
Today, we’ll dive deep into monitoring hosts. The good news is that we’ll point you to some shortcuts on how to set up host monitoring in an easy way. The bad news is that we won't be doing any percussive maintenance on any host.
Step 1: Getting the Data In
To monitor hosts, you have to set a few layers in place. Doing all this by yourself would be the hard way. You may ask: "How hard could it be?". Well, AppSignal started as a side project in 2012 because a group of "How hard can it be?" people worked on this system for three years before it was in a shape we were somewhat proud of.
After monitoring thousands of billions of requests, we've learned all kinds of things along the way. So, regardless of whether you choose AppSignal to monitor your app, think thrice before you roll out a solution by yourself.
These challenges go from emitting the data in a lightweight manner to ingesting masses of data in a way that doesn't influence the hosts you are monitoring. If you think that’s cool, we wrote a bit about how we do it in our documentation.
The Automated Part
If you monitor your app with AppSignal, host metrics are collected by the agent every minute. We try to give as many insights as possible right ‘out-of-the-box’, so you don't need to manually set up anything.
We love the combination of many things working right away, and also being able to continuously tweak things. So, with this, you can also turn it off if you want to.
Out-of-the-box, we collect the following metrics:
| Metric | Description |
|---|---|
| CPU usage | User, nice, system, idle and iowait in percentages. Read more about CPU metrics in our academy article. |
| Load average | 1 minute load average on the host. |
| Memory usage | Available, free and used memory. Also includes swap total and swap used. |
| Disk usage | Percentage of every disk used. |
| Disk IO | Throughput of data read from and written to every disk. |
| Network traffic | Throughput of data received and transmitted through every network interface. |
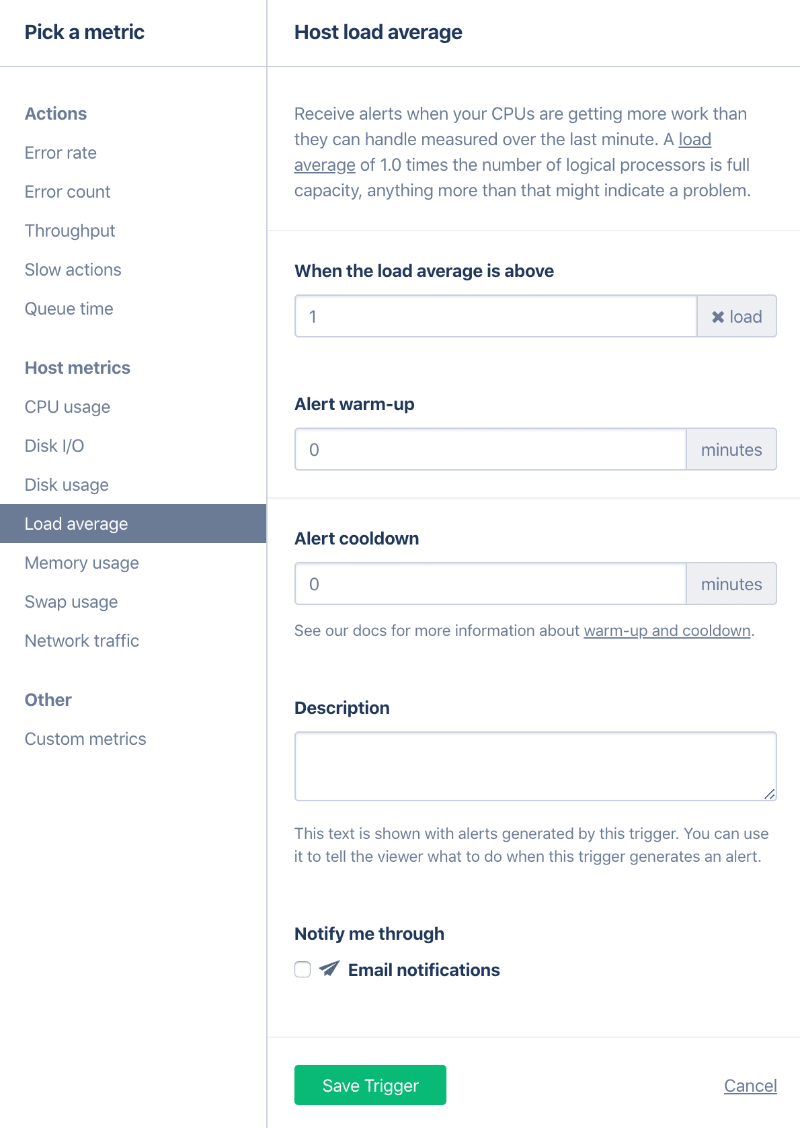
Step 2: Initial Triggers and Setting up Alerts
Now that we have the host metrics available, let's put in some thresholds for when you want to be alerted. The first step would be to set this up with a relatively sensitive or noisy alerting on a day (not a night) where you are available to look into things.
What a noisy setting is, depends on what you see on average on your hosts, but some sane defaults are:
| Metric | Trigger setting |
|---|---|
| CPU | idle over 100%, without warmup |
| Disk I/O | larger than 10MB per minute, without warmup |
| Disk usage | over 90% |
| Load average | over 1 |
When values go above these defaults, set up an alert via email or Slack (we don’t recommend starting with PagerDuty for these noisy alerts just yet).
Step 3: Monitoring the Patterns Over Time
Once you have some data coming in, the next step is to monitor the emerging patterns. Simply having all this data available is nice, but in our experience, it is all about the patterns.
There are some ‘right’s and ‘wrong’s but the key is to monitor, get to know the bandwidth in which your hosts operate in a ‘normal’ setting, and be able to see when things move beyond that bandwidth. In other words: it is not about having one data point, but about observing the line over a longer period of time.
Step 4: Ice Cold Drinks
Now that we have metrics coming in and we've set some triggers, we need to wait for some time before the patterns emerge.
Sit back and relax, alt-tab to another task or get an ice-cold drink; looking at the graphs all day won’t speed up the process. You may want to have the noisy settings running for a week to get a full pattern of weekdays and perhaps lower-traffic weekends.
Step 5: Monitoring Patterns Between Hosts
The next step, while we're drinking that ice-cold drink, is to compare the metrics over different hosts. Because the other important patterns in monitoring hosts, next to patterns over time, are about how one host behaves in comparison to another host with similar function.
This is why we show different hosts in one view like this:
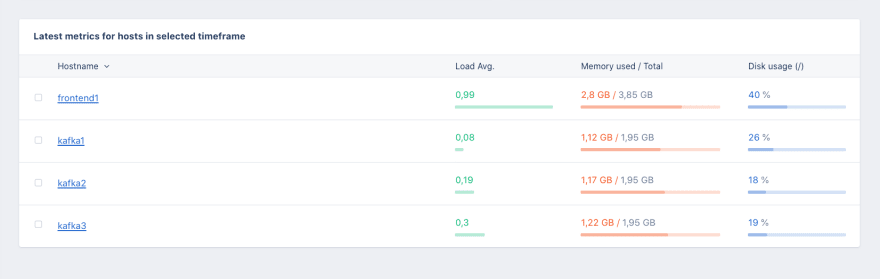
We’ve experienced that sometimes different hosts can have different performance characteristics, especially in a virtualized environment. For example, if you share the hardware with another customer of your hosting company, a change on their end might trigger issues on your side.
What Happens on the Hosts…
We could also call this ‘when the host issue is the effect, and not the cause’. So far, we've focused on steps to make sure we monitor and set triggers to the overall host-level metrics. But other than interference by other virtual machines, something like a CPU spike is the effect, not the cause of an issue (although it can trigger new problems).
This is why we built monitoring in an integrated way. We realize we are biased 😉 If you have your monitoring in one integrated way, like AppSignal or a comparable solution, you can also see what is running on a host that is causing those peaks.
At AppSignal, these metrics are scoped per namespace. By default, we create web and background namespaces for you, but you have complete freedom in how you organize your namespaces.
By setting your own namespaces, you can also set different levels of triggers. There might be webhooks where you can expect a much higher throughput. In a normal web request, you will want to set different triggers.
We get really excited about this part, so apologies if we dove in a bit too deep. We’ll cover it in a separate post in a few weeks. Let’s get back to the basics.
Step 6: Less Noise & Repeat
Once we’ve seen patterns emerge in time and between hosts, the next step is to set the alerting to some real levels that are not as noisy as the ones we started with. Once you’ve seen the spread of the mean, and you feel confident, hook up PagerDuty or OpsGenie and set up the real alerting that will wake people up.
Step 7: A Good Night’s Sleep
In our Ops team, the vision is ‘a good night’s sleep’. You should aim for that as well: being alerted when needed, and solving things so it doesn’t keep alerting you.
With all the steps taken, a good setup for monitoring your host will now get you some well-deserved sleep. Good night! (* depending on your timezone 😉)
PS: Another hard part about monitoring is digesting the hundreds of billions of requests that you may emit. We might write a blog post about that another day ;-) It's why we think you should use a dedicated service rather than run it yourself. And if you'd try us, we'd be honored.

Top comments (0)