For applications that desire strong consistency, it is important to not only have all replicas in the cluster be always in sync, but also to have application's knowledge of a transaction's outcome consistent with the actual outcome in the database. If the application is uncertain about a transaction's outcome, it must first resolve it so that it can either do nothing, retry the transaction, or arrange for external resolution.
There are many situations that leave the client uncertain of a transaction's outcome.
Let us first look at how a write transaction is processed in Aerospike. Executing a write request involves many interactions between the client, master, and replicas as follows.
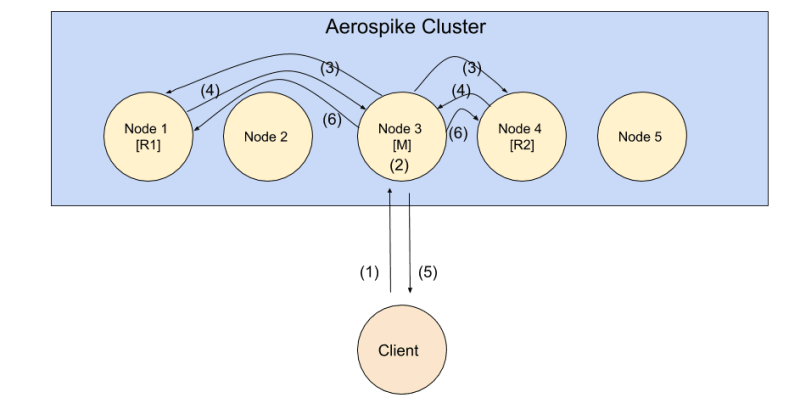
- The client sends the request to the master.
- Master processes the write locally.
- Master sends updates to all replicas.
- Replicas acknowledge to the master after applying the update locally.
- After receiving acknowledgements from all replicas, master returns success to client.
- Master sends an advisory "replicated" message to all replicas. Replicas are then free to serve this version without having to consult with the master.
Sources of uncertainty
There are failures that prevent a write from successfully completing and/or client from receiving a clear success or failure status.
Client, connection, and master failures
Failures like a client crash, connection error, node failure, or network partition can happen at any moment in the above sequence. Any of them can leave the client uncertain about a write's outcome. The client must resolve the uncertainty so that it can achieve the intended state.
In-Doubt status
The client can also receive the "in-doubt" flag in a timeout error. The flag signifies that the master has still not finished the replication sequence with all replicas. Clearly, the client, connection, and master all must be healthy for a timeout error to be returned with the in-doubt flag set.
Why wouldn't the master finish the replication sequence? The causes can be many including slow master, network, and/or replica; node and/or network failure, storage failure, and potentially other failures. In such a case, the time for recovery to be completed, either automated or manual, and the write to be resolved can be unpredictable.
How common are such uncertainties?
The frequency of the events will be determined by factors like the size of the cluster and load. The following table shows these events are common enough to ignore if the application desires strong consistency.
Aerospike model
It is important to understand the transaction model in Aerospike before we describe a solution. Aerospike was designed for speed@scale, with the goal of keeping most common operations simple and predictably fast, and deferring complexity to applications for less common scenarios.
Transactions in Aerospike span a single request and a single record. The API does not support a notion of a transaction id or a way to query a transaction status. Therefore, the application must devise its way to query a transaction status.
The application links with the client library (Smart Client) that directly and transparently connects to all nodes in the cluster and dynamically adapts to cluster changes. Therefore, simply retrying a transaction that failed due to a recoverable cluster failure can result in success.
Resolving uncertainty: Potential solutions
Some intuitive potential solutions unfortunately don't always work.
Potential solution 1: A polling read back in a loop until the record generation reflects an update.
Note the read must look for the generation (ie, version) of the record that reflects the write. On a timeout after several read attempts, the application may attempt to ascertain a failed write by "touching" the record that increments its generation without changing any data.
Case 1. The write sequence has completed.
Assuming no subsequent updates, the read will return the prior version if the write failed. Otherwise it will return the new version.
However, if there are subsequent updates, the latest version will be returned and there is no way of knowing the outcome of the write in question.
Case 2. The write sequence is still in progress.
If the read request goes to the same master, the read will return the prior version if the write is not completed yet. If the client attempts a "touch"in this case, it will be queued for the original write to finish (and may time out). The write's outcome remains unknown.
If the read request is directed to a new master because of a cluster transition, the new master will return the new version (ie, updated by the write in question, assuming no subsequent updates) if the write was replicated to a replica in the newly formed cluster prior to the cluster transition. Otherwise the previous version will be returned. If the client attempts a "touch"in this case, the original write will lose out (ie, fail when the cluster reforms) to the version in the new cluster regime. Just as in Case 1, if there are subsequent updates in the new cluster, the latest version will be returned and there is no way of knowing the outcome of the write in question.
Thus, this potential solution cannot be used to resolve a write's outcome.
Potential solution 2: Retry the write
When a retry can work:
- when the write is idempotent: Great, as the application knows which writes are idempotent,
- when the original request has failed: Good if the application knows, e.g., when there is a timeout with no in-doubt flag, and
- when there is a newly formed cluster and the write was not replicated to it: Yes, but the application does not know if this is the case.
When a retry will not work:
A retry is not safe because it will duplicate the write when:
- the original write sequence has since completed successfully, or
- the new cluster has the write replicated to it prior to the partition.
Again, this potential solution doesn't work in a general case.
A general solution
In order to query the status of a write, the application must tag the write with a unique id that it can use as a transaction handle. This must be done atomically with the write using Aerospike's multi-operation "operate" API.
It also is very useful to implement a write with"only-once" semantics, and safely retry when there is uncertainty about the outcome. This can be accomplished by storing the txn-id as a unique item in a map or list bin in the record. Aerospike has the create-only map write flag to ensure that the entire multi-operation "operate" succeeds only-once. (Other mechanisms such as predicate expressions may be used instead.) Subsequent attempts would result in an "element exists" error and point to a prior successful execution of the write.
Adding a key-value ordered map, txns: txn_id => timestamp:
key: {
… // record data
txns: map (txn_id => timestamp) // transaction tag
}
Below is the pseudo code for the general solution.
A simpler solution?
Requiring a txns map or list in each record and tagging and checking txn-id with each write, and also trimming txns can be a significant space and time overhead. Can it be avoided or simplified?
If consistency is absolutely needed, this (or equivalent variations) is the recommended solution. Without an in-built support in the API or server, currently this is a general way to resolve uncertainties around a transaction's outcome and ensuring "only/exactly once" semantics.
However, simplifications are possible. Here are some things to consider to devise a simpler solution:
- Frequency of updates: If writes are rare (e.g., daily update to usage stats), it may be possible to read back and resolve a write's outcome.
- Uniqueness of update: Can a client identify its update in another way (i.e., without a txn-id) in a multi-client writes scenario?
- A handful of write clients: If there are a small number of write clients, a more efficient scheme can be devised such as client-specific versions in their own bins (assuming a client can serialize its writes).
- Likelihood of client, connection, node, or network partition failures: If such failures are rare, an application may decide to live with lost or duplicate writes for less critical data.
- Ability to serialize all writes through external synchronization: A simpler solution can be devised in this case.
- Ability to record uncertain writes and resolve them out of band: Log the details for external resolution and make appropriate data adjustments if necessary.
Conclusion
Strong consistency requires the application to resolve uncertain transaction outcomes and implement safe retries. In order to query and resolve uncertain outcomes, the application needs to tag a transaction with a unique id. To achieve exactly-once write semantics, the application can use mechanisms available in Aerospike Operator, Map/List, and Predicate Expressions. In some cases, knowledge of data, operation, and architecture may be used to simplify the solution.

Oldest comments (0)