This blog post was originally published at InfoWorld. I also gave a talk on this topic at QCon NYC recenctly (Slides).
Modern microservices architectures are event-driven, reactive, and choreographed (as opposed to being centrally controlled via an orchestrator). That makes them loosely coupled and easy to change. Right?
TL;DR: Not so easy! You will face challenges around understanding and managing the flow of events.
In this article I summarize my experience with choreographed microservices and look at various consequences and challenges of this approach. I use the typical business example of customer on-boarding (depending on the industry, this may be familiar to you as account opening ). I use Apache Kafka to represent the event bus in the pictures below, but don’t worry if you run a different stack. The same concepts still apply.
Choreographed microservices
Let’s assume the following services and events form your choreographed system:

The main challenges with that approach are illustrated by the following questions:
- How to change the flow of events?
- How to avoid losing sight of the flow? How do you maintain your understanding of it?
- How to manage SLAs and resilience of the overall flow? How can you recognize that something got stuck? How can you retry? How can you escalate?
- How to avoid wired coupling (e.g., that the credit check must know about customer registrations)?
Let’s examine the first two challenges, and we’ll address the last two in due course.
Changing the flow of events
Assume you need to add a check for criminal records. The idea of a choreographed system often is that you can add microservices without changing anything else. And you can actually add a criminal check service that reacts on certain events easily. But in order to make sense of the result, you will also have to adjust at least the customer service:

So, your choreographed system is not as loosely coupled as you might have expected.
Typically, people argue that the above event flow is flawed and you have to improve it to solve that problem. So let’s try an alternative flow:
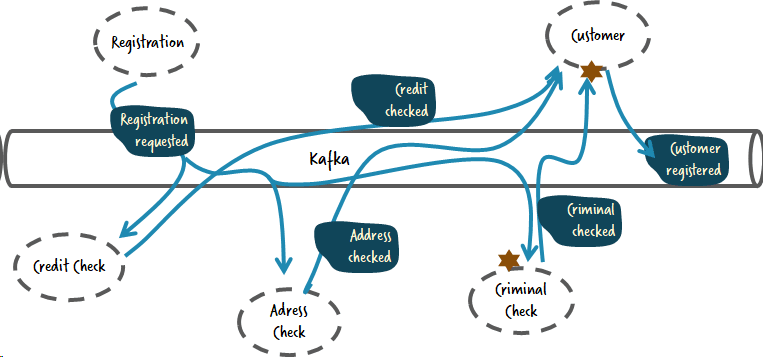
Now all services work in parallel, and the customer service is responsible for picking up all events. But still you have to change two services, as you want to process the result of the criminal check in the customer service.
Don’t get me wrong. I think it is unavoidable to have these kinds of changes. My point here is that you cannot avoid some degree of coupling in your architecture. Building an event-driven system will not magically spirit these requirements away.
Losing sight?
The next challenge is to understand what is going on in your architecture. Event-driven systems will have “ emerging behavior ” that will only be experienced during run time. You can’t understand this behavior by doing a static code analysis. Stefan Tilkov named this behavior “what the hell just happened,” and Josh Wulf wrote “the system we are replacing uses a complex peer-to-peer choreography that requires reasoning across multiple codebases to understand.” And the best description of this challenge comes from Martin Fowler, in “What do you mean by ‘Event-Driven’?”:
Event notification is nice because it implies a low level of coupling, and is pretty simple to set up. It can become problematic, however, if there really is a logical flow that runs over various event notifications. The problem is that it can be hard to see such a flow as it’s not explicit in any program text. Often the only way to figure out this flow is from monitoring a live system. This can make it hard to debug and modify such a flow. The danger is that it’s very easy to make nicely decoupled systems with event notification, without realizing that you’re losing sight of that larger-scale flow, and thus set yourself up for trouble in future years. The pattern is still very useful, but you have to be careful of the trap.

In a recent article on InfoQ (see “Monitoring and managing workflows across collaborating microservices”) I summarized the options to get back some oversight:
- Distributed tracing (e.g. Zipkin or Jaeger)
- Data lakes or analytic tools (e.g. Elastic)
- Process mining (e.g. ProM)
- Process tracking using workflow automation (e.g. Camunda)
As the article discusses, distributed tracing is too technical, misses the business perspective, and cannot tell you anything about the next steps in a flow that is stuck. So you might have no idea what is blocked by the error at hand and how to move on. Elastic and similar tools are great, but require some effort to set up and additional effort to provide a proper business perspective. Process mining typically focuses on log file analysis and not on event-driven architectures. And Process tracking deserves some discussion here.
Process tracking using workflow automation
You can attach your own component to read all events and keep track of certain behavior.

Behavior could mean “state changes” of single services:

When you are at that point, it might make sense to track the whole event flow:

That already allows you to use tooling from the workflow engine to monitor SLAs, for example:

But another great advantage of process tracking is that you can start acting upon certain behavior, such as timeouts:

Now this poses an interesting question: How to trigger that retry? In the above architecture it might mean resending the event that started the flow (address check required). But without context this is hard to tell.
If we look at tracking the overall event flow, we start to understand the context and might gain a better perspective on the retry:

You could even add some overall timeout to cancel the registration if it takes too long:

In a talk about process tracking at Kafka Summit San Francisco 2018 (see “Monitoring and orchestration of your microservices landscape with Kafka and Zeebe”), I demonstrated a concrete example of such a retail flow that is also available in code.
The cancellation might even need more complex logic like undoing certain activities. I wrote about such a scenario in “Saga: How to implement complex business transactions without two-phase commit.”
These are the first baby steps towards orchestration, as this workflow sends out events actively, which we will investigate in a second.
Managing SLAs, resilience, and the overall flow
But first let’s look at governance of this tracking workflow. Who owns it and where is it deployed?
People think of workflow engines as being centralized and heavyweight tools. But this is no longer always true. In microservices architectures workflow engines are a library used within one microservice. (I talked about this in “Complex event flows in distributed systems” at QCon London; see also “Avoiding the BPM monolith.”)
I give an example (Java and Spring Boot) in my “3 common pitfalls in microservice integration” talk, where I use the Camunda workflow engine simply to do stateful retries (source code on GitHub). It is really lightweight and easy to use. No need for a central engine or “orchestration” flows that are alien to the microservice universe.
To identify who can own such a tracking workflow, you need to find some person in your organization who owns the end-to-end business capability of on-boarding customers. And your company should actually have this somebody! A person who wants a smoothly flowing on-boarding process, cares about meeting SLAs or requirements, and knows how long it is acceptable to wait for certain retries and what happens if an SLA is missed.
In our example, I could see either the customer microservice assuming that responsibility, or you introduce some on-boarding microservice:

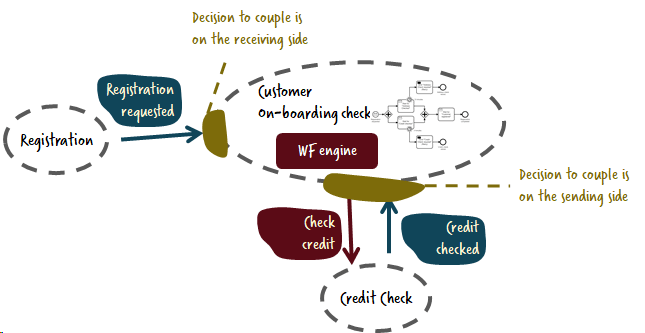
Coupling by events and commands
want to throw in another important thought. In the above example I once used an event called “address check required.” I see events like this a lot. But actually, this is not an event! It is a command in disguise. An event typically lets somebody know that something happened. It is a broadcast and you don’t care who picks it up.
When you emit a command such as “address check required,” you aren’t telling the world that something happened, but that you want the address checker to check something for you. It would be better to make that explicit with a check address command.
In my view, commands are nothing evil and don’t increase coupling. Every communication between two services involves some degree of coupling in order to be effective. Depending on the problem at hand, it may be more appropriate to implement the coupling within one side rather than the other.
Orchestration within microservices
When you add commands to the mix you end up with the customer on-boarding service owning some orchestration logic. But that’s natural, as this service already was responsible for important decisions around the overall flow, like reactions to timeouts and errors.

I It is important to realize that this really is a different picture from the “old” SOA and BPM days. There is no central workflow engine and no detached orchestration logic. Instead we simply define microservices with a clear business responsibility. Sometimes this responsibility involves state handling, and thus a workflow engine comes in handy. Sometimes commands are a more sensible approach to coupling, so in this case the microservice also does some orchestration. Again, an example of this approach in source code can be found on GitHub.
Compare the degree of coupling
Let’s revisit the change of introducing the additional criminal records check for the different approaches:

- In the choreographed scenario you could add and deploy the criminal check independent of any other change. It will listen to the “registration requested” event, for example. But the result will not be used before your customer service waits for that result and uses it for the final decision. That means you will have to change and redeploy that service too.
- In the orchestrated scenario you could add and deploy the criminal check independent of any other change. The checking service does not need to know anything about registrations; just provide a proper API, and it is ready to be used. In order to use it you will have to adjust the customer on-boarding service to call it, e.g. via a command message, then to wait for the resulting event.
The changes are quite similar, and the degree of coupling is actually the same. As a bonus the orchestrated approach seems more natural for me, as the criminal check now really acts like an internal service provider, not necessarily knowing all of its clients.
Summary
A good architecture needs to balance orchestration and choreography. This is not always easy to do, especially as orchestration is often considered something to be avoided to build flexible systems. But experience with choreographed systems clearly shows two main challenges of these systems: the difficulty of understanding their behavior and the difficulty of changing it. I hope the example sketched out above helps you to understand my line of thinking, which has so far worked well in many real-life customer projects around modern microservices architectures.
Bernd Ruecker is co-founder and chief technologist of Camunda. I am passionate about developer friendly workflow automation technology. Follow me on Twitter. As always, I love getting your feedback. Comment below or send me an email.

Top comments (0)