If there is one message that I am trying to convey to the Strapi community, it is that it is possible to create any type of application with Strapi. Whether it's a simple blog, a showcase site, a corporate site, an e-commerce site, an API that can, by the way, be used by a mobile application and so on.
Due to its strong customization, you can create whatever you want with Strapi. Today, this tutorial will guide you to create an application used to scrape a website. I have been using Strapi in the past for a freelance mission which consisted of scraping several websites in order to collect public information.
Strapi was very useful because I built an architecture allowing me to manage a scraper in just a few clicks. However, what follows may not be the best way to create a scraping app with Strapi. There are no official guidelines, it depends on your needs and your imagination.
For this tutorial, we are going to scrape the jamstack.org site and more precisely the site generators section. This site lists headless CMSs like Strapi and others, but also site generators and frameworks such as Next.js, Gatsby or Jekyll.
We are simply going to create an app that, via a cron, will collect the site generators every day and insert them into a Strapi app.
To do this we will use Puppeteer to control a browser to extract the necessary information with Cheerio.
Alright, let's get into it!
Creating the Strapi application
- Create a Strapi application with the following command:
npx create-strapi-app jamstack-scraper --quickstart
This application will have a Sqlite database. Feel free to remove the --quickstart option to select your favorite database.
- Create your administrator by submitting the form.
-
Create the first collection type called scraper:
Content-Types Builder > + Create new collection type.


Great now you should be able to see your scraper by clicking on Scrapers in the side nav:

- Click on + Add New Scrapers

This view is not well organized, let's change that.
- Click on Configure the view and reproduce the following organization
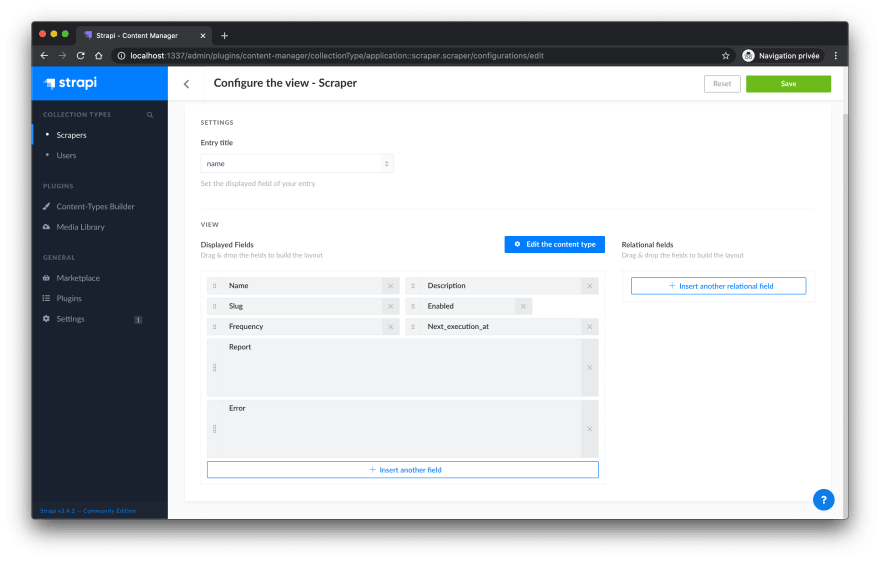
- Press save
By creating a Scraper collection type, you'll be able to manage the behavior of your scraper directly in the admin. You can:
1. Enable/Disable it
2. Update the frequency
3. See the errors of the last execution
4. Get a report of the last execution
5. See all the data scraped for this scraper with a relation
- Create another collection type called: site generator
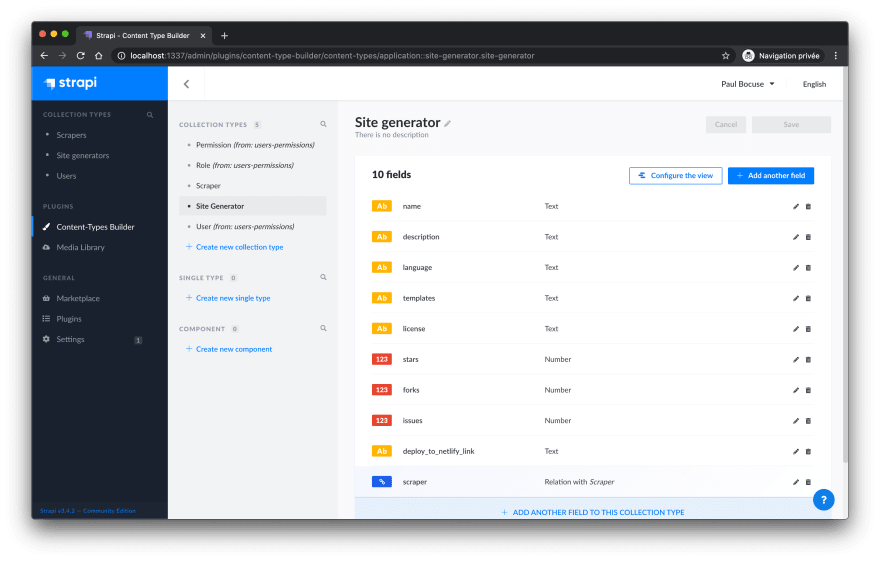
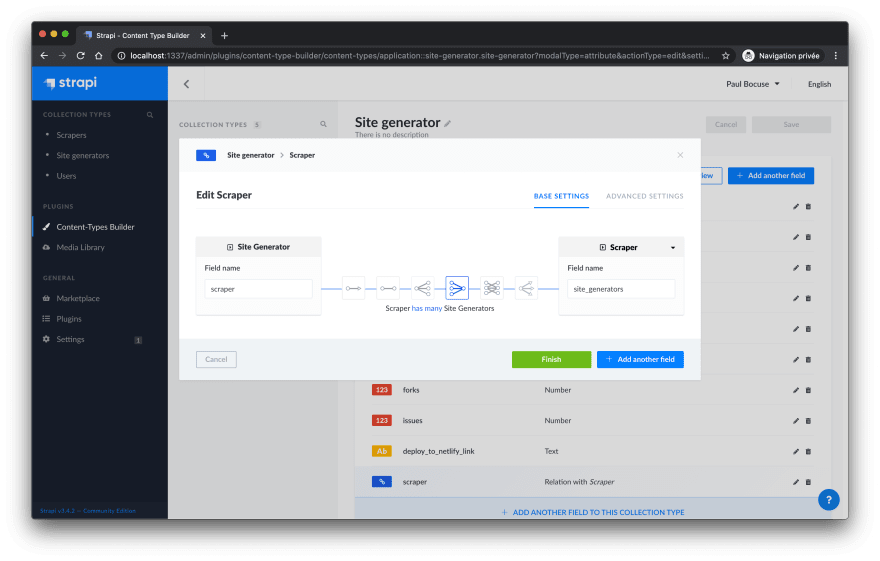
Perfect! Everything seems ready concerning the content in the admin!
Now let's create our scraper.
Creating the Scraper
- Click on Scrapers > + Add New Scrapers
- Create the following scraper:

What we have here is:
1. The name of the scraper.
2. The slug which is generated thanks to the name.
3. We disable it for now.
4. The frequency here is expressed using cron schedule expressions. `* * * * *` here means every minute. Since after testing we want to launch the scraper every day at, let's say, 3pm, it would be something like this: `0 15 * * *`
5. The `next_execution_at` will contains a string of the timestamp of the next execution. This way the scraper will respect the frequency. You will have more details after ;)
Let's dive into the code!
The first thing to do is make your application able to fetch your scraper with a slug.
-
Add the following code in your
./api/scraper/controllers/scraper.jsfile:
const { sanitizeEntity } = require('strapi-utils'); module.exports = { /** * Retrieve a record. * * @return {Object} */ async findOne(ctx) { const { slug } = ctx.params; const entity = await strapi.services.scraper.findOne({ slug }); return sanitizeEntity(entity, { model: strapi.models.scraper }); }, }; -
Only update the
findOneroute of your./api/scraper/config/routes.jsonfile with the following code:
{ "routes": [ ... { "method": "GET", "path": "/scrapers/:slug", "handler": "scraper.findOne", "config": { "policies": [] } }, ... ] }
Awesome! Now you are able to fetch your scrapers with the associated slug.
Now let's create our scraper.
- Create a
./scriptsfolder at the root of your Strapi project. - Create a
./scripts/scrapersfolder inside this previously created folder. - Create a
./scripts/starters/jamstack.jsempty file.
This file will contain the logic to scrape the site generators on Jamstack.org. It will be called by the cron but during the development, we will call it from the ./config/functions/bootstrap.js file which is executed every time the server restart. So this way we will be able to try our script each time we save our file.
In the end, we will remove it from there and call it in our cron file every minute. The script will check if this is the time to execute it or not thanks to the frequency of your scraper you'll define for it.
-
Add the following code to your
./scripts/starters/jamstack.jsfile:
const main = async () => { // Fetch the correct scraper thanks to the slug const slug = "jamstack-org" const scraper = await strapi.query('scraper').findOne({ slug: slug }); console.log(scraper); // If the scraper doesn't exists, is disabled or doesn't have a frequency then we do nothing if (scraper == null || !scraper.enabled || !scraper.frequency) return } exports.main = main; -
Update your
./config/functions/bootstrap.jsfile with the following:
'use strict'; /** * An asynchronous bootstrap function that runs before * your application gets started. * * This gives you an opportunity to set up your data model, * run jobs, or perform some special logic. * * See more details here: https://strapi.io/documentation/developer-docs/latest/concepts/configurations.html#bootstrap */ const jamstack = require('../../scripts/scrapers/jamstack.js') module.exports = () => { jamstack.main() };
Now you should see your scraper (JSON) in your terminal after saving your bootstrap file.
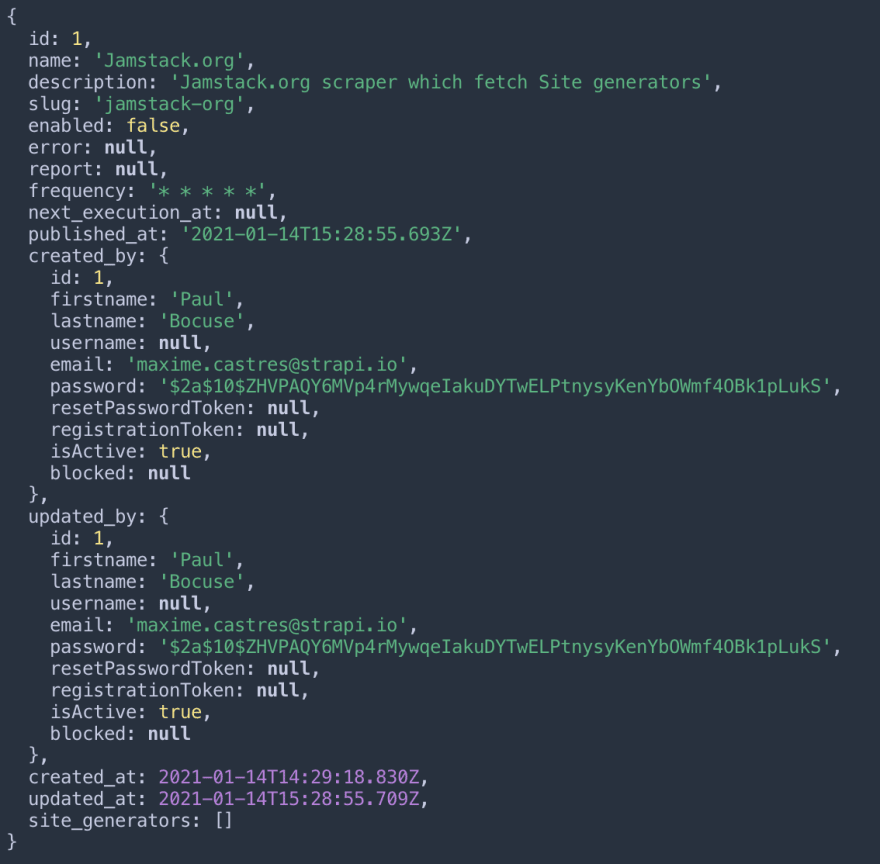
Great! Now it's time to scrap!
First of all, we are going to create a file containing a useful function for our script.
-
Create a
./scripts/scrapers/utils/utils.jsfile containing the following:
'use strict'
The first function will use the cron-parser package to check if the script can be executed depending on the frequency you set in the admin. We'll also use the chalk package to display messages in color.
-
Add theses packages by running the following command:
yarn add cron-parser chalk -
Add the following code to your
./scripts/scrapers/utils/utils.jsfile.
'use strict' const parser = require('cron-parser'); const scraperCanRun = async (scraper) => { const frequency = parser.parseExpression(scraper.frequency); const current_date = parseInt((new Date().getTime() / 1000)); let next_execution_at = "" if (scraper.next_execution_at){ next_execution_at = scraper.next_execution_at } else { next_execution_at = (frequency.next().getTime() / 1000); await strapi.query('scraper').update({ id: scraper.id }, { next_execution_at: next_execution_at }); } if (next_execution_at <= current_date){ await strapi.query('scraper').update({ id: scraper.id }, { next_execution_at: (frequency.next().getTime() / 1000) }); return true } return false } module.exports = { scraperCanRun }
This function will check if this is the time to execute the scraper or not. Depending on the frequency you set on your scraper, the package cron-parser will parse it and verify if this is the right time to execute your scraper thanks to the next_execution_at field.
Important: If you want to change the frequency of your scraper, you'll need to delete your next_execution_at value. It will be reset accordingly to your new frequency.
The next function will get all site generators we already inserted in our database in order to not fetch them again during the execution of the script.
-
Add the following function to your
./scripts/scrapers/utils/utils.jsfile.
'use strict' ... const getAllSG = async (scraper) => { const existingSG = await strapi.query('site-generator').find({ _limit: 1000, scraper: scraper.id }, ["name"]); const allSG = existingSG.map(x => x.name); console.log(`Site generators in database: \t${chalk.blue(allSG.length)}`); return allSG; } module.exports = { getAllSG, scraperCanRun }
The next function will simply get the current date for our report and errors log
-
Add the following function to your
./scripts/scrapers/utils/utils.jsfile.
'use strict' ... const getDate = async () => { const today = new Date(); const date = today.getFullYear()+'-'+(today.getMonth()+1)+'-'+today.getDate(); const time = today.getHours() + ":" + today.getMinutes() + ":" + today.getSeconds(); return date+' '+time; } module.exports = { getDate, getAllSG, scraperCanRun }
The last function will prepare the report of the last execution.
-
Add the following function to your
./scripts/scrapers/utils/utils.jsfile.
'use strict' ... const getReport = async (newSG) => { return { newSG: newSG, date: await getDate()} } module.exports = { getReport, getDate, getAllSG, scraperCanRun }
Alright! Your ./scripts/scrapers/utils/utils.js should look like this:
```bash
'use strict'
const parser = require('cron-parser');
const chalk = require('chalk');
const scraperCanRun = async (scraper) => {
const frequency = parser.parseExpression(scraper.frequency);
const current_date = parseInt((new Date().getTime() / 1000));
let next_execution_at = ""
if (scraper.next_execution_at){
next_execution_at = scraper.next_execution_at
}
else {
next_execution_at = (frequency.next().getTime() / 1000);
await strapi.query('scraper').update({
id: scraper.id
}, {
next_execution_at: next_execution_at
});
}
if (next_execution_at <= current_date){
await strapi.query('scraper').update({
id: scraper.id
}, {
next_execution_at: (frequency.next().getTime() / 1000)
});
return true
}
return false
}
const getAllSG = async (scraper) => {
const existingSG = await strapi.query('site-generator').find({
scraper: scraper.id
}, ["name"]);
const allSG = existingSG.map(x => x.name);
console.log(`Site generators in database: \t${chalk.blue(allSG.length)}`);
return allSG
}
const getDate = async () => {
const today = new Date();
const date = today.getFullYear()+'-'+(today.getMonth()+1)+'-'+today.getDate();
const time = today.getHours() + ":" + today.getMinutes() + ":" + today.getSeconds();
return date+' '+time;
}
const getReport = async (newSG) => {
return { newSG: newSG, date: await getDate()}
}
module.exports = { getReport, getDate, getAllSG, scraperCanRun }
```
Let's update our ./scripts/scrapers/jamstack.js file a little bit now. But let's add puppeteer first ;)
Adding Puppeteer and Cheerio
-
Add puppeteer and cheerio to your
package.jsonfile by running the following command:
yarn add puppeteer cheerio- Update your
./scripts/scrapers/jamstack.jsfile with the following:
'use strict' const chalk = require('chalk'); const puppeteer = require('puppeteer'); const { getReport, getDate, getAllSG, scraperCanRun } = require('./utils/utils.js') let report = {} let errors = [] let newSG = 0 const scrape = async () => { console.log("Scrape function"); } const main = async () => { // Fetch the correct scraper thanks to the slug const slug = "jamstack-org" const scraper = await strapi.query('scraper').findOne({ slug: slug }); // If the scraper doesn't exists, is disabled or doesn't have a frequency then we do nothing if (scraper == null || !scraper.enabled || !scraper.frequency){ console.log(`${chalk.red("Exit")}: (Your scraper may does not exist, is not activated or does not have a frequency field filled in)`); return } const canRun = await scraperCanRun(scraper); if (canRun && scraper.enabled){ const allSG = await getAllSG(scraper) await scrape(allSG, scraper) report = await getReport(newSG); } } exports.main = main; - Update your
Now save your file! You might have this message:

Yep, you didn't enable your scraper so it will not go further. So in order to continue, we will need to comment this code because we want to be able to code the scrape function without having to wait or what ;)
-
Comment the following portion of code:
'use strict' const chalk = require('chalk'); const puppeteer = require('puppeteer'); const { getReport, getDate, getAllSG, scraperCanRun } = require('./utils/utils.js') let report = {} let errors = [] let newSG = 0 const scrape = async () => { console.log("Scrape function"); } const main = async () => { // Fetch the correct scraper thanks to the slug const slug = "jamstack-org" const scraper = await strapi.query('scraper').findOne({ slug: slug }); // If the scraper doesn't exists, is disabled or doesn't have a frequency then we do nothing // if (scraper == null || !scraper.enabled || !scraper.frequency){ // console.log(`${chalk.red("Exit")}: (Your scraper may does not exist, is not activated or does not have a frequency field filled in)`); // return // } // const canRun = await scraperCanRun(scraper); // if (canRun && scraper.enabled){ const allSG = await getAllSG(scraper) await scrape(allSG, scraper) // } } exports.main = main;
You can save your file and now it should be fine!

Perfect! Now let's dive into scraping data!
Scraping the data
-
Update your
./scripts/scrapers/jamstack.jsfile with the following:
'use strict' const chalk = require('chalk'); const cheerio = require('cheerio'); const puppeteer = require('puppeteer'); const { getReport, getDate, getAllSG, scraperCanRun } = require('./utils/utils.js') const { createSiteGenerators, updateScraper } = require('./utils/query.js') let report = {} let errors = [] let newSG = 0 const scrape = async (allSG, scraper) => { const url = "https://jamstack.org/generators/" const browser = await puppeteer.launch({ args: ['--no-sandbox', '--disable-setuid-sandbox'] }); const page = await browser.newPage(); try { await page.goto(url) } catch (e) { console.log(`${chalk.red("Error")}: (${url})`); errors.push({ context: "Page navigation", url: url, date: await getDate() }) return } const expression = "//div[@class='generator-card flex flex-col h-full']" const elements = await page.$x(expression); await page.waitForXPath(expression, { timeout: 3000 }) const promise = new Promise((resolve, reject) => { elements.forEach(async (element) => { let card = await page.evaluate(el => el.innerHTML, element); let $ = cheerio.load(card) const name = $('.text-xl').text().trim() || null; // Skip this iteration if the sg is already in db if (allSG.includes(name)) return; const stars = $('span:contains("stars")').parent().text().replace("stars", "").trim() || null; const forks = $('span:contains("forks")').parent().text().replace("forks", "").trim() || null; const issues = $('span:contains("issues")').parent().text().replace("issues", "").trim() || null; const description = $('.text-sm.mb-4').text().trim() || null; const language = $('dt:contains("Language:")').next().text().trim() || null; const template = $('dt:contains("Templates:")').next().text().trim() || null; const license = $('dt:contains("License:")').next().text().trim() || null; const deployLink = $('a:contains("Deploy")').attr('href') || null; await createSiteGenerators( name, stars, forks, issues, description, language, template, license, deployLink, scraper ) newSG += 1; }); }); promise.then(async () => { await page.close() await browser.close(); }); } const main = async () => { // Fetch the correct scraper thanks to the slug const slug = "jamstack-org" const scraper = await strapi.query('scraper').findOne({ slug: slug }); // If the scraper doesn't exists, is disabled or doesn't have a frequency then we do nothing // if (scraper == null || !scraper.enabled || !scraper.frequency){ // console.log(`${chalk.red("Exit")}: (Your scraper may does not exist, is not activated or does not have a frequency field filled in)`); // return // } // const canRun = await scraperCanRun(scraper); // if (canRun && scraper.enabled){ const allSG = await getAllSG(scraper) await scrape(allSG, scraper) report = await getReport(newSG); // } } exports.main = main;
Let me explain what is going with this modification.
First of all, we can see that we are importing a function from another file we didn't create yet: ./scripts/scrapers/utils/query.js. These two functions will allow us to create the site generators in our database and updating our scraper (errors and report). We will create this file just after don't worry ;)
Then we have the scrape function that simply scrapes the data we want using puppeteer and cheerio and then use the previously explained function to insert this data in our database.
-
Create a
./scripts/scrapers/utils/query.jsfile containing the following:
'use strict' const chalk = require('chalk'); const createSiteGenerators = async (name, stars, forks, issues, description, language, template, license, deployLink, scraper) => { try { const entry = await strapi.query('site-generator').create({ name: name, stars: stars, forks: forks, issues: issues, description: description, language: language, templates: template, license: license, deploy_to_netlify_link: deployLink, scraper: scraper.id }) } catch (e) { console.log(e); } } const updateScraper = async (scraper, report, errors) => { await strapi.query('scraper').update({ id: scraper.id }, { report: report, error: errors, }); console.log(`Job done for: ${chalk.green(scraper.name)}`); } module.exports = { createSiteGenerators, updateScraper, }
As you can see we are updating the scraper at the end with this updateScraper function. Then we will uncomment the code that allows our scraper to be executed or not depending on the frequency if it's enabled etc...
-
Let's add it to our
./scripts/scrapers/jamstack.jsfile:
'use strict' const chalk = require('chalk'); const cheerio = require('cheerio'); const puppeteer = require('puppeteer'); const { getReport, getDate, getAllSG, scraperCanRun } = require('./utils/utils.js') const { createSiteGenerators, updateScraper } = require('./utils/query.js') let report = {} let errors = [] let newSG = 0 const scrape = async (allSG, scraper) => { const url = "https://jamstack.org/generators/" const browser = await puppeteer.launch({ args: ['--no-sandbox', '--disable-setuid-sandbox'] }); const page = await browser.newPage(); try { await page.goto(url) } catch (e) { console.log(`${chalk.red("Error")}: (${url})`); errors.push({ context: "Page navigation", url: url, date: await getDate() }) return } const expression = "//div[@class='generator-card flex flex-col h-full']" const elements = await page.$x(expression); await page.waitForXPath(expression, { timeout: 3000 }) const promise = new Promise((resolve, reject) => { elements.forEach(async (element) => { let card = await page.evaluate(el => el.innerHTML, element); let $ = cheerio.load(card) const name = $('.text-xl').text().trim() || null; // Skip this iteration if the sg is already in db if (allSG.includes(name)) return; const stars = $('span:contains("stars")').parent().text().replace("stars", "").trim() || null; const forks = $('span:contains("forks")').parent().text().replace("forks", "").trim() || null; const issues = $('span:contains("issues")').parent().text().replace("issues", "").trim() || null; const description = $('.text-sm.mb-4').text().trim() || null; const language = $('dt:contains("Language:")').next().text().trim() || null; const template = $('dt:contains("Templates:")').next().text().trim() || null; const license = $('dt:contains("License:")').next().text().trim() || null; const deployLink = $('a:contains("Deploy")').attr('href') || null; await createSiteGenerators( name, stars, forks, issues, description, language, template, license, deployLink, scraper ) newSG += 1; }); }); promise.then(async () => { await page.close() await browser.close(); }); } const main = async () => { // Fetch the correct scraper thanks to the slug const slug = "jamstack-org" const scraper = await strapi.query('scraper').findOne({ slug: slug }); // If the scraper doesn't exists, is disabled or doesn't have a frequency then we do nothing if (scraper == null || !scraper.enabled || !scraper.frequency){ console.log(`${chalk.red("Exit")}: (Your scraper may does not exist, is not activated or does not have a frequency field filled in)`); return } const canRun = await scraperCanRun(scraper); if (canRun && scraper.enabled){ const allSG = await getAllSG(scraper) await scrape(allSG, scraper) report = await getReport(newSG); await updateScraper(scraper, report, errors) } } exports.main = main;
Again, by saving your file you should have this message:
```bash
Exit: (Your scraper may not exist, is not activated, or does not have a frequency field filled in)
```
- Well first of all you need to set a
frequencyand remove any value that can be in thenext_execution_atfield. For this tutorial, we'll set a one-minute frequency to quickly see the result. Then you simply need to enable it:

-
Update your
./config/functions/bootstrap.jsto it's default value:
'use strict' /** * An asynchronous bootstrap function that runs before * your application gets started. * * This gives you an opportunity to set up your data model, * run jobs, or perform some special logic. * * See more details here: https://strapi.io/documentation/developer-docs/latest/concepts/configurations.html#bootstrap */ module.exports = () => {};- Update your
./config/functions/cron.jswith the following code:
'use strict'; /** * Cron config that gives you an opportunity * to run scheduled jobs. * * The cron format consists of: * [SECOND (optional)] [MINUTE] [HOUR] [DAY OF MONTH] [MONTH OF YEAR] [DAY OF WEEK] * * See more details here: https://strapi.io/documentation/developer-docs/latest/concepts/configurations.html#cron-tasks */ const jamstack = require('../../scripts/scrapers/jamstack.js') module.exports = { '* * * * *': () => { jamstack.main() } };- Activate the possibility to use cron by updating your
./config/server.jsfile with the following:
module.exports = ({ env }) => ({ host: env('HOST', '0.0.0.0'), port: env.int('PORT', 1337), admin: { auth: { secret: env('ADMIN_JWT_SECRET', 'ea8735ca1e3318a64b96e79cd093cd2c'), }, }, cron: { enabled: true, } }); - Update your
Save your file!
Now what will happen is that, at the next minute, the scraper will fill your next_execution_at value with the corresponding one according to your frequency, here, the next minute after.
So the next minute after the next_execution_at timestamp will be compared to the actual one and of course will be inferior or equal so your scraper will be executed. A new next_execution_at timestamp will be set to the next minute accordingly to this frequency.
Well, I think it's over for this quick and simple tutorial!
Conclusion


- Now let's change the frequency back to something normal, every day at x hour:

I hope that you enjoyed it!
If you want to keep learning then feel free to register to the Academy to become a Strapi expert or simply browse our blog to uncover any subjects you'd like.

Top comments (0)