Hello, fairy dairy diary~!
Today the struggles of XL are finally over.

After trying several silly schemes, I decided to one called(in experiments) XL-Long-Reset. Which is basically the most obvious thing and which is Streaming LLM doing: you cache keys, values, then rerotate keys and queiries, so past keys fall on offset=0.

In part 6 I covered only repos which is the same in principle, except it doesn't pass gradient through training window. Once it passes, everything works much better. At least in first 2 epochs. At 3rd epoch it starts to slack and lag behind XL-Long-NoReset in the very end, but three epochs is where I make a decision, and decision was made, XL moved from 00x branch into mainline 003_baka_xl. It helps that so far after Great Refactoring this is the best performing model: valid loss about 4.10.
Speaking of loss.

Permuteformer paper had this beautiful graph
Their best result on graph (taken from .tex code) is (3,53.75), which corresponds to the loss 3.9843. Which is achievable. Granted, their model is 6 layers, hidden dimension of 512, feed forward dimension of 1024, 8 attention heads. which is smaller than BakaNet(12 layers, 768 dim, 3K ff_dim, 12 heads).
I might adapt these parameters for further experiments as it will improve training speed. (Also they had 8 V100, I do have 1 3080Ti laptop 16GB, so they definitely could handle bigger batches)
Also the graph shows that you need about 10-15 epochs to really settle the weight. Not happening anytime soon.
I yet to decide what to do next. There are several things to do, starting from simplest to harder
- add layernorms and anti-small-value-conspiracy to attention
- "Thin layers": add layers without FF. Idea is to use only self attention, nothing else, near the start. This should in theory help XL to see more tokens (each layer up sees one more context window from the past. Right now our effective context size is up to 6K (512 x 12) out of which 512 are the fresh context window, and other are from XL:
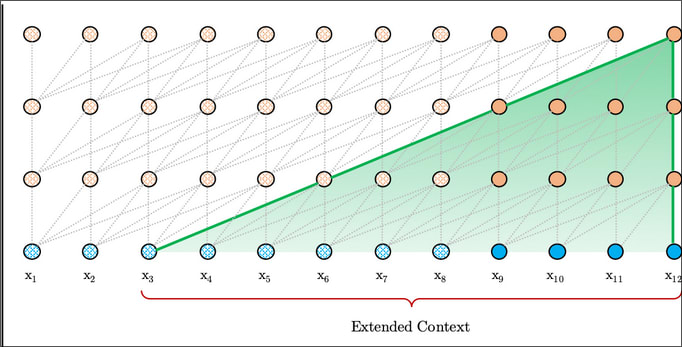
- RMT
- Block-Recurrent Transformers
- Memory Transformer (Not to be confused with Memorizing Transformers) (Not to be confused with Memory Transformer Network). Or to be confused! And be added instead!
- Mega. This will be one of the lastest: I hope pytorch will release version which fixes/worksaround fft.





Top comments (0)