
New format
I enjoy reading research papers. Here you can get an overview of the latest concepts and ideas in the field. You can get an overview of the newest tool and approaches from the top companies.
You can also get the results of the academic research performed by scientists on a big chunk of data. Reading a research paper is like reading a book, but in a much smaller format and with a lot of new information per page.
Recently, I started to look for and read research papers about testing in the various types of distributed systems.
That's why I want to start a series of posts with a common title: "Paper Review". Here I will share the most exciting papers about quality that I found.
Distributed systems
What is a "distributed system"? In its simplest definition, it is:
- group of computers that
- work together on a given task and
- communicate with each other by passing messages and
- appear to a user as a single machine
It turns out that distributed systems are everywhere.
The Internet is in some way a distributed system of computers that provide information to the user.
Web / Application monolithic backend is a distributed system in a case when deployed onto multiple servers.
Backend based on microservices is also distributed system. Dozens and hundreds of microservices are working together to provide some results. And each microservice also can have multiple copies.
Blockchains are distributed systems. Underneath it is a system of many computers sending each other information about a newly added block of transactions.
Almost any modern application contains parts distributed in nature: storages, message queues, load balancers, etc.
Testing in distributed systems
If you are working in IT, you know that testing can be challenging and complex. The main complexity is that the number of test cases and the number of potential issues in the system are almost infinite.
It even gets more challenging when the system is distributed.
You need to check application functionality.
But you also need to check how data is replicated between different nodes in the storage system.
You need to test any synchronization issues between nodes located in different timezones (e.g., providing user data from other CDNs).
And the main thing - you need to test how the system will behave when one or more nodes are down (restarting or broken).
It is complicated for a couple of nodes, but what can we do if the number of nodes is 100s or 1000s?
An overview
The paper "Simple Testing Can Prevent Most Critical Failures" by Ding Yuan et al. gives a good view of which failures can happen in real-world production systems.
The authors performed an analysis of critical failures of the five distributed systems: Cassandra, HBase, HDFS, MapReduce, and Redis.
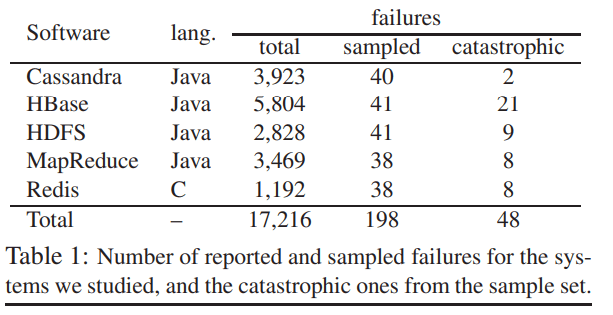
During an investigation, they reveal a lot of interesting findings. Here are the most interesting ones:
-
The majority of the failures require more than one input event, but it requires no more than three events in most cases. 50% of the losses require only two nodes.
This finding says that you don't need to simulate a large production cluster with thousands of nodes for reproducing the failure or for testing. You need only two or three nodes. It simplifies the approach to building test environments.

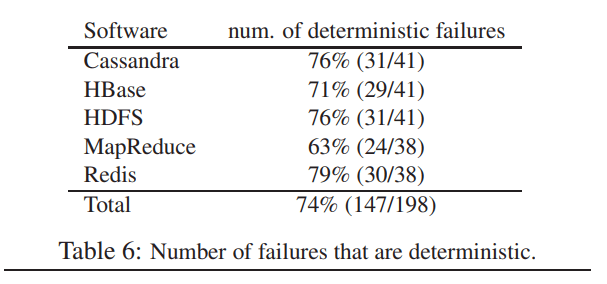
The majority (74%) of the failures are deterministic. It means that it is possible to get the correct order of multiple events to simulate the failure. Random-based test generation can help, but an order of events is defined and can be transformed into a test case in most cases.
76% of failures print log error messages and have logged inputs. So they can be clearly understood and reproduced.
The unit test can reproduce 77% of the production failures! Do not underestimate the power of unit testing. Integration and end-to-end testing can reveal these problems - but they didn't find them as these bugs slipped to production.

92% of the failures are due to incorrect error handling (fatal and non-fatal). A lot of error handlers were too general or missed some extra corner cases. In some cases, it even contains TODO and FIXME comments. It means that error handling code should be analyzed by external tools and other developers and testers to find potential gaps.

Conclusion
As you see, distributed systems add additional complexity to testing due to their scale. But it turns out that the most trivial testing approaches like unit testing of error-handling cases - can prevent the majority of such issues.
We, as quality engineers, should help developers to identify such potential gaps in coverage. It can be by a manual investigation; it can be by improving existing code coverage scanners.
What was your most exciting bug found in a distributed environment?

Top comments (0)