Curious Engineering Facts (Multi-token Prediction ,Kolmogorov-Arnold Networks (KANs) ****): May Release 2:24

1.Meta’s New Groundbreaking Paper on Multi-Token Prediction for Better and Faster LLMs
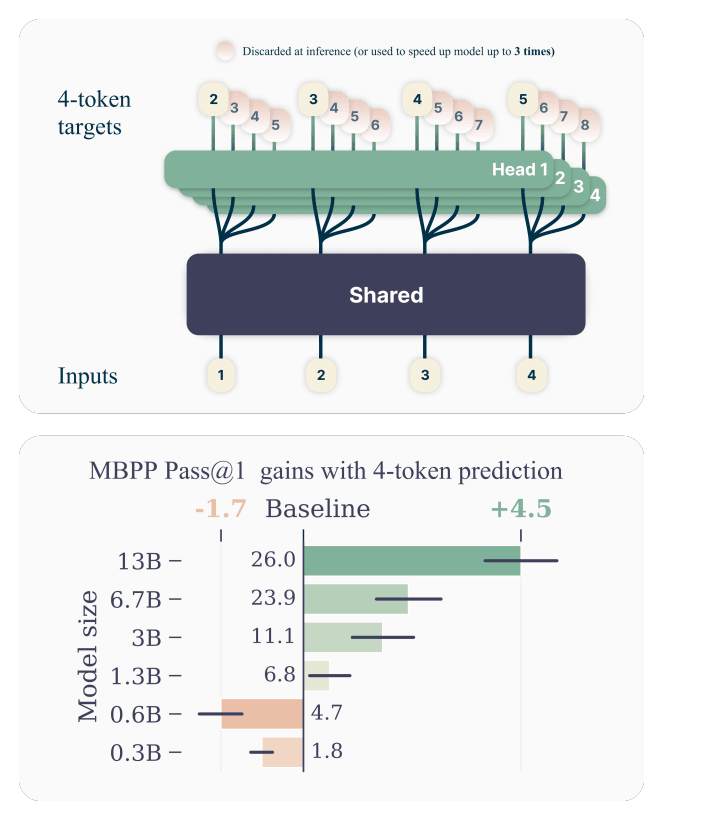
Most current large language models are trained with a next-token prediction loss. However, they require large amount of data and often fail to capture longer-term dependencies effectively.
Meta’s new groundbreaking paper “Better & Faster Large Language Models via Multi-token Prediction” suggests that training language models to predict multiple future tokens at once results in higher sample efficiency.
Performance:
Enhanced Efficiency: Multi-token prediction improves sample efficiency and speeds up inference times by up to 3x, particularly with larger models and batch sizes.
Better Performance on Benchmarks: This technique shows substantial improvement over traditional next-token prediction models on coding tasks and generative benchmarks.
Scalability Benefits: The benefits of multi-token prediction become more significant as model size increases, which implies greater improvements for larger models.
Robustness Across Epochs: Using Multi-token prediction maintains performance advantages even when models are trained for multiple epochs, which demonstrates robustness and durability of training gains.
How it works:
Overall architecture: It consists of a common trunk that processes the input sequence to generate a latent representation of the observed context. On top of that, multiple output heads **are each responsible for predicting a **different future token simultaneously and independently.
Multi-token Prediction Task: Instead of predicting just the next token, the model predicts several future tokens from each position in the input sequence. Each output head makes its prediction independently based on the shared context provided by the trunk.
Training Process: During training, the model is optimized for predicting each of the future tokens independently. This approach trains the model to improve its predictions by considering multiple future outcomes at each step. The predictions are **generated in parallel **across the multiple heads, so this doesn’t add any computation overhead.
Efficient Inference: At inference time, the model can use the trained output heads to generate multiple tokens at once, speeding up the process.
2.A promising alternative to Multi-Layer Perceptrons (MLPs) is taking over the industry: KANs
introducing a novel neural network, Kolmogorov-Arnold Networks (KANs), which replaces MLPs’ fixed activation functions with learnable ones on weights, eliminating linear weights.
KANs enhance accuracy, interpretability, use significantly fewer parameters (200 vs. 300,000 in some MLPs), and effectively prevent catastrophic forgetting. However, their complex activation functions demand more computational resources.
Understanding Kolmogorov–Arnold Networks (KANs)
The genesis of Kolmogorov–Arnold Networks (KANs) is deeply rooted in the Kolmogorov-Arnold representation theorem, a seminal concept in mathematical theory that profoundly influences their design and functionality. This theorem provides a method to express any multivariate continuous function as a superposition of continuous functions of one variable. Inspired by this theorem, KANs are crafted to leverage this foundational mathematical insight, thereby reimagining the structure and capabilities of neural networks.
Theoretical Foundation
Unlike Multi-Layer Perceptrons (MLPs) that are primarily inspired by the Universal Approximation Theorem, **KANs draw from the Kolmogorov-Arnold representation theorem. This theorem asserts that **any function of several variables can be represented as a composition of functions of one variable and the addition operation. KANs operationalize this theorem by implementing a neural architecture where the traditional linear weight matrices and fixed activation **functions are **replaced **with **dynamic, learnable univariate functions along each connection, or “edge”, between nodes in the network.
3.OpenBio-LLM 8B and 70B
OpenBioLLM-8B is an advanced open source language model designed specifically for the biomedical **domain. Developed by Saama AI Labs, this model was fine-tuned on a vast corpus of high-quality biomedical data from the powerful foundations of the **Meta-Llama-3–8B and Meta-Llama-3–8B models.
The 70B parameter model outperforms GPT-4, Gemini, Meditron-70B, and Med-PaLM 1
The Open Medical LLM Leaderboard aims to track, rank and evaluate the performance of large language models (LLMs) on medical question answering tasks.
It evaluates LLMs across a diverse array of medical datasets, including MedQA (USMLE), PubMedQA, MedMCQA, and subsets of MMLU related to medicine and biology. Theses datasets contain multiple-choice and open-ended questions that require medical reasoning and understanding.
The OpenBio-LLM-70B is the leading model according to this benchmark, yet the recent Med-Gemini model is still not included in the leaderboard.
4.HyperSD
Hyper-SD is one of the new State-of-the-Art diffusion model acceleration techniques. It’s a new framework that allows for high fidelity in step compression and mitigates performance losses for Diffusion Models distillation.
In this HF Space, the models distilled from SDXL Base 1.0 and Stable-Diffusion v1–5 are released.

Top comments (0)