High availability what now?
In order to understand high availability in Azure, we first need to dig into some underlying Azure concepts. To explain these, I've cobbled together a diagram (it's not 100% accurate, but it does make it simpler to explain things).
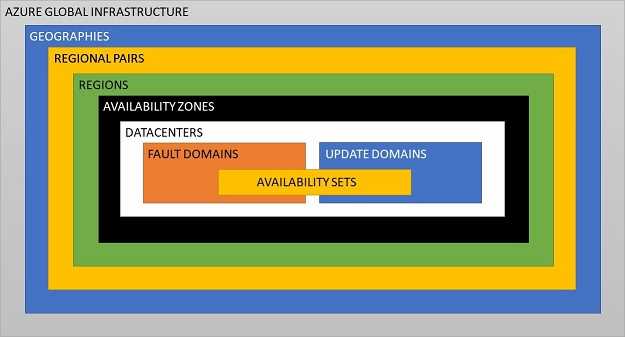
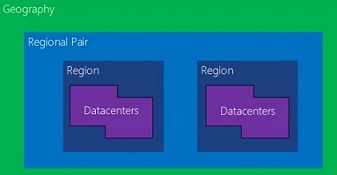
Geography
The "highest-level" entity that exists to meet data residency, compliance and sovereignty requirements. Currently there are 4 Azure geographies - Americas, Europe, Asia Pacific and Middle East + Africa. An Azure geography contains two or more Azure regions within it.
Region
As of the time of writing this post, there are 53 Azure regions (with 8 more announced) spread across 4 Azure geographies. Each Azure region contains a inter-connected set of datacenters (all datacenters within an azure region are connected via a dedicated regional low-latency network).
Some Azure regions support availability zones (each such region contains 3 or more availability zones).

Paired Regions
It is recommended that your redundancies span across a set of paired regions in order to meet data residency & compliance requirements even during planned platform maintenance & outages. Azure ensures that during planned platform maintenance, only one region in each pair is updated at a time. Also during multi-regional outages, azure ensures that at least one region in each pair will be prioritized for recovery.
Availability Zone
An availability zone comprises of one or more datacenters. Each availability zone has its own autonomous, independent infrastructure for power, cooling, and networking.
The Azure resources that support availability zones are listed here. Please note that these Azure resources can be categorized as follows:
- zone-specific (zonal) resources: Azure ensures that the resources are contained within a specific availability zone. VMs, managed disks and IP addresses fall in this category.
- zone-redundant resources: Azure automatically replicates the resources across multiple availability zones. Zone-redundant storage accounts and SQL databases fall in this category.
- non-zonal (regional) resources: Azure resource that are not supported by availability zones.
I'll talk about availability zones in detail in a future blog post in this series.
Datacenter
You can watch one of Mark Russinovich's excellent presentations (link1, link2, link3 and link4) to peek into what an Azure datacenter comprises of. Also you can take a virtual tour of an Azure datacenter.
Fault domain (physical server rack)
A single physical rack is considered as a fault domain, since all servers in that rack are connected by common points of failure (common power source and common network switch).
Update domain
An update domain is a logical grouping of machines that Azure upgrades/patches simultaneously during planned platform maintenance.
Availability Set
It's always a bad idea to run a production workload on a single VM. Best to provision multiple VMs in an availability set, which is a logical grouping of VMs within a datacenter across multiple fault & update domains.
When you create multiple VMs within an availability set, Azure distributes them across these fault & update domains. This ensures that at least one VM is remains running in event of either a planned platform maintenance (only one update domain in an availability set is patched at a time) or in the event of a server rack facing hardware failure, network outage or power supply issues.
My next blog post will explore availability sets for VMs in detail.
Preemptive FAQs
What about VM scale sets?
VM scale sets exist for horizontal scaling under load. In my opinion, they have almost nothing to do with redundancies for high availability. So I'll be excluding them from this particular blog series. Perhaps I'll address them in a future series on horizontal & vertical scaling for Azure resources.
Aside: Horizontal scaling & high availability address slightly different issues (performance & reliability respectively). The former adds additional instances when under load to ensure performant service. The latter adds redundant instances (irrespective of load) to prevent service disruption during outages.
Will I address high availability on Azure's government cloud?
No. I know very little about Azure's government cloud. You're welcome to read the documentation yourself.

Top comments (0)