OpenJDK 8 using the following command:
sudo apt update
sudo apt install openjdk-8-jdk
Verify the installation:
java -version
Go to the Apache Kafka website and download the latest version. Alternatively, you can use wget to download it directly:
wget https://downloads.apache.org/kafka/<latest_version>/kafka_<latest_version>.tgz
Extract the downloaded file and check its content:
tar -xzf kafka_<latest_version>.tgz
cd kafka_<latest_version>

In this project, we rely on the bin and config directories to run and manage Apache Kafka services.
- bin directory: Contains all the necessary shell scripts for starting, stopping, and managing Kafka services, such as running Zookeeper, Brokers, and handling topics.
- config directory: Includes configuration files for Kafka, covering settings for Brokers, Zookeeper, Topics, Producers, and Consumers. By exploring the contents of these directories, we can access operational tools that simplify system management and control data flow within Kafka.
2.2 Startup Kafka
To run Kafka, we must first start Zookeeper. Zookeeper is essential for managing the Kafka cluster and ensuring synchronization and coordination between the brokers. As a result, if an error occurs while starting Zookeeper, it will cause Kafka to fail to start due to its heavy dependency on it.
We start Zookeeper using the command:
bin/zookeeper-server-start.sh config/zookeeper.properties
We will get the following output:
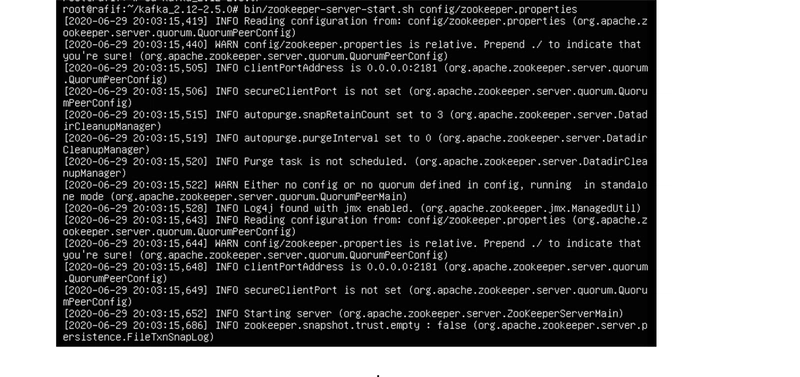
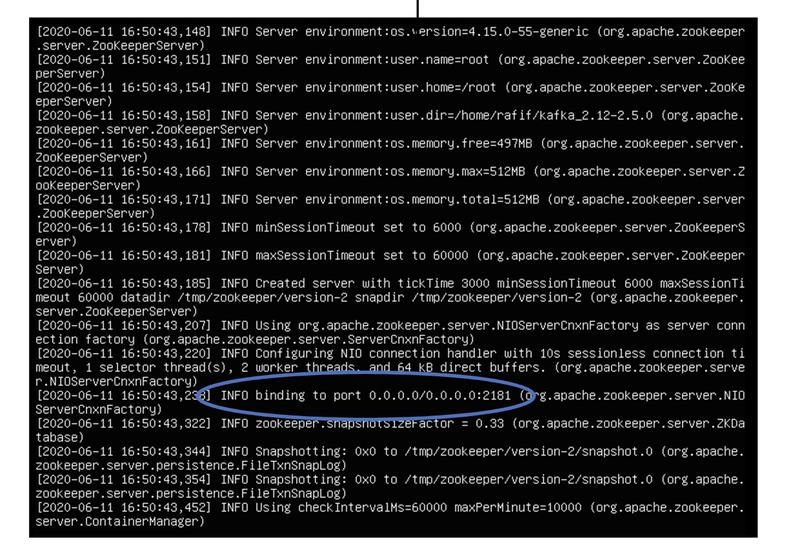
The message enclosed in a circle indicates that Zookeeper is listening on port 2181, which is its designated port. From this notification, we can confirm that Zookeeper is running without any issues. Now, to start Kafka, we open a new session within the virtual machine we're working on by pressing Alt + F3 (this may vary depending on the device). After opening the new session and logging in, we can start Kafka using the command:
bin/kafka-server-start.sh config/server.properties
Now we get the following output:
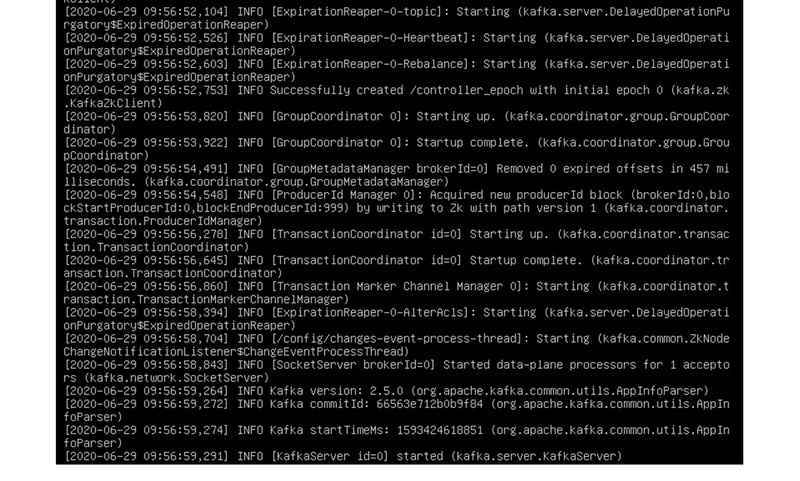
Since it outputted "started," there are no issues. We notice that it assigned the number 0 to the server we just started, which indicates the initial broker number that Kafka creates when it starts.
2.3 Kafka Topics
A topic is a collection of partitions that contain immutable, ordered records, each identified by a unique offset, making the records sequential. The primary goal of having multiple partitions is to allow users to read from the topic in a parallel manner.
To create a topic, we execute the command in a new session (ensure that both Kafka and Zookeeper are running):
bin/kafka-topics.sh –-create –-bootstrap-server localhost:9092 –-replication-factor 1 –-partitions 1 –topic <topic name>
The replication factor indicates the number of copies of the topic that should exist within the Kafka cluster. Its value can be 1, 2, or 3. A value greater than 1 helps store a backup of the data in another broker within the cluster for backup or load balancing purposes. On the other hand, partitions are used to segment the topic, enabling parallel processing. A topic consists of partitions that divide the data across multiple brokers as we mentioned earlier.

After creating the topic, we will send messages from the producer to be received by the consumer. We open both the producer and consumer in separate sessions. we execute the following commands:
producer:
bin/kafka-console-producer.sh --broker-list localhost:9092 -topic <topic name>
Consumer:
bin/kafka-console-consumer.sh localhost:9092 -topic <topic name> --from-beginning
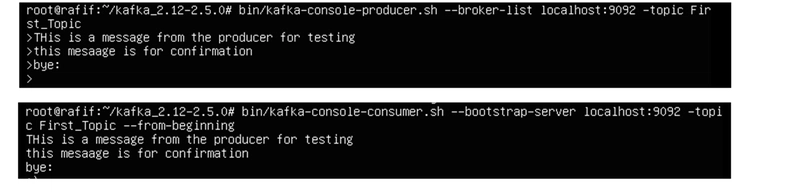
We will notice that the time taken for messages to travel from the producer to the consumer is almost instantaneous, which is one of the main advantages of Kafka—its speed.
And that’s it! In the upcoming chapters, we’ll dive into more advanced features for data streaming—including video and live video streaming using Kafka.

Top comments (0)