
A data monitoring solution is essential for the development of data-driven streaming applications, the technical acceptance test, or data analysis. In this article, I will show you how you can implement data monitoring and management for Amazon Kinesis in your company with the latest version of KaDeck.
The latest version of the data monitoring and management solution Xeotek KaDeck has been extended by the integration of Amazon Kinesis. This means that not only Apache Kafka, as before, but also Amazon Kinesis users can now enjoy many functions for the management, analysis, and monitoring of their data streams. In the following, I will demonstrate the implementation of KaDeck in your company as well as the most important functions and use cases.
How to get started
KaDeck Web can be deployed as a container within the company's own infrastructure or directly in AWS. To get KaDeck Web, a team must be created on the product website. With the registration, you automatically receive a free user, so that you can start directly with configuring and using KaDeck Web completely free of charge. If you would like to try KaDeck Web in advance without much configuration, the KaDeck All-In-One version is also available, which includes a complete installation with test data and sample applications, but internally uses an Apache Kafka cluster. Since the functions hardly differ from the Amazon Kinesis integration, Amazon Kinesis users can still use this version to see KaDeck in action without much effort.
In AWS, you can integrate KaDeck Web directly via the Elastic Container Service (ECS), or you can use the CloudFormation Template, which is provided by Xeotek via a Gitlab repository. As configuration parameters, both Team Id and Team Secret - they are both sent by e-mail after successful registration - are mandatory. Listing 1 shows the Docker command to start KaDeck Web with the most important parameters (Team Id, Secret, and Port). When logging in for the first time, you must log in as user admin and password admin. The password should then be changed immediately in the profile view.

After logging in, you get to the Connection Overview screen. As soon as you have created the connection with the access data for your Amazon Kinesis service, you are ready to go.
Listing 1: Docker command to start KaDeck Web
docker run -p 80:80 -e xeotek_kadeck_teamid="<teamid>" -e xeotek_kadeck_secret="<secret>" -e xeotek_kadeck_port=80 xeotek/kadeckweb:latest
Work together as a team
If you have purchased additional user licenses for your team in addition to the free user, these will be synchronized via the two mentioned credentials Team Id and Secret. User licenses can be purchased directly in the application in the administration menu under the Licenses tab. You can pay either monthly or annually, whereby individual payment modalities can also be discussed directly via the e-mail address provided there.
KaDeck basically allows the creation of several teams or groups, to which roles are assigned. A role contains several rights, which control the range of functions (e.g. view, create, delete, etc.) in fine granularity down to stream name and namespace. Thus, for example, the access of individual teams to streams can be defined with a certain naming scheme: when creating new streams (if desired), a naming scheme can even be enforced: Team X, for example, can only create streams starting with mycompany.teamx.*.
All actions are always logged in an audit log and are therefore audit-proof and traceable.
Display and filter data streams
In the Data Browser view, you will see a list of all available streams you have access to. Provided that the user has the appropriate rights, you can create new streams or delete existing streams. As soon as you have selected a data stream, the data of the last two hours will be displayed. This can of course be changed: in addition to the number of data sets, the time can also be set.
Data in Amazon Kinesis is always stored as bytes and must be decoded for viewing. KaDeck comes with many codecs and also offers an Auto-Detect functionality, which recognizes the encoding of the incoming data stream completely automatically. If you use a data format that is not already supported by KaDeck, you can also extend KaDeck with your own codec implementations. Thus, even very exotic formats can be handled. The API for own codecs is also used for the internal codecs and offers a variety of possibilities.
Many times you are looking for exactly one special data set or several data sets with a special characteristic. KaDeck offers three filter options for this purpose:
- Filtering or searching on the basis of a string comparison or regular expressions
- Filtering by attributes (by simply clicking on attributes in a record)
- Complex filter logic via the Quick Processor (with JavaScript).
If the format is a structured data format, e.g. a JSON object, you can create a filter with the desired value and comparison operators by simply clicking on the corresponding attribute in the detail view. This means that KaDeck can be used completely without programming or SQL knowledge. To enable collaboration between business users and software engineers (or data scientists) over a single platform, KaDeck was designed in a way that even users with only Excel knowledge can easily analyze their data and create reports with KaDeck. For more complex queries, the powerful Quick Processor can be used, which processes all incoming data in real-time. The Quick Processor supports JavaScript so that queries with time conversions, mathematical formulas and much more can be implemented.
A view created in this way can then be saved and assigned to a stream so that other users can also access the filters and queries without starting from scratch.
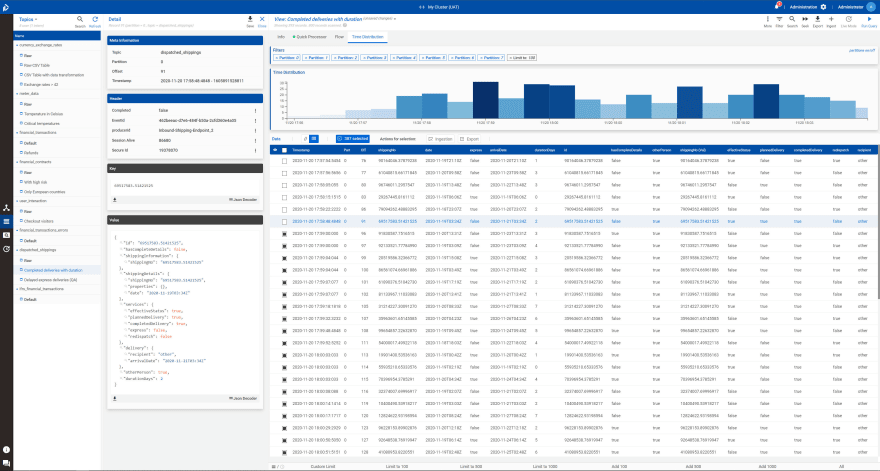
Data transformation and correction
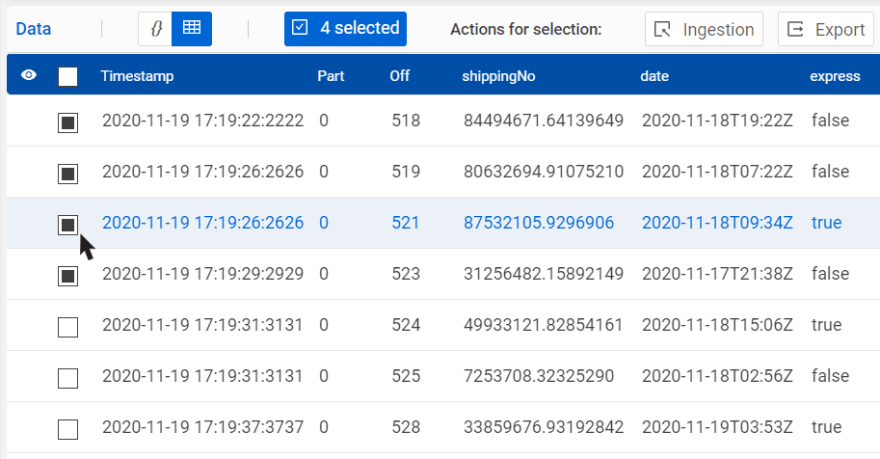
The Quick Processor also offers much more: not only can data records be filtered but also modified. Thus it is possible to implement data mapping logic in JavaScript via the Quick Processor. For example, if you route erroneous data sets into a separate stream, you can correct data sets and send them back for re-processing. Simply modify the corresponding attributes of the data set programmatically with the Quick Processor, select some or all data sets, and open the ingestion dialog to send the transformed data sets to another stream. If you prefer to use a text editor instead of the programmatic approach via the Quick Processor, you can use the JSON/text view in the ingestion dialog.
Save the changes you have made as a view if you need to make the same changes frequently.
Likewise, individual or all data records in KaDeck can be exported as CSV tables.
Real-time data analysis
Not only historical data can be displayed in KaDeck: via the Live Mode, which was added in the latest version of KaDeck, data records can be monitored in real-time. All functions of KaDeck are still available in real-time, for example, filtering and data transformation. The Quick Processor also allows you to save states so that data records can be aggregated or key figures calculated over a certain period of time or a number of data records.

Conclusion
KaDeck Web was designed for various user groups: With views, the filtering of data records without programming or SQL knowledge, and the export of data records as CSV tables, business users have a comprehensive tool to analyze critical data, create reports, or simply take a look at the data. Developers or data analysts, on the other hand, have all the functions they need to develop, test, or analyze critical data sets thanks to the powerful Quick Processor and Codecs API. By providing business users, data analysts, and developers with real-time, collaborative access to critical enterprise data through a central platform, typical communication barriers are also eliminated, business acceptance testing is simplified, and everyone involved becomes more aware of both business and technical processes in the enterprise.
I hope you enjoyed this little introduction to KaDeck and perhaps you were able to learn something helpful for your company. I am looking forward to your suggestions and questions. Do not hesitate to contact our support on our website or the support center, or contact me on Twitter: @xeotekgmbh or @benjaminbuick.
-
I am Managing Director of Xeotek, iSAQB certified software architect and experienced Java software developer from Frankfurt am Main, Germany.
My special interests are dynamic, data-driven systems and especially data streaming and reactive architectures of distributed systems.

Top comments (0)