
In October 2020, our customers reported response time inflation for our API to scrape Google Shopping Results. We looked into it and sped up our parsers three times by shipping two pull requests to Nokogiri, trying to patch libxml2, and improving algorithms in our code. Below I describe our way from problem to solutions, and how to improve it further.
TL;DR. Use flame graphs to detect performance bottlenecks and verify improvements.
HTML parsing speedup
Initially, we aggregated Logflare logs and looked into individual responses. Then we profiled our code and benchmarked assumptions.
Logs
We reported 2.23s as total_time_taken but customer reports 5.3577799797058105s, Rails reports 5.129043s (x_runtime), and Cloudflare reports 5.194s (origin_time). Three seconds difference is huge. Probably it was coming from HTML to JSON parsing as it's the main thing not included in our JSON total_time_taken.

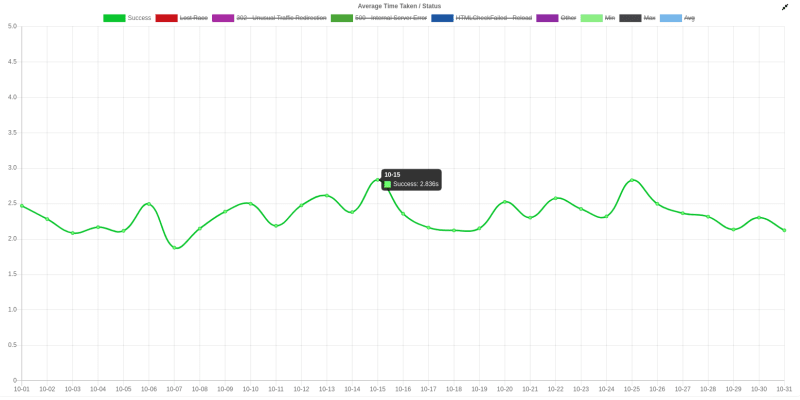
Looking further, parsing took about three seconds for searches with one hundred results (num=100&tbm=shop). HTML pages with one hundred Google Shopping results are 1.5 — 2MiB in size.
$ curl -s -A 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36' 'https://www.google.com/search?q=lawn+mower&oq=lawn+mower&uule=w+CAIQICIdQXVzdGluLFRYLFRleGFzLFVuaXRlZCBTdGF0ZXM&hl=en&gl=us&num=500&tbm=shop&tbs=p_ord:rv&start=0&sourceid=chrome&ie=UTF-8' | wc -c | numfmt --to=iec-i --suffix=B
1.8MiB
Profiling
We (naively) profiled our code and found out that image extraction via regexes from the inline JavaScript is slow but Nokogiri::XML::XPathContext#evaluate took a bit more.
$ TEST_RUBY_PROF=1 bundle exec rspec spec/search/google/shopping_results/shopping_results_card_results_spec.rb$ cat tmp/test_prof/ruby-prof-report-flat-wall-total.txt
Measure Mode: wall_time
Thread ID: 9714020
Total: 11.660184
Sort by: self_time
%self total self wait child calls name location
18.38 2.840 2.143 0.698 0.000 19 <Module::Kernel>#select
13.88 1.626 1.619 0.005 0.002 2531 Nokogiri::XML::XPathContext#evaluate
9.28 1.237 1.082 0.139 0.016 187 JSImageExtractor#extract_js_image js_image_extractor.rb:2
4.22 0.566 0.492 0.000 0.074 488 <Module::Bootsnap::CompileCache::Native>#fetch
3.97 0.463 0.463 0.000 0.000 5 <Class::Nokogiri::HTML::Document>#read_memory
3.26 0.381 0.380 0.001 0.000 88163 String#split
* recursively called methods
Then we looked into flame graphs from rbspy and found out that Nokogiri::HTML takes 25% of wall time.

Benchmarking Nokogiri with different versions of libxml2
Looked in nokogiri and found out that before v1.11.0 it builds libxml2 without compiler optimizations. We’ve tried Nokogiri with --use-system-libraries and Nokogiri::HTML execution time decreased from 2.7 seconds to 1.5 seconds.
Timing results with system libraries
# Install system libxml2 and libxslt
$ gem install nokogiri --use-system-libraries$ bundle exec rails runner tmp/profiler.rbMeasure Mode: wall_time
Thread ID: 70292512504140
Fiber ID: 70292321749400
Total: 1.507682
Sort by: self_time%self total self wait child calls name location
43.31 0.654 0.653 0.000 0.001 1128 Nokogiri::XML::XPathContext#evaluate
13.84 0.211 0.209 0.002 0.000 1 <Class::Nokogiri::HTML::Document>#read_memory
8.40 0.142 0.127 0.008 0.008 100 JSImageExtractor#extract_js_image js_image_extractor.rb:2
Regular nokogiri libraries
# Install system libxml2 and libxslt
$ gem install nokogiri --use-system-libraries$ bundle exec rails runner tmp/profiler.rbMeasure Mode: wall_time
Thread ID: 69919886342480
Fiber ID: 69919692333960
Total: 2.854719
Sort by: self_time%self total self wait child calls name location
41.16 1.190 1.175 0.015 0.000 1 <Class::Nokogiri::HTML::Document>#read_memory
31.82 0.910 0.908 0.000 0.001 1128 Nokogiri::XML::XPathContext#evaluate
4.40 0.146 0.125 0.013 0.008 100 JSImageExtractor#extract_js_image js_image_extractor.rb:2
At that time I wasn’t sure how to properly profile Ruby code, so I’ve used everything: rbspy, stackprof, and ruby-prof.
$ cat tmp/profiler.rb
require "ruby-prof"profile = RubyProf.profile do
search_params = {engine: "google", q: "roller blades", location: "Austin, United States", google_domain: "google.com", hl: "en", gl: "us", num: "500", device: "desktop", tbm: "shop", tbs: "p_ord:rv", file_path: "tmp/roller-blades.html"} Search.new(search_params).parse!
endprinter = RubyProf::FlatPrinter.new(profile)
printer.print($stdout, min_percent: 2)
Oga
Julien Khaleghy also tried Oga gem instead of Nokogiri. It was about six times faster than Nokogiri.
Warming up --------------------------------------
Nokogiri 1.000 i/100ms
Oga 1.000 i/100ms
Calculating -------------------------------------
Nokogiri 0.913 (± 0.0%) i/s - 28.000 in 30.688232s
Oga 6.048 (±16.5%) i/s - 176.000 in 30.016426sComparison:
Oga: 6.0 i/s
Nokogiri: 0.9 i/s - 6.62x (± 0.00) slower
But some tests were failing with LL::ParserError from ruby-ll that is used in Oga.
$ bundle exec rspec specAn error occurred while loading ./spec/search/google/local_results/local_results_for_specific_place_spec.rb.
Failure/Error: if query_displayed = doc.at_css('input[name=q]')LL::ParserError:
Unexpected T_IDENT for rule 24
# /Library/Ruby/Gems/2.6.0/gems/ruby-ll-2.1.2/lib/ll/driver.rb:15:in `parser_error'An error occurred while loading ./spec/search/google/sports_results/milwaukee_bucks_spec.rb.
Failure/Error: if query_displayed = doc.at_css('input[name=q]')LL::ParserError:
Unexpected T_IDENT for rule 24
# /Library/Ruby/Gems/2.6.0/gems/ruby-ll-2.1.2/lib/ll/driver.rb:15:in `parser_error'An error occurred while loading ./spec/search/yahoo/organic_results/organic_results_coffee_spec.rb.
Failure/Error: if ad_result_node.classes.include? 'AdTop'NoMethodError:
undefined method `classes' for #<Oga::XML::Element:0x00007fa7bbd8aa58>
Did you mean? classFinished in 0.00004 seconds (files took 6.79 seconds to load)
0 examples, 0 failures, 6 errors occurred outside of examples
We profiled our code once again. at_css took more time than extract_js_image for these shopping results. I guessed that was because we use multiple CSS selectors to support old and new Google layouts.

Solution #1
I’ve compiled nokogiri with -O2 compiler optimization and now its parsing performance was close to oga. I’ve added this workaround to the Nokogiri issue on GitHub.
$ CFLAGS="-O2 -pipe" gem install nokogiri# Run benchmarkWarming up --------------------------------------
Nokogiri 1.000 i/100ms
Oga 1.000 i/100ms
Calculating -------------------------------------
Nokogiri 4.706 (± 0.0%) i/s - 140.000 in 30.039766s
Oga 5.585 (±17.9%) i/s - 166.000 in 30.030045sComparison:
Oga: 5.6 i/s
Nokogiri: 4.7 i/s - same-ish: difference falls within error
It worked because CFLAGS are passed here and there in ext/nokogiri/extconf.rb.
We also tried different optimization levels. -Ofast was a bit faster than -O2 and -Ofast for me. -O2 and -O3 are almost the same. 20ms speedup forNokogiri::HTML not worth the risks of aggressive optimizations.
We reinstalled Nokogiri with -O2 on production servers. In production, -O2 gave about 600 ms (3.3 seconds vs 3.9 seconds) speed up for large search results pages.
Pull request to Nokogiri
So we’ve opened a PR to Nokogiri to compile libxml2 with -O2 -g flags. After some discussion, Mike Dalessio came up with heavy refactoring of extconf.rb which also included changes from my PR. I have enjoyed communication with Mike.
Images extraction from inline JavaScript with regular expressions
extract_js_image took 49% wall time of data extraction from Google Shopping HTML with num=100 parameter. The entire parsing took two seconds.
$ bundle exec stackprof tmp/stackprof.dump --text --limit 20
==================================
Mode: wall(1000)
Samples: 986 (50.00% miss rate)
GC: 18 (1.83%)
==================================
TOTAL (pct) SAMPLES (pct) FRAME
490 (49.7%) 467 (47.4%) extract_js_image
334 (33.9%) 334 (33.9%) Nokogiri::XML::Document#decorate
23 (2.3%) 23 (2.3%) Nokogiri::XML::XPathContext#register_namespaces
23 (2.3%) 23 (2.3%) JSUtils.unescape
15 (1.5%) 13 (1.3%) Nokogiri::HTML::Document.parse
15 (1.5%) 13 (1.3%) Mongoid::Fields::ClassMethods#database_field_name
9 (0.9%) 9 (0.9%) (sweeping)
8 (0.8%) 8 (0.8%) (marking)
13 (1.3%) 7 (0.7%) #<Module:0x00007fb3c0edab68>.xpath_for
7 (0.7%) 7 (0.7%) block (3 levels) in class_attribute
10 (1.0%) 6 (0.6%) Nokogiri::XML::Searchable#extract_params
4 (0.4%) 4 (0.4%) Nokogiri::XML::Node#namespaces
890 (90.3%) 4 (0.4%) get_shopping_results
We found out with Žilvinas Kučinskas, that extract_js_image matched the entire HTML string against seven regular expressions on each method call. get_thumbnail calls extract_js_image. get_thumbnail is called fifty times from different parsers. The parser for Google Images API called get_thumbnail one hundred times.
extract_js_image looked like this:
if html =~ REGEX_1
JSUtils.unescape $1
elsif html =~ REGEX_2
JSUtils.unescape $1
elsif html =~ REGEX_3
JSUtils.unescape $1
elsif html =~ REGEX_4
JSUtils.unescape $1
elsif html =~ REGEX_5
JSUtils.unescape $1
elsif html =~ REGEX_6
JSUtils.unescape $1
elsif html =~ REGEX_7
JSUtils.unescape $1
end
Solution #2
The first assumption was to call String#scan once per parsing and cache extracted matches. We worked more on this assumption and came up with regular expressions with named captures.
THUMBNAIL_CAPTURE_NAME = "thumbnail"
THUMBNAIL_ID_CAPTURE_NAME = "thumbnail_id"
THUMBNAIL_ID_REGEX = %r{(?<#{THUMBNAIL_ID_CAPTURE_NAME}>[dws_-',]{1,500})}
JS_IMAGE_REGEXES_GOOGLE = [
%r{#{THUMBNAIL_ID_REGEX}CUT(?<#{THUMBNAIL_CAPTURE_NAME}>(?:CUT)[^"]+)}, # Omitted
]
JS_IMAGE_REGEXES_BING = [
%r{#{THUMBNAIL_ID_REGEX}CUT(?<#THUMBNAIL_CAPTURE_NAME}>CUT[^<]+)}, # Omitted
]
JS_IMAGE_REGEXES = {
google: JS_IMAGE_REGEXES_GOOGLE,
bing: JS_IMAGE_REGEXES_BING,
all: JS_IMAGE_REGEXES_GOOGLE + JS_IMAGE_REGEXES_BING
}
We used code from this StackOverflow answer to convert all named captures from the String#scan to the single dictionary of { “thumbnail_id” => “thumbnail” }.
def extracted_thumbnails
return @extracted_thumbnails if @extracted_thumbnails.present?
js_image_regexes = JS_IMAGE_REGEXES.detect { |key, _| engine.starts_with?(key.to_s) }&.last || JS_IMAGE_REGEXES[:all]@extracted_thumbnails = js_image_regexes.collect { |regex|
regex_capture_names = regex.namesthumbnail_index = regex_capture_names.index(THUMBNAIL_CAPTURE_NAME)
thumbnail_id_index = regex_capture_names.index(THUMBNAIL_ID_CAPTURE_NAME)
html.scan(regex).collect do |match|
found_thumbnail = match[thumbnail_index]
found_thumbnail_id = match[thumbnail_id_index]
found_thumbnail_id.split(",").map { |thumb| Hash[thumb.tr("'", "").squish, found_thumbnail] }
end
}.flatten.inject(:merge) || {}
end
extracted_thumbnails allocates about 2.25 MB of memory for large HTML like Google Shopping results. That’s 0.2 MB more comparing to the previous slow implementation.
Usage of extracted_thumbnails is straightforward.
def extract_js_image(image_node)
return unless image_node thumbnail_id = (image_node["id"])
return unless thumbnail_id if (found_thumbnail = extracted_thumbnails[thumbnail_id])
JSUtils.unescape(found_thumbnail)
end
end
extract_js_image takes 17.9% wall time of data extraction from Google shopping HTML with num=100 parameter. The entire parsing takes 1.2 seconds.
$ bundle exec stackprof tmp/stackprof.dump --text --limit 20
==================================
Mode: wall(1000)
Samples: 532 (58.18% miss rate)
GC: 15 (2.82%)
==================================
TOTAL (pct) SAMPLES (pct) FRAME
253 (47.6%) 253 (47.6%) Nokogiri::XML::Document#decorate
107 (20.1%) 95 (17.9%) extract_js_image
23 (4.3%) 23 (4.3%) Nokogiri::XML::XPathContext#register_namespaces
12 (2.3%) 10 (1.9%) JSUtils.unescape
11 (2.1%) 9 (1.7%) Nokogiri::HTML::Document.parse
Nokogiri#at_css
Then we ran rbspy in production and found out that at_css (Nokogiri::XML::Document#decorate) took much time because of performance problem in libxml2 (the underlying lib that nokogiri uses to parse and traverse XML).

c function is not very helpful to find the performance problem, so we dug deeper.
perf Linux profiler
I searched over the web how to profile C extensions for Ruby and C code in general, and found out Brendan Gregg’s tutorial on Linux perf. That was my first usage of Linux perf profiler. I’ve also tried gperftools and pprof, because seen its usage. And flamescope, because it was made by Brendan Gregg. There are many similar tools and it was hard to figure out what to use during two weeks or so.
I reinstalled Nokogiri with debugging info, not-stripped just in case.
CFLAGS="-O2 -ggdb3 -gdwarf -pipe -lprofiler -fno-omit-frame-pointer" gem install nokogiri
Executing perf record and perf report shows thatxmlXPathCompOpEval and xmlXPathNodeCollectAndTest took most of the time, and are being called recursively.

The flame graph for the single search.parse! shown basically the same.
cargo install flamegraph
flamegraph -- bundle exec rails runner 'Search.new(q: "pc game", tbm: "shop", file_path: "tmp/pc_game_big_shopping.html").parse!;

Chart from pprof shows that objspace_malloc_increase.constprop.0, atomic_sub_nounderflow and xmlStrlen have the biggest total and self time. xmlXPathNodeCollectAndTest has the biggest self time which means the body of this function is a potential performance bottleneck.
I’ve installed perf_data_converter to be able to use perf.data report with pprof.
perf record -F99 -e cycles:u -g -- bundle exec rails runner 'Search.new(q: "pc game", tbm: "shop", file_path: "tmp/pc_game_big_shopping.html").parse!;'
pprof -web perf.data
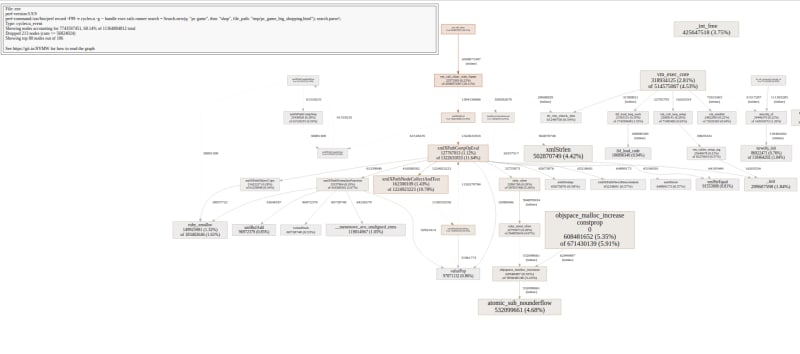
flamescope shows the same as flamegraph. Both of these tools use the same tools to generate chart probably.

Returning back to Nokogiri
I’ve opened an issue in the Nokogiri repository. I had ideas for improving xmlStrlen performance but it was better to get help from someone who knows C and has experience with libxml2.
In the big document, xmlStrlen is called 15K times for the same string. In the small document, it’s being called for 5K times. Three times bigger document and three times more calls. But the strings are the same. My assumption as a person who doesn’t know C: the unique string pointer address means that the function was called with the same argument.
Given this Ruby script that searches an element in the container.
html = File.read(ARGV[0])
doc = Nokogiri::HTML.parse(html)
10.times do
doc.css(".sh-dlr__list-result, .sh-dgr__grid-result").each do |sh_r|
10.times do
sh_r.at_css(".na4ICd:not(.rOwove):not(.TxCHDf):nth-of-type(1), .hBUZL:not(.Rv2Cae):nth-of-type(2), .hBUZL:not(.Rv2Cae):not(.Fxxvzc):not(:has(span)):not(:has(div)), .dWRflb, .p7n7Ze:not(:has(a))")
end
end
end
I’ve calculated xmlStrlen calls by attaching dynamic breakpoint in gdb. To do so, I recompiled nokogiri with debug information.
CFLAGS="-O -ggdb3 -pipe -fno-omit-frame-pointer" gem install nokogiri
Then attached the breakpoint via gdb to get the line to attach dprintf later on.
bundle exec gdb -q -ex 'set breakpoint pending on' --ex 'thread apply all bt full' --ex 'b xmlStrlen' --ex run --args ruby ./tmp/slow_search_parse.rb tmp/pc_game_big_shopping.html
Then attached [dprintf][41] via GDB to the xmlStrlen function of libxml2 to print pointer of str variable and log output to the file. I executed this script with a big and small HTML document.
bundle exec gdb -q -ex 'set breakpoint pending on' --ex 'thread apply all bt full' --ex 'dprintf xmlstring.c:425, "str: %pn", str' --ex run --ex quit --args ruby ./tmp/slow_search_parse.rb tmp/pc_game_big_shopping.html |& tee xmlStrlen_big.log
bundle exec gdb -q -ex 'set breakpoint pending on' --ex 'thread apply all bt full' --ex 'dprintf xmlstring.c:425, "str: %pn", str' --ex run --ex quit --args ruby ./tmp/slow_search_parse.rb tmp/pc_game_small_shopping.html |& tee xmlStrlen_small.log
Then examined logs
$ grep str: xmlStrlen_big.log | sort | uniq -c | sort -rn | head -20
15446 str: 0x112e760
15405 str: 0x112e6d0
13405 str: 0x15ddb80
4006 str: 0x7fffe6c615ad
1962 str: 0x112e740
381 str: 0x7fffe69de010
374 str: 0x15b5520
321 str: 0x1649d60
306 str: 0x174c7a0
306 str: 0x1734430
306 str: 0x15db410
306 str: 0x15b63b0
303 str: 0x174c830
303 str: 0x15db4a0
303 str: 0x15b64a0
298 str: 0x161a8b0
297 str: 0x16e3fa0
291 str: 0x160fd50
287 str: 0x163c320
285 str: 0x16feef0
$ grep str: xmlStrlen_small.log | sort | uniq -c | sort -rn | head -20
5046 str: 0xf3fbc0
5038 str: 0xf3fcb0
1687 str: 0xf40440
906 str: 0xf3fc30
806 str: 0x7fffe6c615ad
431 str: 0xfe0460
420 str: 0x11b53e0
384 str: 0x1067bb0
353 str: 0xfdc760
328 str: 0x11e5ab0
322 str: 0x11e5a40
306 str: 0x11ccea0
303 str: 0x11ccf30
303 str: 0x11bc040
301 str: 0x11a57d0
291 str: 0x11e7740
289 str: 0x1200a70
288 str: 0x11d5660
284 str: 0x11e6d80
284 str: 0x11c3fd0
I had a simple idea about caching the length of strings in memory in xmlStrlen and compare the performance, but Mike Dalessio said it’s not safe to cache string lengths across xmlStrlen calls.
Then Mike came up with a 2x speedup of node lookups which decreased the time to extract data from big HTML files to one second.
Improvement of xmlStrlen from libxml2
We’ve moved further with an idea to cache string lengths in xmlStrlen and compared its performance with strlen from glibc.
Given the simplest benchmark, xmlStrlen is two times slower than strlen from glibc on small strings, ten times slower on average strings, and thirty times slower on big strings and an entire HTML file.
The performance of xmlStrlen resulted in the 0.7 - 1.5 seconds to parse and search through 2 MB HTML document by using Nokogiri. I described this issue in the Nokogiri repository which led to 2x speedup on the Nokogiri side, but xmlStrlen still could be faster.
$ ./slow_parsing_benchmark
xmlStrlen (entire HTML file): 926171.936981 μs
glibc_xmlStrlen (entire HTML file): 36905.903992 μs
delta (xmlStrlen ÷ glibc_xmlStrlen): 25.094584 timesxmlStrlen (average string): 57479.204010 μs
glibc_xmlStrlen (average string): 5802.069000 μs
delta (xmlStrlen ÷ glibc_xmlStrlen): 9.905937 timesxmlStrlen (bigger string): 388056.315979 μs
glibc_xmlStrlen (bigger string): 12797.856995 μs
delta (xmlStrlen ÷ glibc_xmlStrlen): 30.318382 timesxmlStrlen (smallest string): 15870.046021 μs
glibc_xmlStrlen (smallest string): 6282.208984 μs
delta (xmlStrlen ÷ glibc_xmlStrlen): 2.527903 times
So I’ve opened an issue in libxml2. The naive approach to simply reuse strlen in xmlStrlen speed up our document parsing and searching from 1.4 seconds to about 800 ms.
diff --git a/xmlstring.c b/xmlstring.c
index e8a1e45d..df247dff 100644
--- a/xmlstring.c
+++ b/xmlstring.c
@@ -423,14 +423,9 @@ xmlStrsub(const xmlChar *str, int start, int len) {
int
xmlStrlen(const xmlChar *str) {
- int len = 0;
-
if (str == NULL) return(0);
- while (*str != 0) { /* non input consuming */
- str++;
- len++;
- }
- return(len);
+
+ return strlen((const char*)str);
}
/**
Mike Dalessio noted that xmlStrlen() has remained unchanged since the commit it was introduced, 260a68fd, in 1998, and is equivalent to the K&R version.
glibc’s implementation is faster because it’s implemented in assembly customized for common/modern CPUs. Some background here.
With some help, I’ve posted a very verbose comment of 10% speedup with the xmlStrlen patch on the C program that used libxml2 directly.
Before the patch
$ cd ~/code/libxml2
$ git checkout origin/master
$ CFLAGS="-O2 -pipe -g" ../configure --host=x86_64-pc-linux-gnu --enable-static --disable-shared --with-iconv=yes --without-python --without-readline --with-c14n --with-debug --with-threads && make clean && make -j
$ sudo make install
$ cd ~/code/benchmark && make && ./slow_parsing_benchmark ./pc_game_big_shopping.html "//*[contains(concat(' ', @class, ' '), ' sh-dlr__list-result ')]//*[contains(concat(' ', @class, ' '), ' hBUZL ')]"
# Some parsing errors like
./pc_game_big_shopping.html:62: HTML parser error : Tag path invalid
4h2c0-1.1.9-2 2-2s2 .9 2 2c0 2-3 1.75-3 5h2c0-2.25 3-2.5 3-5 0-2.21-1.79-4-4-4z"searching './pc_game_big_shopping.html' with '//*[contains(concat(' ',@class,' '), ' sh-dlr__list-result ')]//*[contains(concat(' ', @class, ' '), ' hBUZL ')]' 1000 times
NODESET with 260 results
67855 ms
After the patch
$ cd ~/code/libxml2
$ git checkout xmlStrlen-patch
$ CFLAGS="-O2 -pipe -g" ../configure --host=x86_64-pc-linux-gnu --enable-static --disable-shared --with-iconv=yes --without-python --without-readline --with-c14n --with-debug --with-threads && make clean && make -j
$ sudo make install
$ cd ~/code/benchmark && make && ./slow_parsing_benchmark ./pc_game_big_shopping.html "//*[contains(concat(' ',@class,' '), ' sh-dlr__list-result ')]//*[contains(concat(' ', @class, ' '), ' hBUZL ')]"
searching './pc_game_big_shopping.html' with '//*[contains(concat(' ',@class,' '), ' sh-dlr__list-result ')]//*[contains(concat(' ', @class, ' '), ' hBUZL ')]' 1000 times
NODESET with 260 results
59767 ms
I was not sure why it ran faster with the patch. The flame graph of the sample program from this post looked the same for nokogiri on master and on the branch of this PR. xmlXPathCompOpEval is dominating before and after the patch.

Nick Wellnhofer hasn’t responded to my comment and in the PR to libxml2, but our PR to Nokogiri was merged to master and shipped in v1.11.0.rc4, so the solution was good enough for us.
Update February 21, 2022: Mike's PR with the xmlStrlen optimization was merged to Libxml2.
Results
Data extraction from big HTML files decreased from three seconds to one second and two of our PRs were shipped in Nokogiri v1.11.0.
Two of our PRs were shipped to Nokogiri v1.11.0
Things we haven’t tried
- Haven’t tried to use bcc for tracing and profiling.
- Haven’t read the entire documentation about
perf.
What’s next
I’m glad to have the opportunity to contribute to an open-source project that is used by thousands of people. Hopefully, we will speed up Nokogiri (or XML parser it uses) to match the performance of html5ever or lexbor at some point in the future. 800 ms to extract data from HTML is still too much.
As of an experiment, I’ve made an FFI wrapper around the Rust scraper crate. at_css.text calls of proof of concept are 60 times faster than Nokogiri ones.
$ ruby benchmarks/nokogiri_benchmark.rb
Warming up --------------------------------------
Nokogiri::HTML 2.000 i/100ms
NokogiriRust::HTML 3.000 i/100ms
Calculating -------------------------------------
Nokogiri::HTML 27.195 (±14.7%) i/s - 132.000 in 5.042868s
NokogiriRust::HTML 40.319 (± 5.0%) i/s - 201.000 in 5.001218sComparison:
NokogiriRust::HTML: 40.3 i/s
Nokogiri::HTML: 27.2 i/s - 1.48x (± 0.00) slowerWarming up --------------------------------------
Nokogiri::HTML.at_css.text
5.000 i/100ms
NokogiriRust::HTML.at_css.text
394.000 i/100ms
Calculating -------------------------------------
Nokogiri::HTML.at_css.text
61.027 (± 3.3%) i/s - 305.000 in 5.002827s
NokogiriRust::HTML.at_css.text
3.900k (± 2.9%) i/s - 19.700k in 5.056373sComparison:
NokogiriRust::HTML.at_css.text: 3899.6 i/s
Nokogiri::HTML.at_css.text: 61.0 i/s - 63.90x (± 0.00) slower
No plans at the moment, but I think about making an adapter between html5ever and Nokogiri in a similar way to Nokogumbo. In this case, the project may become more long-term and even be used as the main HTML parsing library for Nokogiri like gumbo is going to become in 2021.

Oldest comments (0)