
Photo by Jandira Sonnendeck on Unsplash
Patrik : "So, we need to track where our employees work. Can we do that?"
Devin : "Like, just what store each person works at? Not too hard. Does anyone work at more than one store? Like a regional manager or something?"
Patrik : "No. That's not possible. Each employee works at exactly one store."
Devin : "Alright, easy enough. I'll work something up this week."

...Later...
Patrik : "Devin! We've been loving the employee tracker you built, thanks. Just one little issue-"
Devin : "Let me guess."
Patrik : "We do need some employees to be marked as working at multiple stores. Can we make that change?"
Devin : sigh "Yeah, let me schedule a maintenance window to make the structural changes to the database-"
Patrik : "No, we can't have any downtime for this app. Everyone needs to run their reports. We need to make the changes without a maintenance window."
Devin : "Uhhhhhh...."
Devin : Googling "How to make database changes with no downtime; Migrate tables without downtime; How to hot swap a data model"
Do not worry Devin! Changing models without downtime, while tedious, can be done rather easily. First, let us look at where we need to get to:
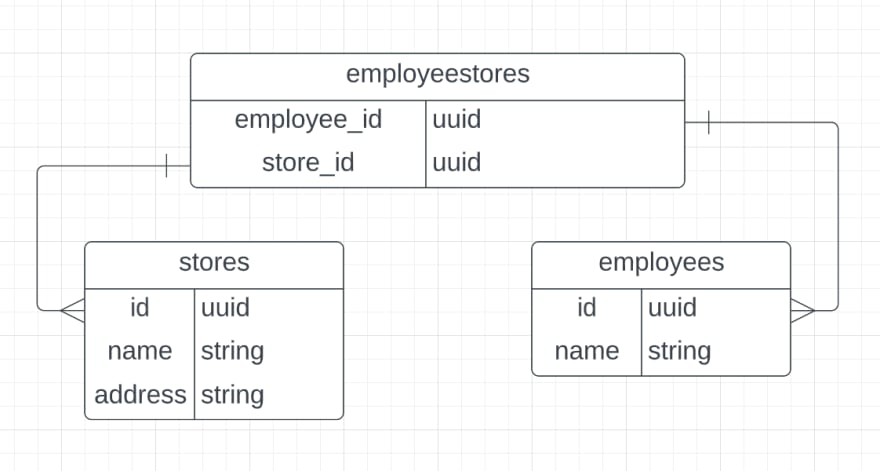
And remember, where we are:
Patrik's requirements pair up to be a one-two punch: change the structure of our database, carry the pre-existing data into the new model, and all without any interruption of service. I have used six simple steps to accomplish just that, more than once, where there could be zero interruption of service and there could be zero data loss or corruption. Here is how I do it:
- Implement new models
- Write to both models
- Backfill old to new
- Read from new models
- Stop writing to old models
- Remove old models
Or IWBRSR for short (alright, alright I'll stop). That's it. That's the whole article. Simple, but effective.
Working through Devin's conundrum, our six steps would work out like this. First, Devin must add the join table we need for the many-to-many relationship between employees and stores. However, Devin does not remove the old foreign key from employees to stores (yet).
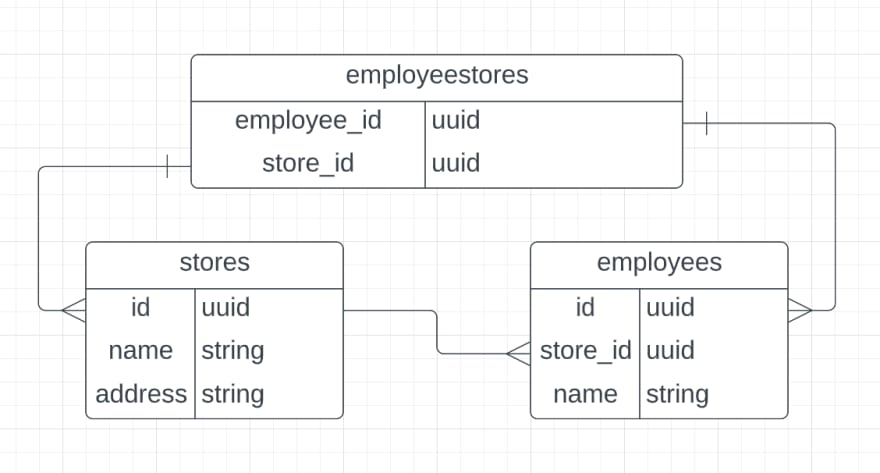
With this database structure change made; Devin now begins adjusting the code wherever an insert, update, or delete is made that affects the foreign key from employees to stores to also insert, update, or delete a corresponding employeestores record. (These code changes do not even need to all be in a single release; anything not correctly mirrored between the old and new models will be handled by the next step).
After those changes, Devin has completed steps 1 and 2. Devin can now prepare a backfill. For each relationship that the old foreign key has that the new join table does not have, Devin will create a row on the join table between employees and stores. Since all new activity keeps the relationships that the new join table and the old foreign key have in sync (from the code changes of step 2), once Devin completes this backfill the old model and the new model are perfect mirrors and will stay perfect mirrors of each others' data.
At this point, it may be a good idea to pause for a step 3.5 where we inspect the database to make sure the new and old models are in fact perfect mirrors of each other (like I just claimed).
Once satisfied, we can move on to step 4 and the work will be downhill from here. Devin begins making code changes wherever employees and stores are queried to use the new join table instead of the old foreign key. (Like step 2, this also does not need to be released at once; since the old and new models mirror one another, reading data from one gives the same results as reading from the other until step 5).
Step 5, Devin is almost done! At this point, the new model effectively runs the application (being written to and read from). Devin can safely go to those places they changed in step 2 and remove the inserts, updates, and deletes to the old foreign key. (Again, this does not need to be done in a single release).
To put the cherry on top, Devin goes in and drops the old foreign key column from employees. Completing step 6 and leaving Patrik with what they wanted, with absolutely no downtime!
Now, this was a somewhat contrived and simple example. When doing this for real many, many complications can arise in each step. But, the steps are exactly the same! They work well because each step can be done in parts and redone, little by little, iteration by iteration, until the step works correctly and the next step can be undertaken. So remember, IWBRSR:
- Implement new models
- Write to both models
- Backfill old to new
- Read from new models
- Stop writing to old models
- Remove old models





Top comments (2)
"refactor data" is the perfect expression. And much harder than refactoring code, but so rewarding when done right!