
Because the digital era has grown so competitive — providing users with everything from banking systems to online food delivery — it’s critical that applications never go down for any reason. In fact, users expect that the applications they access will remain available and highly responsive with zero downtime from any part of the world, 24/7.
To provide highly available and fault-tolerant services, platforms must leverage their architecture in order to ensure that their applications and database systems, especially, are always available. They achieve this by replicating apps and databases in geographically isolated parts of the world. With this redundancy, applications remain highly available in different locations; in a situation such as an outage in a data center, the data isn’t lost and the application can keep serving end users from another location. This is known as multi-region scaling.
Multi-region scaling is important because even an entire region can experience downtime. For social media, e-commerce, and other business-critical applications, this downtime can result in revenue losses of millions of dollars. Using a multi-region architecture ensures that applications will keep serving users from different regions.
In this article, you’ll learn more about multi-region scaling, including why it’s so vital and what key issues it solves. You’ll also learn how Fauna can help solve these issues.
Why do you need multi-region scaling?
Multi-region scaling involves the use of multiple regions around the world. A region is a collection of data centers, or availability zones, that are connected via high-speed network infrastructure but are physically isolated from one another, usually in different cities within a country. An application deployed in multiple availability zones within a region is considered highly available. Cloud providers have regions available worldwide, allowing an application to be deployed into more than one region.
This type of scaling becomes necessary as businesses grow to serve millions of users. To keep up with such growth, the underlying tech infrastructure must be designed to be resilient and fault-tolerant while providing a global footprint. Enterprises use multi-region scaling to provide a seamless experience to users by reducing latency as well as ensuring there is a disaster recovery mechanism in place.
For a global application, apart from the application backend, the database system needs to be available in a global context because a global application with a central database system still has a single point of failure. If the database goes down, the application is of no use to end users. A multi-region setup not only ensures application availability but ensures that data is secure and not lost.
How multi-region scaling works
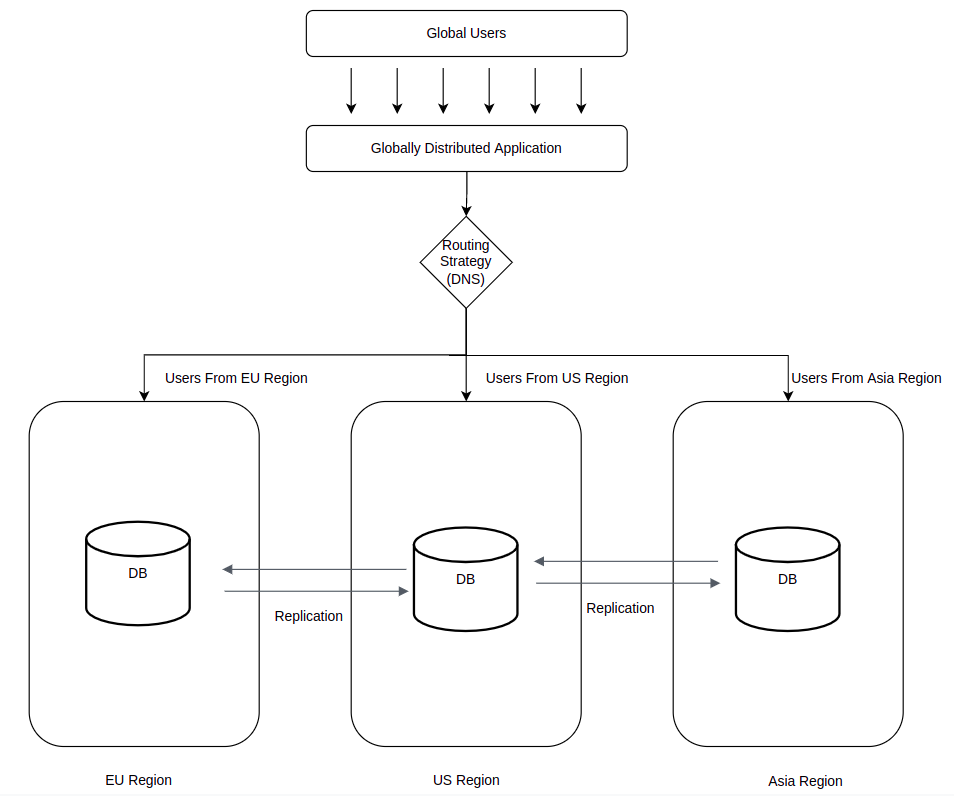
As noted earlier, in multi-region scaling, the infrastructure is deployed into multiple regions. If one region goes down, the service or application remains accessible from a different region, though users in other regions may experience increased latency.
A multi-region setup involves the following elements:
- Use of CDNs: Static content like images, videos, and documents are distributed and cached to a content delivery network (CDN) such as Amazon CloudFront and made local within regions serving users from the closest caching server, instead of bringing the data directly from the source for each request.
- Active/active distributed databases: Distributed databases are usually deployed in an active/passive fashion, in which the primary instance serves both read and write requests while the secondary instances are only available for reads. The active/active deployment strategy allows for all database instances to serve both read and write requests. The data is asynchronously replicated, although there may be a replica lag known as eventual consistency, or the time it takes for changes to reflect in all instances of the database.
- Stateless architecture: Multi-region scaling encourages stateless architectures for applications, meaning they should serve all users with the same responses independent of prior requests and not store or use any local session information. This allows for great horizontal scalability since any available resource can handle the inbound requests.
- Use of DNS routing mechanisms: With a multi-region architecture, the DNS routing doesn’t just direct traffic to the primary instance but also to an instance that provides the least latency for users. For example, AWS routes traffic based on the closest location or proximity to resources.
Why is multi-region scaling important?
There are several advantages to using multi-region scaling.
Catering to a wider audience
Digital businesses increasingly serve users from around the globe, which can present a challenge in providing a consistent experience. To serve users in multiple countries and continents, applications must be accessible from all parts of the world. The redundant system architectures of multi-region scaling make this possible, allowing businesses to launch into new markets and continue to grow their userbase.
Lowering data latency for global users
When organizations serve a global audience, the latency that users experience can affect how they view the service. Applications must have low latency to provide an instantaneous experience to users. Multi-region architectures make this possible.
A low-latency multi-region architecture must include these factors:
- Bringing the content close to end users: The goal is to serve static content to end users from servers closest to them. CDNs are the key to achieving this. Content is replicated and cached in each region, and users are served locally from the closest point within their region.
- Deploying components into multiple regions: Application backends and databases are deployed into multiple regions in order to serve users right from the regions where they live.
Increasing fault tolerance and aiding disaster recovery
Multi-region scaling at its core is about designing a system in a redundant fashion. A redundant architecture is inherently resistant to failures because two identical infrastructures are running at the same time. Even if one part of the architecture fails, the other remains available with an intelligent routing strategy that directs requests from users to their closest resources.
A multi-region design also allows for disaster recovery, because when the application goes down in one region, it can be restored to its original state in one of the other regions. Since data is already being replicated across regions, once a stable infrastructure is deployed the data and all other content can easily be restored from backups.
Ensuring compliance with privacy laws and regulations
Laws and regulations have been enacted in various regions worldwide to mandate data privacy and protect consumer rights. A multi-region strategy can help ensure that specific data is only accessible to users in a certain geographical area. For example, many financial and banking institutions require that the consumer data remains in the country or region of origin. This can easily be handled with a multi-region setup that restricts access to data and its storage to and from the origins only.
Implementing multi-region scaling with Fauna
Deploying a multi-region infrastructure requires a lot of work: deploying databases and application backends in multiple regions; setting up routing mechanisms to direct the traffic properly; setting up replication strategies for data consistency between all databases; and setting up a backup and restoration strategy in case of problems. This can be a nightmare for teams to not only set up but also manage and monitor correctly.
Fauna can help you address these challenges. The distributed database, delivered as an API, is designed to be developer-friendly. It provides both great extensibility and a rich set of features, including the following:
- Document-relational database: Fauna stores data in the form of documents (like JSON objects) but also allows for relationships between documents via foreign keys, combining the ease of working with JSON with the querying power of traditional relational databases. It also provides strongly consistent, distributed, and guaranteed ACID-compliant transactions, making it an ideal choice for all types of data storage needs.
- Serverless: Fauna is delivered as an API running on a serverless architecture, which means there’s no infrastructure to manage. Developers can focus on developing the application while Fauna handles the infrastructure.
- Globally distributed: Fauna is distributed globally and multi-region by default. Fauna easily addresses GDPR compliance with its Region Groups feature that allows control over where data physically resides. Data can be easily split between regions with totally separate compute, databases and storage. And since it’s cloud agnostic it works with all popular cloud providers.
- Managed data and infrastructure operations: Fauna takes care of all the operations related to data and infrastructure management, including data sharding or replications and capacity planning, so your team can focus on improving your application.
Other features include user-defined functions (UDFs), event streaming, and support for popular programming languages like Python, JavaScript, Java, Scala, C#, and Go. Fauna allows you to migrate data from existing sources, and its security features include attribute-based access control (ABAC), integration with Auth0 and other IdPs, and user identity and access management.
With Fauna, you can easily address common issues like:
- Disaster recovery: The inherently distributed nature of Fauna makes disaster recovery simple. Fauna takes care of monotonous tasks like database backups and globally distributing data, so it’s easier to recover and resume business operations from a down region.
- User latency: Fauna helps keep user latency down at scale due to its distributed multi-region setup. Data is served to users from their closest regions by automatically routing requests to replicas closest to them.
- Compliance with regulations: Fauna was created with security and compliance in mind, and all its features are designed according to the AWS Well-Architected Framework and ISO27000 controls. Fauna’s security controls are developed according to AICPA’s Trust Services Criteria, are SOC 2 certified, and comply with GDPR and HIPAA. This allows for scalability across regions while complying with major laws and regulations.
Conclusion
Multi-region scaling can make a major difference in an organization’s ability to serve a global audience. Using it can minimize or eliminate service disruptions and data loss while ensuring high availability and low latency for end users. A multi-region-enabled architecture helps businesses continue to expand their global reach with confidence.
Fauna is a key part of a multi-region scaling strategy. It enables better infrastructure management, recovery options, regulatory compliance, and database design. Get a demo or sign up for free to see how Fauna can help you optimize your applications and improve your business.
Furqan Butt is a software developer and part of the AWS Community Builders Program for data and analytics.

Latest comments (0)