Anotar que este articulo se basa en el articulo de freeCodeCamp publicado por Samer Buna aquí, se trata de una traducción he interpretación del mismo intentando aportar mi punto de vista.
Cuando un proyecto empieza su andadura lo que ocurre en el 90% de los casos es que la escalabilidad no es una prioridad en el diseño y desarrollo, lo normal cuando sale este tema es que alguien del equipo de desarrollo diga: “de momento no tenemos tantos usuarios”, esto aunque cierto es un error ya que las aplicaciones que son diseñadas para escalar son capaces de pasar a producción com muchas más garantías que las que no, aunque a veces para esto último la escalabilidad no es lo único necesario.
En el caso de Node.js la escalabilidad no es algo que se aya tenido que incorporar con el paso del tiempo, sino que está desde el inicio para permitir que las aplicaciones sean diseñadas y desarrolladas desde el principio en base a este concepto. De hecho se llama Node para enfatizar la idea de que una aplicación Node debe comprender pequeños nodos que se comunican entre si.
El módulo de cluster de Node no solo proporciona una solución lista para utilizar toda la potencia de la CPU de una máquina, sino que también ayuda a aumentar la disponibilidad de sus procesos y ofrece una opción para reiniciar toda la aplicación sin tiempo de inactividad.
Estrategias para la escalabilidad
La carga de trabajo suele ser la razón por la que se plantea la escalabilidad, pero no es la única ya que la disponibilidad y la tolerancia a fallos también son motivos por los que se debe plantear esta técnica. Principalmente hay tres formas de abordar la escalabilidad:
Réplica
La forma más sencilla de escalar una aplicación de cierto tamaño es copiarla y hacer que cada copia se encargue de una parte de la carga de trabajo (usando un balanceador por ejemplo). Esta aproximación es sencilla y con un bajo coste en cuanto a desarrollo, es la mínima posible que se puede hacer ya que Node.js incorpora el módulo cluster que permite implementar esta estrategia de forma sencilla en un solo servidor.
Descomposición
La estrategia de descomposición consiste en dividir en funcionalidades o servicios una aplicación. Con esto lo que conseguimos son distintas aplicaciones de un tamaño muy reducido con diferente código base, que pueden tener distintas bases de datos y interfaces de usuario.
Esta estrategia se asocia al concepto de Microservicios, donde “micro” se refiere a que estos servicios deberían ser lo más pequeños posible, pero en realidad no es el tamaño lo que se busca sino desacoplar los multiples servicios que conforman una aplicación y aumentar la cohesión entre ellos. Esta estrategia es mucho más difícil de implementar y puede acabar provocando problemas a largo plazo, pero si se hace bien tiene muchas ventajas.
Separación
Como tercera estrategia podemos separar en multiples instancias la aplicación, donde cada instancia se encarga solo de una parte de los datos de la aplicación. Esta estrategia es conocida como particionado horizontal o sharding en el campo de las bases de datos. El particionado de los datos necesita de un paso previo al procesado para determinar donde se deben tratar dichos datos.
La mejor forma de escalar una aplicación de cierto tamaño puede pasar por el uso de las tres estrategias anteriores. Aunque Node.js es capaz de aplicar las tres estrategias vamos a centrarnos en la primera de ellas con las herramientas nativas que proporciona Node.js.
El módulo cluster
El módulo cluster se utiliza para permitir balanceo de carga sobre un entorno de CPU con multiples procesadores. Se basa a su vez en el modulo fork y sencillamente permite hacer procesos hijo del proceso principal por cada core de CPU que se disponga.
La estructura de lo que hace el módulo es sencilla. Se crea un proceso master y este hace fork de un número de workers y los maneja. Cada proceso worker representa una instancia de la aplicación que queremos escalar. Todas las peticiones entrantes son manejadas por el proceso master, que decide que proceso worker ha de encargarse de la petición entrante.
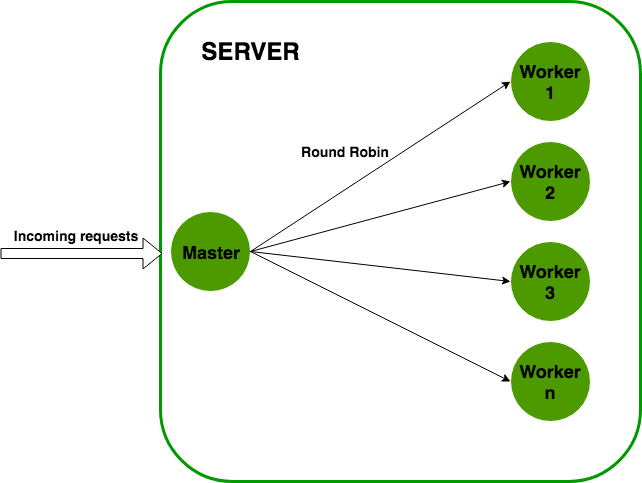
El proceso master sencillamente se encarga repartir la carga entre los distintos workers haciendo uso de un algoritmo round robin, con esto se distribuye la carga entre los nodos disponibles de forma equitativa, empezando por el primer nodo y mandado una petición a cada nodo de la lista hasta llegar al último, momento en el que vuelve a empezar por el primer nodo.
Aunque hay algoritmos que permiten parametrizar prioridades o seleccionar el último nodo al que se mandó una petición, este es el mas sencillo de implementar y permite una distribución de la carga uniforme.
Balancear un servidor HTTP
La forma más sencilla de probar el módulo cluster es con un sencillo servidor HTTP hecho en Node.js, a continuación se tenemos un pequeño código con un servidor web mínimo simulando algo de trabajo de CPU:
Antes de empezar vamos a hacer un primer test para tener una referencia de cuantas peticiones podemos manejar con un solo nodo. Para ello usaremos la herrmienta Apache benchmarking, ejecutaremos el siguiente comando:
$ ab -c200 -t10 -k [http://localhost:8080/](http://localhost:8080/)
Con este comando vamos a lanzar 200 conexiones concurrentes durante 10 segundos usando la opción de Keep Alive para aumentar la respuesta del servidor.
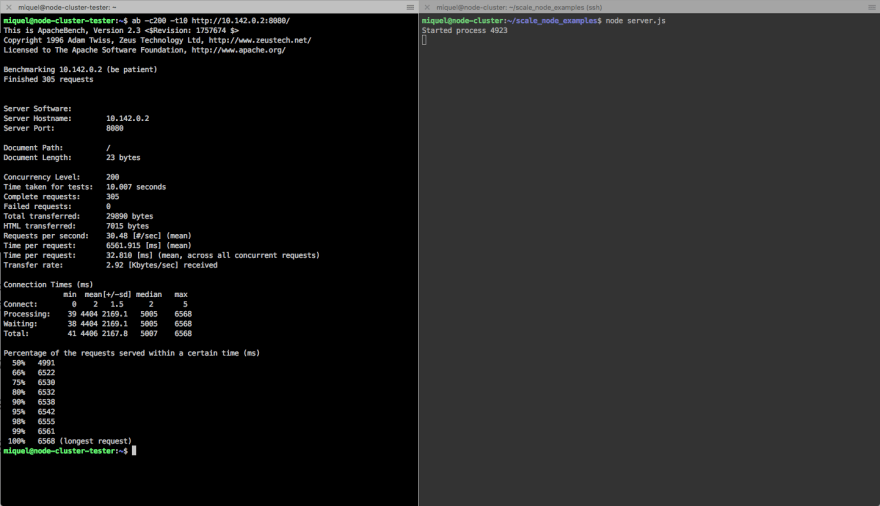
Por supuesto estos resultados pueden variar en función de la máquina en la que se ejecute. A continuación se muestran las métricas más relevantes:
Complete requests: 305
Failed requests: 0
Total transferred: 29890 bytes
HTML transferred: 7015 bytes
Requests per second: 30.48 [#/sec] (mean)
Time per request: 6561.915 [ms] (mean)
Time per request: 32.810 [ms] (mean, across all concurrent requests)
Transfer rate: 2.92 [Kbytes/sec] received
Con estos datos de partida ya podemos escalar la aplicación usando el módulo cluster, para ello usaremos el siguiente código que hace uso del fichero server.js anterior:
Inicialmente en este fichero se requiere los módulos cluster y os, vamos a usar este último para poder obtener el número de CPU cores que tiene la máquina sobre los que va a trabajar cada proceso, para ello usamos la función os.cpu().
El módulo cluster nos da el valor booleano isMaster para determinar si el fichero cluster.js se está cargando como master o no. La primera vez que se ejecuta el fichero, se ejecuta como master y por tanto isMaster está establecido a true. En este caso es cuando queremos empezar a hacer fork de los procesos en función de las CPUs disponibles.
Al leer el número de CPUs disponibles con el módulo os podemos hacer un simple bucle for con el que lanzamos el método cluster.fork y crear los distintos workers. Cuando se ejecuta la linea de cluster.fork el fichero actual se vuelve a ejecutar, pero esta vez isMaster devolverá false, adicionalmente ahora también se dispone de otro parámetro denominado isWorker que en este caso si devolverá true.
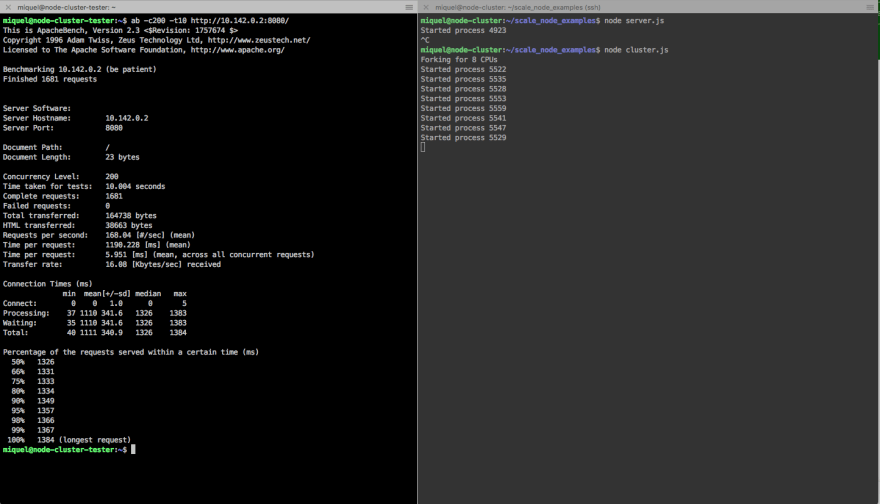
Ahora cuando volvemos a repetir el test podemos ver como cada proceso muestra su id y al ejecutar la herramienta de benchmark obtenemos los siguientes resultados:
Complete requests: 1681
Failed requests: 0
Total transferred: 164738 bytes
HTML transferred: 38663 bytes
Requests per second: 168.04 [#/sec] (mean)
Time per request: 1190.228 [ms] (mean)
Time per request: 5.951 [ms] (mean, across all concurrent requests)
Transfer rate: 16.08 [Kbytes/sec] received
Si comparamos los resultados de la dos pruebas podemos ver claramente un incremento significativo en todos los resultados a excepción de los tiempos que se ve una bajada considerable en los tiempos de respuesta.
Así de sencillo es empezar a usar las capacidades de cluster de Node.js

Top comments (0)