A couple of months ago, Google announced a big change in how they report URL performance in Search Console (clicks, impressions, average position and average CTR). In this post, we explain what this change is all about and what it means for SEOs.
Google to show data only consolidated by canonical URL from April 10th
Although during this couple of months we were still able to check the “old view” with the old data, from April 10th that disappeared and left us with the new version where Google consolidates the information to the canonical URL instead of showing the real URL that appeared to the user in the search results.
More on that later, but first, let’s do a small recap on the importance of URLs and what a canonical URL is.
The importance of URLs in SEO
If you have a technical background, it’s really easy to notice the importance of URLs in SEO, if you understand that for Google, a URL is like an “id” on a database. An “id” can be a number or a string that identifies a resource in a database unequivocally. So it should not change over time.
So for Google, any URL it finds while crawling the web is the “id” for a unique web page, which contains information it may want to index and show to users when they search for something that page is relevant for.
If you have two different URLs that show exactly the same content, that’s considered “duplicated content” and Google needs to know which of the two URLs is “the good one”, the one it can show to the users when they search. Also, there may be links (both internal links on that same website and external links from other websites) pointing to both pages, so Google needs a way to know which one is “the good one” to assign and calculate the correct value for those pages.
The difference between a canonical and a non-canonical URL
That’s where the concept of “canonical” appears: a canonical URL is “the good URL” for a set of different URLs (2 or more) that show the same content.
Google offers different methods to handle this problem on your own (for example a 301 redirect or the canonical tag), and their systems also have rules to try to solve the problem on their own if you don’t do it.
Because of the way the web, the servers and the dev frameworks work, it is normal that several URLs which show the same content can exist, so we as SEOs need to address those and implement the mechanisms Google gives us.
These are common scenarios where duplicated content should be handled with 301 redirects (as the extra URLs do not add any value to the users):
www vs non-www URLs (https://frontity.org/careers vs https://www.frontity.org/careers)
http vs https URLs (https://frontity.org/careers vs http://frontity.org/careers)
URLs with and without a slash at the end (https://frontity.org/careers vs https://frontity.org/careers/)
And these are common scenarios where duplicated content should be handled with a canonical tag (as the extra URLs have a purpose on their own and are somehow different for users but duplicated for search engines):
Mobile versions that are served on a different URL (https://en.m.wikipedia.org/wiki/Progressive_web_applications vs https://en.wikipedia.org/wiki/Progressive_web_applications).
AMP versions that are served on a different URL (https://www.aleydasolis.com/en/search-engine-optimization/pwas-seo-what-are-they-why-you-need-one-and-how-to-optimize-for-them/ vs https://www.aleydasolis.com/en/search-engine-optimization/pwas-seo-what-are-they-why-you-need-one-and-how-to-optimize-for-them/amp/).
Another scenario is the one where we don’t handle the canonicalization problem in a correct way and/or Google’s systems decide that a URL A is a duplicate from URL B and auto-assign a different canonical URL (URL B) to it. In these cases URLs will be consolidated even though we didn’t specify it to Google.
In these last 2 groups is where interesting things happen, and where we can have problems (and also benefits) with the new approach Google implemented in Search Console.
What does this change mean for SEO?
Basically, according to the previous scenarios, we have three different cases:
Cases where the “duplicated URL” (which is correctly canonicalized to the canonical URL by us or by Google) does not appear in search results. For example: if we have https://frontity.org/careers vs https://www.frontity.org/careers).
Cases where the “duplicated URL” (which is correctly canonicalized to the canonical URL by us or by Google) appears in search results. For example: alternate mobile or amp URLs like amp.domain.com or m.domain.com.
Cases where the “duplicated URL” (which is not 100% duplicated but Google detects it as that) appears in search results in some queries. For example: when you have a couple of URLs very similar and with very few content, and one is detected by Google as the canonical but it will show the “duplicated” one if the query contains some of the specific information that only appears on the “duplicated” one.
Advantages of this change, according to Google
- (1) The ability to see a “full picture” about a specific piece of content in one property
- (2) your mobile or AMP pages will also show as one property and
- (3) it will also improve the AMP and Mobile-Friendly reports by showing more data.
Prior to this change, if you had your mobile specific or AMP pages on a subdomain (e.g. amp.domain.com or m.domain.com), you would get clicks and impressions for your site divided on each of the subdomains (www.domain.com, amp.domain.com, m.domain.com).
This was a problem: if you had a site (www.domain.com) and decided to implement AMP on a subdomain (amp.domain.com), once it was implemented, the performance data Search Console showed for mobile devices (as AMP URLs only show up in Google’s search results on mobile devices) would stop appearing on the www.domain.com property in Search Console. Instead, it would start appearing on the amp.domain.com property, causing a mess in your data and complicating your analysis of it.
From now on you will get all the information (if you have your pages correctly canonicalized to the main version) on the www.domain.com property, and no information on amp.domain.com.
This is clearly a good thing and probably the main reason behind the change of approach on Google’s side.
The disadvantages
On the other hand, as SEO analysts (and data analysts), we love having as much data as possible and being able to group it or segment it as we want in order to get knowledge and use it to make decisions.
The first problem comes with losing data. With the analysis done while the two versions of the data were available, we could easily check that we are missing data compared to what we had before:
This is the data for URLs that contain /amp/ with the old view:

This is the data for URLs marked as “AMP” by Google in the new view:
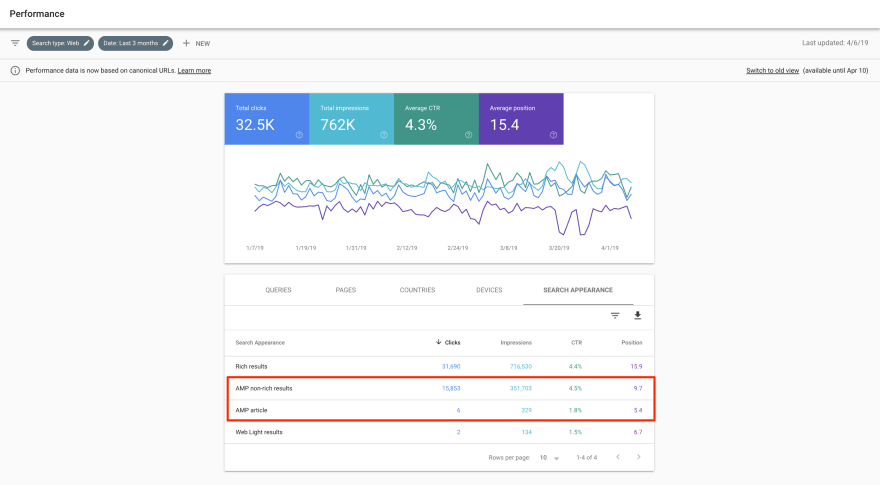
We can clearly see that, for the same period, we have different data:

So, what happened here? Are there URLs that contain “/amp/” but are not appearing as AMP results according to Google? If that is the case, why is that? Do we have /amp/ URLs that don’t have the canonical tag set up correctly? Or maybe everything is just fine on our side but the data is different because of how Google calculates it?
This is a problem because we probably cannot know, and Google probably won’t share any specifics, so we can just forget about the old data.
The other problem we have is that we may not get the data for specific URLs that may be canonicalized by Google systems but sometimes showed in search results because they are not completely identical.
For example, we have a product on our website which has three variations, each of them with their own URL. The name of the product is the same in the three cases, the only things that change are the product reference from the manufacturer and some of its characteristics. Although it is the same product, the reason why there are three is because they have different versions (with small changes in characteristics), and we don’t consolidate them to one URL because people search both for the product name and for the product reference.
Google detects these three URLs as duplicates, and its systems select one of them as the canonical, showing that URL whenever some searches for the product name. However, when someone searches for the product reference, it shows the “duplicated” URL, the one which has that specific query the user searched for.
In that case, if we get those clicks and impressions assigned to the “canonical URL”, we are missing valuable information (as we may want to use this data to decide if it is worth to index all the variations of the product, or just one of them and canonicalize the rest).
Final thoughts
Although there are some advantages with this change, especially for non-advanced users, we think it’s a step back for SEOs as we are clearly losing data and the ability to analyse things we could before the change.
The main advantage of the change had another way of being done in the old Search Console and was called “property sets”. This allowed you to group different properties (domain.com, amp.domain.com and m.domain.com) and get all the data grouped. This was perfect because you could see the aggregated data and the segmented data, without losing any information.
We hope that at least, in the near future, Google gives us a way to get the data back so we can see the aggregated data as well as the data by specific URL, as Lino Uruñuela suggested in this tweet.

This post was originally written by Christian Oliveira
and published at frontity.org/blog.

Top comments (0)