 Ever stared at a folder with thousands of PDF invoices, resumes, or reports and thought, "There has to be a better way"? Spoiler: there is.
Ever stared at a folder with thousands of PDF invoices, resumes, or reports and thought, "There has to be a better way"? Spoiler: there is.
At WeSpark Automations, we recently built a PDF data extraction pipeline that processed over 30,000 documents—scanned images, digital PDFs, multi-page forms—and pushed clean, structured data straight into Google Sheets. Zero manual copy-paste. Zero coffee-fueled all-nighters.
Here's how we did it using n8n, OCR, and a bit of AI magic.
The Problem: Manual PDF Hell
Most businesses deal with PDFs daily:
Invoices with vendor names, amounts, dates buried in tables
Resumes with inconsistent formatting across Word, PDF, and scanned images
Financial reports locked in multi-page, image-heavy files
Extracting data manually is slow, error-prone, and soul-crushing. Our client was spending 40+ hours per week just copying data from PDFs into spreadsheets.
The Solution: n8n + AI Extraction Workflow
We built an automated workflow using n8n (open-source automation tool) that:
Monitors email/Google Drive for incoming PDFs
Detects PDF type: Text-based vs. scanned (OCR needed)
Extracts structured data using AI models (names, dates, amounts, tables)
Validates & cleans the data (catches low-confidence extractions)
Pushes to Google Sheets or any database/CRM
Tech Stack Breakdown
- n8n (workflow orchestration)
- PaddleOCR / Tesseract (for scanned PDFs)
- OpenAI GPT / Claude (for intelligent field extraction)
- Google Sheets API (data destination)
- Webhooks (for real-time triggers)
Step-by-Step: Building the Workflow
Step 1: Trigger Node
Set up an Email Trigger or Google Drive Watch node in n8n to detect new PDFs.
// Example: Watch a specific Gmail label
Node: Gmail Trigger
Label: "Invoices/Process"
Attachments Only: Yes
File Types: .pdf
Step 2: PDF Type Detection
Use a Code Node to check if PDF is text-based or scanned:
# Pseudo-code
if pdf.has_selectable_text():
route = "text_extraction"
else:
route = "ocr_extraction"
Step 3: OCR for Scanned PDFs
For image-based PDFs, integrate PaddleOCR or Tesseract:
// n8n HTTP Request to OCR API
POST /ocr/process
Body: { "pdf_binary": $binary.data }
Step 4: AI-Powered Field Extraction
Use OpenAI/Claude to extract specific fields (invoice number, date, total, line items):
`// GPT-4 Prompt
"Extract the following from this invoice text:
- Invoice Number
- Invoice Date (format: YYYY-MM-DD)
- Vendor Name
- Total Amount
- Line Items (JSON array)
Return JSON only."`
Step 5: Data Validation
Add a Function Node to validate extracted data:
// Flag low-confidence extractions
if (confidence < 0.85) {
flagForReview = true;
}
Step 6: Push to Google Sheets
Use the Google Sheets Node to append rows:
Node: Google Sheets
Action: Append Row
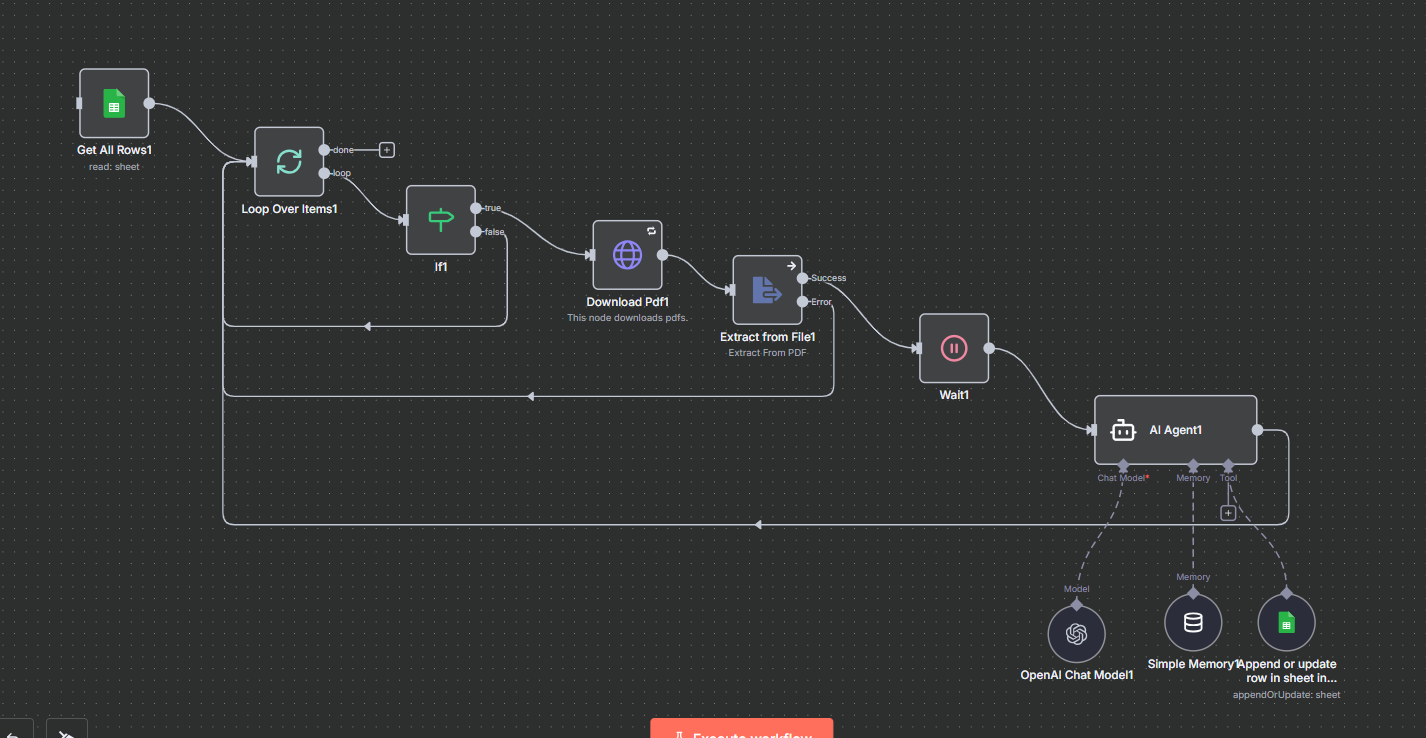
Sheet: "Invoice Data"
Columns: [Invoice_Number, Date, Vendor, Amount]
Real-World Results
After deploying this workflow:
30,000+ PDFs processed in 2 weeks
Accuracy: 94% (with human review for flagged items)
Time saved: 38 hours/week → redirected to analysis instead of data entry
Cost: $0.03 per PDF (mostly API costs)
Challenges We Solved
Mixed PDF Types
Some documents were half-text, half-scanned. Solution: Split into sections and route appropriately.Tables Spanning Multiple Pages
Used ImageTableDetector models to reconstruct tables across pages.Inconsistent Formats
Fed variations into AI with few-shot examples to improve accuracy.
Try It Yourself
Want to build this? Here's the starter workflow:
Clone our n8n template (DM for access)
Set up OCR API (PaddleOCR or Google Vision)
Configure your AI extraction prompts
Connect to Google Sheets/database
Test with 10-20 sample PDFs
Deploy and monitor
Tools & Resources
n8n Community Edition (self-hosted, free)
PaddleOCR (open-source OCR)
OpenAI API (GPT-4 for extraction)
Google Sheets API (free tier: 500 requests/100 seconds)
What's Next?
We're expanding this to:
Multi-language PDFs (Arabic, Chinese invoices)
Handwritten form recognition
Real-time dashboard for extraction monitoring
If you're drowning in PDFs and want to automate extraction, this workflow is your lifeboat.
Questions? Drop them in the comments. I'll share the n8n workflow JSON if there's interest.
About the Author:
Abdul Mohiz is an AI Automation Specialist at WeSpark Automations, building intelligent workflows with n8n, Make.com, and AI. Check out more automation guides at wespark.tech.

Top comments (1)
Please send me a json. I'm interested.