 Deine Dokumente stapeln sich in Ordnern? Digitalisiere sie doch einfach 📃
Deine Dokumente stapeln sich in Ordnern? Digitalisiere sie doch einfach 📃
Vermutlich wird es jeder kennen. Es trudeln immer wieder neue Briefe per Post ein oder Rechnungen via Mail. Aber was tun damit? Gerade auch im Hinblick auf die jährliche Steuererklärung ist es wichtig, hier ein gutes und schnelles System zu haben, damit man alles bei Bedarf wieder findet (oder eben auch nicht). 😶🌫️
Ein DMS (Document Management System) soll genau das Problem lösen, in dem es alle Dokumente digital vorhält. Moderne DMS bieten hier auch noch zusätzliche Features wie automatisches Tagging, OCR (zur Extration von Metadaten), automatische Zuweisungen etc.

Wie habe ich das früher gelöst? 🤔
Bis vor ein paar Jahren habe ich alle Rechnungen, die via Mail kamen, in einen extra Ordner auf meinem IMAP-Postfach verschoben. Das war nicht nur nervig, sondern auch blöd, da man immer wieder manuell die Mails verschieben musste und später dann wieder die PDF öffnen müsste, damit man weiß, was dort gelaufen ist.
Das musste sich ändern!
Da ich beruflich Softwareentwickler bin und auch Einblick habe, wie Unternehmen arbeiten bei dem Thema, fiel schnell das Stichwort DMS. Aber ein Business DMS, wie es der Sharepoint von Microsoft z.B. ist, ist für den Heimgebrauch einfach zu "fett", zu teuer und muss teils mühseelig angepasst werden. Mal von der Einarbeitungszeit abgesehen.
Durch Florian (https://wartner.io) bin ich dann nach langer Suche auf Paperless-ngx aufmerksam geworden.

Der große Vorteil dabei: Es ist kostenfrei, unabhängig von der Cloud und liegt bei mir zuhause. Zudem bietet es noch so einige andere coole Features, die sehr nützlich sind oder werden könnten (ein kleiner Auszug aus der Doku):
- Organize and index your scanned documents with tags, correspondents, types, and more.
- Performs OCR on your documents, adding searchable and selectable text, even to documents scanned with only images.
- Utilizes the open-source Tesseract engine to recognize more than 100 languages.
- Documents are saved as PDF/A format which is designed for long term storage, alongside the unaltered originals.
- Uses machine-learning to automatically add tags, correspondents and document types to your documents.
- Supports PDF documents, images, plain text files, Office documents (Word, Excel, Powerpoint, and LibreOffice equivalents)1 and more.
- Paperless stores your documents plain on disk. Filenames and folders are managed by paperless and their format can be configured freely with different configurations assigned to different documents.
- Beautiful, modern web application
-
Full text search helps you find what you need:
- Auto completion suggests relevant words from your documents.
- Results are sorted by relevance to your search query.
- Highlighting shows you which parts of the document matched the query.
- Searching for similar documents ("More like this")
-
Email processing: import documents from your email accounts:
- Configure multiple accounts and rules for each account.
- After processing, paperless can perform actions on the messages such as marking as read, deleting and more.
- A built-in robust multi-user permissions system that supports 'global' permissions as well as per document or object.
- A powerful templating system that gives you more control over the consumption pipeline.
- Optimized for multi core systems: Paperless-ngx consumes multiple documents in parallel.
- The integrated sanity checker makes sure that your document archive is in good health.
Wow! Das ist genau das, was ich brauche!

Die Installation 🛠️
Das Setup ist recht einfach über Docker zu erledigen. Es gibt für Unraid fertige Apps oder man nutzt einfach das beiliegende Skript zur Installation. Die Installation ist sehr gut beschrieben in der Doku. Hierbei ist aber zu erwähnen, dass Paperless nur auf Linux läuft.
Es würde auch ohne Docker laufen, aber Docker hat sehr viele Vorteile (die ich bei Bedarf gerne einmal in einem separatem Artikel verfassen werde).
Solltest du bereits einen Docker-Host haben, kannst du auch gerne meine Stackdafür nutzen (du musst ggf. Pfade und die verwendeten Networks anpassen). Hier ist auch gleichzeitig ein Redis-Broker und eine Datenbank (Postgres) mit integriert:
version: "3.6"
networks:
homelab:
name: br1
external: true
dms-internal:
services:
broker:
networks:
- dms-internal
image: redis:6.2
deploy:
restart_policy:
condition: on-failure
volumes:
- /mnt/user/appdata/paperless-ngx/redis:/data
db:
networks:
- dms-internal
image: postgres:14
volumes:
- /mnt/user/appdata/paperless-ngx/db:/var/lib/postgresql/data
environment:
POSTGRES_DB: paperless
POSTGRES_USER: [db user]
POSTGRES_PASSWORD: [db password]
webserver:
networks:
- homelab
- dms-internal
image: ghcr.io/paperless-ngx/paperless-ngx:latest
deploy:
restart_policy:
condition: on-failure
depends_on:
- db
- broker
ports:
- 8777:8000
volumes:
- /mnt/user/appdata/paperless-ngx/data:/usr/src/paperless/data
- /mnt/user/appdata/paperless-ngx/media:/usr/src/paperless/media
- /mnt/user/appdata/paperless-ngx/export:/usr/src/paperless/export
- /mnt/user/appdata/paperless-ngx/consume:/usr/src/paperless/consume
environment:
PAPERLESS_REDIS: redis://broker:6379
PAPERLESS_DBHOST: db
USERMAP_UID: 1026
USERMAP_GID: 100
PAPERLESS_TIME_ZONE: Europe/Berlin
PAPERLESS_ADMIN_USER: [user]
PAPERLESS_ADMIN_PASSWORD: [password]
PAPERLESS_OCR_LANGUAGE: deu+eng
PAPERLESS_URL: [url]
PAPERLESS_FILENAME_FORMAT: "{created_year}/{correspondent}/{created_month}{created_day}_{title}"
Dadurch, dass ich das als Docker Stack laufen lasse, habe ich auch die Möglichkeit bei einem Ausfall eine Art High-Availability zu haben (ggf. auch auf mehreren Host-Systemen).
Einrichtung von Paperless 🍃
Wenn der Stack nun läuft, kannst du ganz einfach auf die freigegebene Website gehen. Dort lächelt dich dann auch der Anmeldebildschirm an, bei dem du dich mit den Daten der Environment-Variablen PAPERLESS_ADMIN_USERund PAPERLESS_ADMIN_PASSWORDanmelden kannst.
Damit wäre das System aufgesetzt, aber noch leer. Du könntest jetzt schon PDFs in das System hineinziehen und die Magie würde schon beginnen ✨
Welche Magie macht Paperless? 🧙
Das ist recht einfach erklärt. Empfängt Paperless ein Dokument, wird eine OCR ausgeführt. Eine OCR (optical character recognition) ist nichts anderes, als ein Digitalisieren des Textes. Dieser ist also somit Volltext-fähig. Zusätzlich zu der OCR wird im Hintergrund auch eine lokale KI trainiert, die viele Dinge schon vorschlagen, erkennen und sogar ganz übernehmen kann.
Taggst du deine Rechnungen also immer wieder mit dem Tag "Fürs Haus", dann wird Paperless das in Zukunft immer so machen. Paperless geht hier aber sogar noch ein Stück weiter. Es bezieht die OCR mit in das Training der KI mit ein. So erkennt Paperless irgendwann, dass deine Jahresabrechnung für Strom (die du mit den Tags Strom, Energie und Haushaltin der Vergangenheit versehen hast) vermutlich in Zukunft auch so zu behandeln sind. Je mehr du also importierst und tagst, desto mehr kann Paperless dir in Zukunft Arbeit abnehmen.
Das klappt auch sehr gut z.B. bei Amazon-Rechnungen die ich manuell importiere. Paperless erkennt recht zuverlässig, was Zeug für den Haushalt ist und was Hardware für mein HomeLab ist. Sehr sehr nice!

Weitere Möglichkeiten
Paperless bietet sehr viele Möglichkeiten deine Dokumente abzulegen und auch zu verwalten. So kannst du für gewisse Dokumenttypen auch unterschiedliche Pfade anlegen lassen. Es bietet eine Benutzerverwaltung (gerade für Familien sehr sinnvoll) und auch die Möglichkeit über Benutzerdefinierte Felder noch mehr Daten in deinen Dokumenten zu pflegen. Zusätzlich dazu, hast du auch die Möglichkeit eine automatische Archivierung vorzunehmen, so dass deine Dokumente immer vorhanden sind (gerade auch im Hinblick auf die Steuer oder bei Selbstständigen sehr sehr sinnvoll).
E-Mailanbindung 📯
Da du vermutlich auch viele Mails mit Rechnungen bekommst, kannst du auch via IMAP dein Postfach anbinden und nach gewissen Schlagworten suchen lassen und die PDFs automatisch nach Paperless importieren lassen. Hierzu kannst du einfach in die Einstellungen gehen unter E-Mail:

Hier legst du dann E-Mail-Konten an, mit denen sich Paperless verbinden soll:
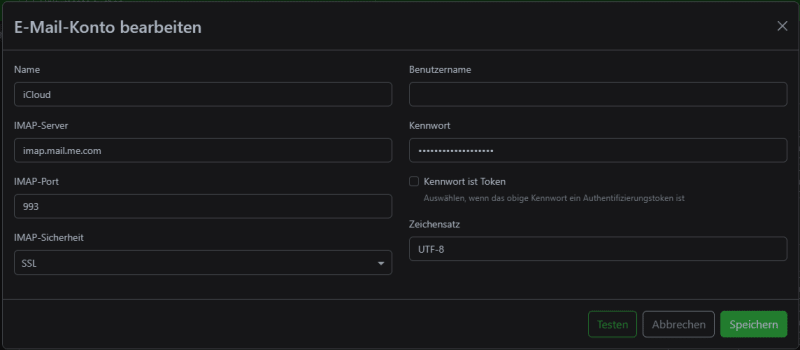
Jetzt wird's nämlich interessant. Du kannst nun auf dieses Postfach Regeln legen. Ich habe eine Regel erstellt, die nach dem Schlagwort "Rechnung" in der E-Mail sucht und nur diese verarbeitet:
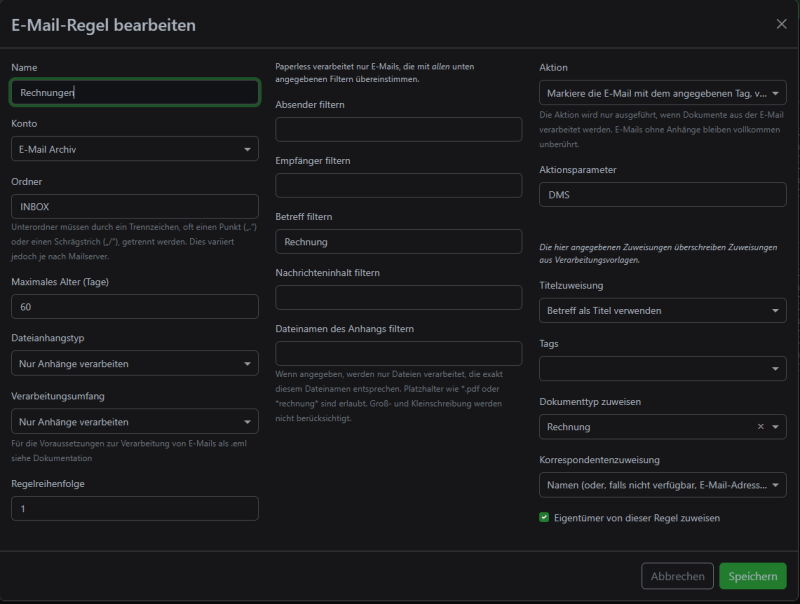
Hier bist du sehr flexibel. Du kannst auch nur nach gewissen Absendern Mails durchforsten, du kannst den Inhalt prüfen und/oder Tags vergeben, Dokumententypen angeben und noch vieles mehr.
Meine Regel besagt also, dass nach dem Schlagwort "Rechnung" im Betreff gesucht werden soll. Es wird dabei nur der Folder INBOXdurchsucht (du kannst auch andere angeben). Wenn es einen Match gibt, wird geprüft, ob PDFs als Anhang vorhanden sind und der Dokumententyp auf Rechnungvorbelegt. Zusätzlich wird auch ein Korrespondent angelegt (ist praktisch eine Kontaktverwaltung). DU könntest hier auch Tags vergeben, z.B.: ungeprüft. So weißt du später, dass du dieses Dokument noch prüfen musst.
❌
iCloud unterstützt leider nicht das automatische Flaggen von E-Mails mit Custom-Tags. Das ist nötig, damit Paperless eine schon importierte E-Mail nicht noch einmal bearbeitet. Das habe ich aber so gelöst, dass alle Mails mit Anhängen an ein externes Postfach (per Regel in iCloud) weitergeleitet werden. Bereits verarbeitete E-Mails bekommen bei mir das Flag "DMS" und werden so nicht nochmal geprüftt.
Und wie bekomme ich bereits digitalisierte Dokumente importiert? 📫
Hier gibt es mehrere Wege die nach Rom führen. Du kannst, wenn es nur ein paar Dokumente sind, diese per Drag and Drop einfach in Paperless ziehen und sie werden sofort verarbeitet. Alternativ hast du aber auch beim Setup einen Folder für Consumeangegeben. Dieser Ordner ist dazu bestimmt, dass du da einfach PDFs reinwerfen kannst und alles verarbeitet wird.
Wenn du dich etwas besser mit Programmierung auskennst, kannst du auch die REST-API von Paperless verwenden und sogar noch andere Programme anbinden.
Was mache ich mit Briefen? 💌
Auch hier gibt es Lösungen. Paperless bietet auch Apps für die gängigen mobilen Betriebssysteme an, womit du Briefe einfach scannen kannst. Alternativ kannst du auch einen Dokumenten-Scanner verwenden, der in das besagte Consume-Verzeichnis die Dokumente ablegt. Dafür muss aber dein Consum-Verzeichnis als Share freigegeben sein.
Eigene Übersichten 🖥️
In Paperless hast du auch die Möglichkeit, dir eigene Übersichten aus der Suche zu erstellen. Ich habe mir so eine Übersicht aller Rechnungen erzeugt und aller Dokumente, die ich noch prüfen muss:
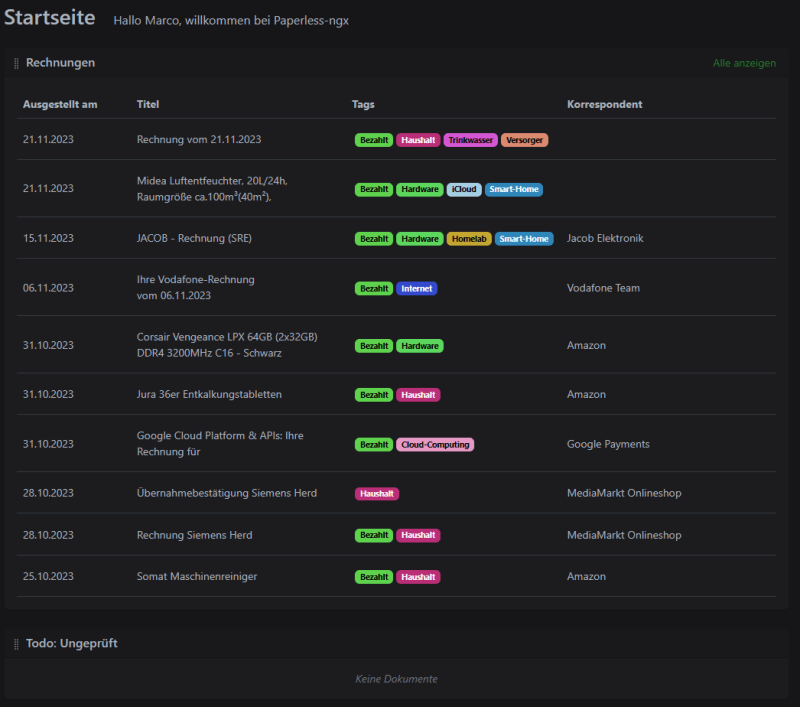
Du bist da aber komplett frei, was und wie du das machen willst um einen Überblick zu behalten.
Du kannst dir so auch Übersichten anlegen, die dir alle Rechnungen des aktuellen Jahres für Hardware ausgeben, damit du sie später bei der Steuer angeben kannst. Die Grenzen sind da eigentlich nur dadurch gesetzt, wie du deine Dokumente verwaltest, taggst und ablegst.
Fazit
Wenn du auch immer wieder Probleme hast mit Dokumenten oder du stapelweise Ordner zuhause rumfliegen hast, kann ich dir Paperless nur wärmstens ans Herz legen! Du wirst es lieben, genau so wie ich es mittlerweile mache ❤️
Wie siehst du das Thema? Wäre Paperless etwas für dich? Oder wie handhabst du deine Verwaltung der Dokumente? Lass es mich in den Kommentaren wissen 👇
If you like my posts, it would be nice if you follow my Blog for more tech stuff.

Top comments (0)