
Chatea en cualquier idioma con un LLM en Bedrock. Envía notas de voz y recibe transcripciones. Con un pequeño ajuste en el código, envía la transcripción al modelo.
Con esta aplicación de WhatsApp, puedes chatear en cualquier idioma con un LLM en Amazon Bedrock. Envía notas de voz y recibe transcripciones. Realizando un pequeño cambio en el código, también puedes enviar la transcripción al modelo.
Tus datos se almacenarán de forma segura en tu cuenta de AWS y no se compartirán ni se utilizarán para el entrenamiento de modelos. No se recomienda compartir información privada, ya que la seguridad de los datos con WhatsApp no está garantizada.
✅ Nivel de AWS: Intermedio - 200
Requisitos previos:
💰 Costo para completar:
- Precios de Amazon Bedrock
- Precios de Amazon Lambda
- Precios de Amazon Transcribe
- Precios de Amazon DynamoDB
- Precios de Amazon APIGateway
- Precios de Whatsapp
Cómo funciona la aplicación

1- Entrada de mensaje:
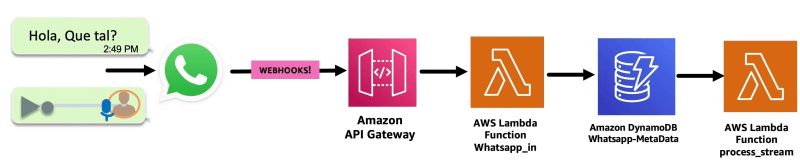
- WhatsApp recibe el mensaje: voz/texto.
Amazon API Gateway recibe el mensaje desde el webhook de WhatsApp (previamente autenticado).
Luego, una función AWS Lambda llamada whatsapp_in procesa el mensaje y lo envía a una tabla Amazon DynamoDB llamada whatsapp-metadata para almacenarlo.
La tabla DynamoDB whtsapp-metadata tiene un streaming de DynamoDB configurado, que activa la función Lambda process_stream.
2 - Procesamiento de mensajes:
Mensaje de texto:
La función Lambda process_stream envía el texto del mensaje a la función Lambda llamada langchain_agent_text (en el siguiente paso la exploraremos).
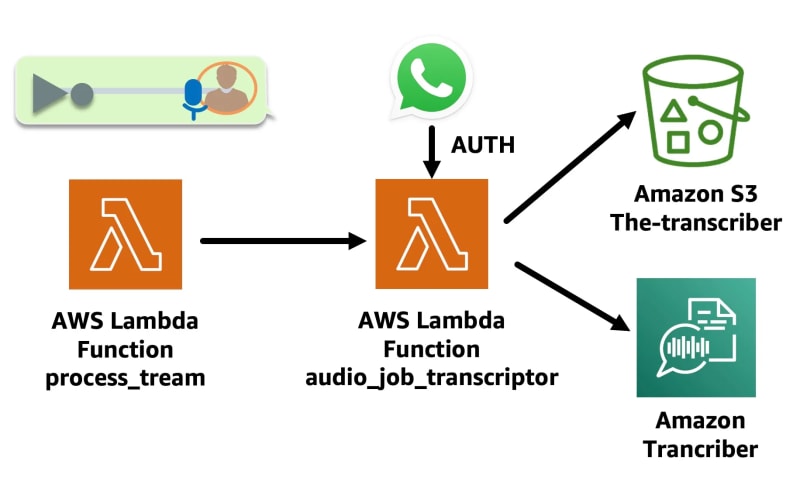
Mensaje de voz:

- Se activa la función Lambda audio_job_transcriptor. Esta función Lambda descarga el audio de WhatsApp desde el enlace en el mensaje en un bucket Amazon S3, utilizando la autenticación de Token de Whatsapp, luego convierte el audio a texto usando la API start_transcription_job de Amazon Transcribe, que deja el archivo de transcripción en un bucket de salida de Amazon S3.
La función que invoca a audio_job_transcriptor se ve así:
def start_job_transciptor(jobName, s3Path_in, OutputKey, codec):
response = transcribe_client.start_transcription_job(
TranscriptionJobName=jobName,
IdentifyLanguage=True,
MediaFormat=codec,
Media={
'MediaFileUri': s3Path_in
},
OutputBucketName=BucketName,
OutputKey=OutputKey
)
💡 Observa que el parámetro IdentifyLanguage está configurado como True. Amazon Transcribe puede determinar el idioma principal en el audio.
- La Función Lambda transcriber_done se activa con una Notificación de Evento de Amazon S3 put item una vez que el trabajo de Transcribe se completa. Extrae la transcripción del bucket de salida de S3 y la envía a la Función Lambda whatsapp_out para responder a WhatsApp.
✅ Tienes la opción de descomentar el código en la Función Lambda transcriber_done y enviar la transcripción de la nota de voz a la Función Lambda langchain_agent_text.
try:
response_3 = lambda_client.invoke(
FunctionName=LAMBDA_AGENT_TEXT,
InvocationType='Event', #'RequestResponse',
Payload=json.dumps({
'whats_message': text,
'whats_token': whats_token,
'phone': phone,
'phone_id': phone_id,
'messages_id': messages_id
})
)
print(f'\nRespuesta: {response_3}')
return response_3
except ClientError as e:
err = e.response
error = err
print(err.get("Error", {}).get("Code"))
return f"Un error invocando {LAMBDA_AGENT_TEXT}"
3- Procesamiento LLM:

El agente recibe el texto y realiza lo siguiente:
Consulta la tabla de Amazon DynamoDB llamada
user_metadatapara ver si lasessionha expirado. Si está activa, recupera elSessionID, necesario para el siguiente paso; si expira, crea un nuevo temporizador de sesión.Consulta la tabla de Amazon DynamoDB llamada
session Tablepara ver si hay algún historial de conversación anterior.Consulta el LLM a través de Amazon Bedrock utilizando el siguiente prompt:
Lo siguiente es una conversación amistosa entre un humano y una IA.
La IA es habladora y proporciona muchos detalles específicos de su contexto.
Si la IA no conoce la respuesta a una pregunta, dice honestamente que no la conoce.
Siempre responde en el idioma original del usuario.
Conversación actual:
{history}
Humano: {input}
Asistente:
- Envía la respuesta a WhatsApp a través de la función Lambda
whatsapp_out.
💡 La frase "Siempre responde en el idioma original del usuario" asegura que siempre responda en el idioma original y la capacidad multilingüe es proporcionada por Anthropic Claude, que es el modelo utilizado en esta aplicación.
¡Construyámoslo!
Paso 0: Activar la cuenta de WhatsApp en Facebook Developers
1- Get Started with the New WhatsApp Business Platform (No se traduce)
2- How To Generate a Permanent Access Token — WhatsApp API (No se traduce)
3- Get started with the Messenger API for Instagram (No se traduce)
Paso 1: Configuración de la APP
✅ Clonar el repositorio
git clone https://github.com/build-on-aws/building-gen-ai-whatsapp-assistant-with-amazon-bedrock-and-python
✅ Ir a:
cd private-assistant
Paso 2: Desplegar la arquitectura con CDK.

En private_assistant_stack.py edita esta línea con el número de la aplicación de WhatsApp de Facebook Developer:
DISPLAY_PHONE_NUMBER = 'TU-NUMERO'
Este agente gestiona la memoria de la conversación, y debes configurar el tiempo de sesión aquí en esta línea:
if diferencia > 240: #tiempo de sesión en seg
Consejo: Kenton Blacutt, un Desarrollador Asociado de Aplicaciones en la Nube de AWS, colaboró con Langchain, creando la clase de memoria basada en Amazon DynamoDB que nos permite almacenar el historial de un agente de langchain en Amazon DynamoDB.
Configura la Interfaz de Línea de Comandos de AWS
Despliega la arquitectura con CDK Sigue los pasos:
✅ Crea el Entorno Virtual: siguiendo los pasos en el README
python3 -m venv .venv
source .venv/bin/activate
para Windows:
.venv\Scripts\activate.bat
✅ Instala los Requisitos:
pip install -r requirements.txt
✅ Sintetiza la Plantilla de CloudFormation con el siguiente comando:
cdk synth
✅🚀 El Despliegue:
cdk deploy

Paso 3: Configuración de WhatsApp
Edita los valores de configuración de WhatsApp en Facebook Developer en la consola de AWS Secrets Manager.

✅ El token de verificación es cualquier valor, pero debe ser el mismo en los pasos 3 y 4.
Paso 4: Configuración del Webhook
Ve a la Consola de Amazon API Gateway
Haz clic en
myapi.Ve a Stages -> prod -> /cloudapi -> GET, y copia la Invoke URL.
Configura el Webhook en la aplicación de desarrollador de Facebook.
Establece la Invoke URL.
Establece el verification token.

¡Disfruta de la aplicación!:
✅ Chatea y haz preguntas de seguimiento. Prueba las habilidades de la aplicación para manejar múltiples idiomas.
✅ Envía y transcribe notas de voz. Prueba las capacidades de la aplicación para transcribir múltiples idiomas.
🚀 Sigue probando la aplicación, juega con el prompt langchain_agent_text de la función Lambda de Amazon y ajústalo a tus necesidades.
Conclusión:
En este tutorial, desplegaste una aplicación sin servidor de WhatsApp que permite a los usuarios interactuar con un LLM a través de Amazon Bedrock. Esta arquitectura utiliza API Gateway como conexión entre WhatsApp y la aplicación. Las funciones Lambda de Amazon procesan el código para manejar las conversaciones. Las tablas de Amazon DynamoDB gestionan y almacenan la información de los mensajes, los detalles de la sesión y el historial de conversación.
Ahora tienes el código esencial para mejorar la aplicación. Una opción a seguir es incorporar Retrieval-Augmented Generation (RAG) para generar respuestas más sofisticadas dependiendo del contexto.
Para manejar escenarios de servicio al cliente, la aplicación podría conectarse a Amazon Connect y transferir llamadas a un agente si el LLM no puede resolver un problema.
Con un mayor desarrollo, esta arquitectura sin servidor demuestra cómo la IA conversacional puede potenciar experiencias de chat atractivas y útiles en plataformas de mensajería populares.
🚀 Algunos enlaces para que continúes aprendiendo y construyendo:
🇻🇪🇨🇱 ¡Gracias!
🇻🇪🇨🇱 Dev.to Linkedin GitHub Twitter Instagram Youtube
Linktr





Top comments (0)