
Hey there, tech enthusiasts! 👋
If you’ve ever thought:
“Wouldn’t it be cool if I could just run an AI model locally with zero setup pain?”
Well, let me introduce you to something magical: Docker Model Runner.
This tool is about to become your best friend — whether you’re a developer building ML apps, a DevOps engineer managing workflows, or a leader figuring out how to scale AI integration in your org.
Ready to roll? Let’s go!
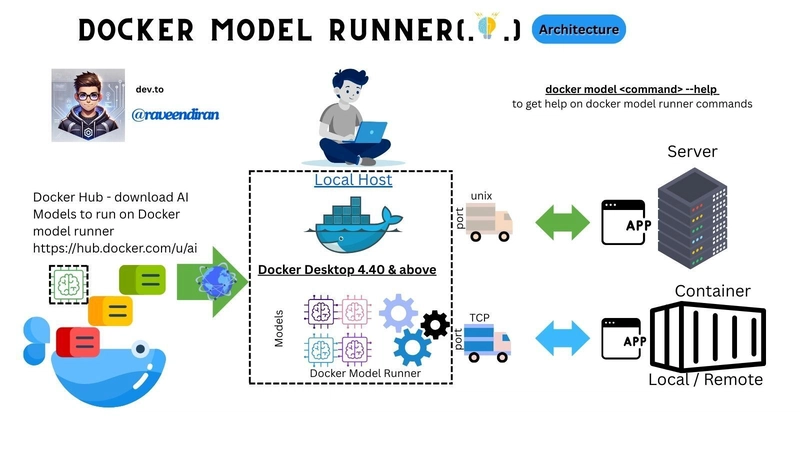
🧠 What is Docker Model Runner?
In plain terms, Docker Model Runner lets you run open models like Llama, Mistral, or Gemma or even deepseek locally on your machine using Docker Desktop — without worrying about dependencies, GPU setup, or cloud costs.(Do keep in mind that local GPU can boost the performance)
It’s like giving your laptop a magic AI engine that works out of the box.
🔧 Why Should You Care? (Even if You’re Not a Dev)
Role What You Gain
Developer Run and test models locally in minutes
DevOps Integrate AI model runs into CI/CD pipelines
Manager Understand how teams can innovate faster, safely
Data Science Try models without wrangling Python environments
Product Lead Explore AI integration early in product lifecycle
✅ Prerequisites
• 🐳 Docker Desktop (v4.27 or later)
• 💻 macOS | Windows | Linux (chipset :Apple Silicon or Intel)
• 🧠 Some curiosity about how AI models can power your tools
• Optional: An OpenAI API key or similar if you plan to do tool calling
🔥 Step-by-Step: Setting Up Docker Model Runner
Let’s do this.
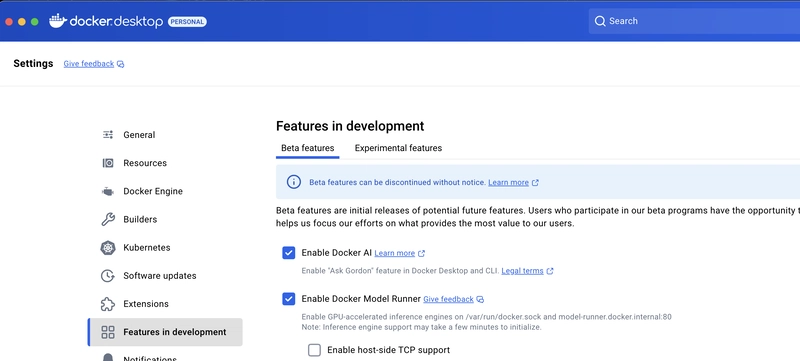
1. Enable Model Runner in Docker Desktop
1. Open Docker Desktop
2. Navigate to Settings > Experimental Features
3. Toggle ON “Model Runner”
2. Pull a Model
Docker makes this ridiculously easy. Open a terminal and run:
(refer [https://hub.docker.com/u/ai])
docker model pull <model name>
Check if the model has been downloaded
docker model list
3. Run the Model Locally
You’ll see it spin up a containerized AI model, ready to answer questions when you run the below command.However, this layer is abstracted by Docker
docker model run <model name>
AI models from Docker’s ai namespace:
🧠 Docker AI Models: At-a-Glance Comparison
Here’s a snapshot of the top models available via Docker's
ainamespace, perfect for local GenAI experiments or production-grade setups.
| Model Name | Description | Provider | Parameters | Quantization | Context Window | Key Features |
|---|---|---|---|---|---|---|
ai/llama3.1 |
Meta's LLama 3.1: Chat-focused, benchmark-strong, multilingual-ready | Meta | 8B, 70B | Q4_K_M, F16 | 128K | - Multilingual (EN, DE, FR, IT, PT, HI, ES, TH) - Text/code generation - Chat assistant - NLG - Synthetic data generation |
ai/llama3.3 |
Newest LLama 3 release with improved reasoning and generation quality | Meta | N/A | N/A | N/A | - Improved reasoning - Better generation quality - Latest LLaMA release |
ai/smollm2 |
Tiny LLM built for speed, edge devices, and local development | N/A | N/A | N/A | N/A | - Optimized for edge - Speed-focused - Local dev - Low resource footprint |
ai/mxbai-embed-large |
Text embedding model | N/A | N/A | N/A | N/A | - Text embedding - Large parameter size |
ai/qwen2.5 |
Versatile Qwen update with better language skills | Qwen | N/A | N/A | N/A | - Improved language abilities - Versatile usage - Broader application support |
ai/phi4 |
Microsoft’s compact model with strong reasoning and coding | Microsoft | N/A | N/A | N/A | - Compact - Strong reasoning - Code generation |
ai/mistral |
Efficient open model with top-tier performance | Mistral AI | N/A | N/A | N/A | - Fast inference - Top performance - Open model |
ai/mistral-nemo |
Mistral tuned with NVIDIA NeMo for enterprise | Mistral AI | N/A | N/A | N/A | - NVIDIA NeMo-optimized - Enterprise-grade - Smooth ops |
ai/gemma3 |
Google’s small but powerful model for chat and gen | N/A | N/A | N/A | - Compact yet strong - Chat-friendly - High-gen capabilities |
|
ai/qwq |
Experimental Qwen variant | Qwen | N/A | N/A | N/A | - Experimental - Lightweight - Fast |
ai/llama3.2 |
Stable LLama 3 update for chat, Q&A, and coding | Meta | N/A | N/A | N/A | - Coding-friendly - Chat capable - Reliable Q&A |
ai/deepseek-r1-distill-llama |
Distilled LLaMA by DeepSeek for real-world tasks | DeepSeek | N/A | N/A | N/A | - Distilled version - Fast execution - Real-world optimization |
⚠️ Note: Many models don’t list detailed specs (params, quant, etc.) publicly. Visit the Docker AI catalog and individual repos for the latest info.
🔁 Integration in Your Dev Lifecycle
Here’s where it gets interesting for teams and orgs.
👷 For Devs
• Add model runner commands in makefiles, test scripts, or runbooks.
• Prototype AI features before wiring them into your full app.
🔄 For CI/CD
• Spin up models in a container during testing.
• Validate AI model outputs in pull requests.
💼 For Management
• Encourage safe local testing without extra infra cost.
• Help teams build trust in GenAI adoption with repeatable environments.
🤔 Wait, Can This Replace the Cloud?
Not entirely. But it’s great for:
✅ Prototyping
✅ Demos
✅ Offline dev
✅ Local evaluation
✅ Privacy-sensitive tasks
You’ll still use the cloud for production workloads — but Model Runner is an amazing stepping stone.
🧪 Real Use Case Example
Imagine you’re building a customer support assistant. You could:
1. Run smollm2 locally via Docker
2. Feed it user queries
3. Use tool calling to fetch FAQs from your API
4. Iterate without pushing a line of code to prod
Dev speed just leveled up. 🚀
🗣️ Wrapping Up
Docker Model Runner is a game changer — not just for devs, but for anyone exploring GenAI.
It’s fast.
It’s local.
It’s powerful.
And best of all… it just works.
So go ahead — pull a model, ask it something, and blow your own mind.
⚠️ Finally .. a pinch of salt while using Docker Model Runner
| Issue | Description | Workaround |
|---|---|---|
| No safeguard for oversized models | Docker Model Runner doesn’t prevent running models too large for your system, which can cause severe slowdowns or make the system unresponsive. | Make sure your machine has enough RAM/GPU before running large models. |
model run drops into chat if pull fails |
If a model pull fails (e.g., due to network/disk space), docker model run still enters chat mode, though the model isn't loaded, leading to confusion. |
Manually retry docker model pull to confirm successful download before running. |
| No digest support in Model CLI | The CLI lacks reliable support for referencing models by digest. | Use model names (e.g., mistralai/mistral-7b-instruct) instead of digests for now. |
| Misleading pull progress after failure | If an initial docker model pull fails, a retry might misleadingly show "0 bytes downloaded" even though data is loading. |
Wait—despite incorrect progress, the pull usually completes successfully in the background. |
👋 Bonus: Run the Hello GenAI App Locally (In Under 5 Minutes)
If you’ve come this far, you’re probably itching to try a real-world app using Docker Model Runner. Good news: Docker has an awesome example project called hello-genai — and it’s the easiest way to see AI in action locally.
Here’s how to set it up:
🧰 Prerequisites
• Docker Desktop with Model Runner enabled ✅
• Git installed (or download the ZIP manually)
• Terminal access
🪜 Step-by-Step Setup
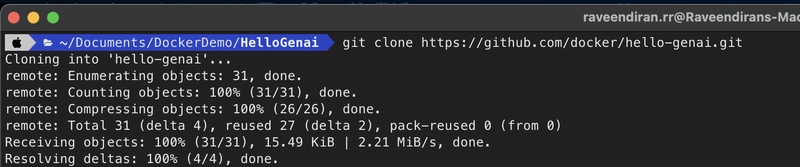
1. Clone the Repo
git clone https://github.com/docker/hello-genai.git
cd hello-genai
2. Pull the Required Model
docker model pull ai/smollm2:latest
You can replace the model if you want to try another supported one (like smollm2 or even deepseek).
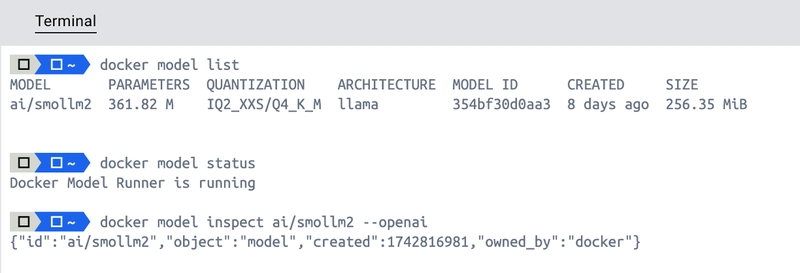
some intersting commands
docker model list
docker model status
docker model inspect
3. Start the App
Just run the command:
./run.sh
This will start both the frontend and the model backend containers in Python | GO and Node.js on different ports
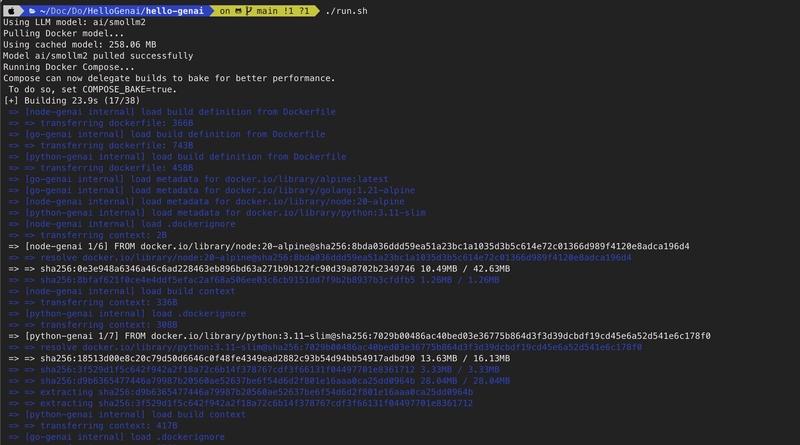
Docker Containers created for this simple chat app
4. Open in Your Browser
Navigate to http://localhost:8081 for python App and start chatting with your AI model right from the browser!
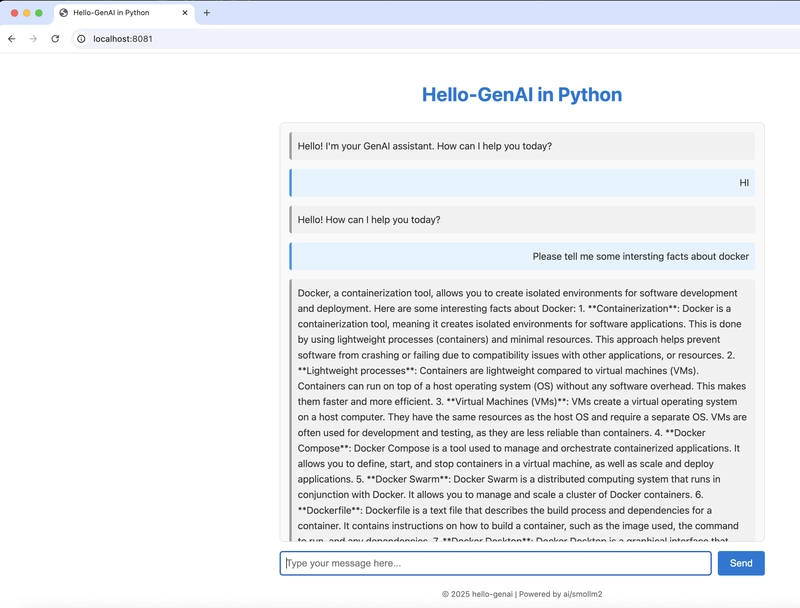
💡 What’s Going On Behind the Scenes?
The Hello GenAI app connects to your locally running model (via the Docker Model Runner) using python and React frontend. No cloud, no GPU setup — just local magic.
This is a great sandbox to:
• Prototype your own AI app
• Customize the frontend
• Try different models
🔄 Want to Stop It?
Simply hit Ctrl + C in the terminal and run:
docker compose down
🎯 Use Case Ideas With Hello GenAI
• Demo to your manager how quickly GenAI features can be spun up
• Test prompt flows before integrating into your real app
• Customize the UI and rebrand it for internal tools
• Hook it to a backend API for a tool-calling proof of concept
🏁 Wrapping This Up (For Real Now!)
Docker Model Runner + Hello GenAI = Your AI sandbox on steroids.
Now you’ve got the power to run, test, and innovate with open-source models without cloud costs or platform headaches.
Want me to create a follow-up walkthrough where we customize Hello GenAI for tool-calling or turn it into a Slack bot? Drop a comment or hit me up!
Let me know if you’d like this post packaged as a downloadable PDF or published directly on dev.to with formatting — happy to help you launch it 🚀
🙋♂️ What’s Next?
Have you tried Model Runner? Planning to use it in your product or workflow?
👉 Let me know in the comments, or share your experience!
👉 Love this content and want more like this -› Vote below!
:)Yes !! it counts a lot
📢 If You Loved This, Don’t Forget To:
• ❤️ Like this post
• 🔄 Share it with your team
• 📬 Follow for more dev-friendly AI tips
Keywords: Docker Model Runner setup, Docker for AI models, MLOps with Docker, running AI models locally, AI tool calling with Docker, Docker Desktop model integration

Top comments (0)