
🔰 Beginners new to AWS CDK, please do look at my previous articles one by one in this series.
If in case missed my previous article, do find it with the below links.
🔁 Original previous post at 🔗 Dev Post
🔁 Reposted previous post at 🔗 dev to @aravindvcyber
In this article, let us refactor our previous step functions which were using S3-based storage to retrieve the JSON data for processing into a more performant dynamodb-based one. Both have their advantages compared to another one, so we have to choose them wisely based on the expected turnaround.
Visualizing this scenario with S3 ⛵

Visualizing this scenario with dynamodb 🚀
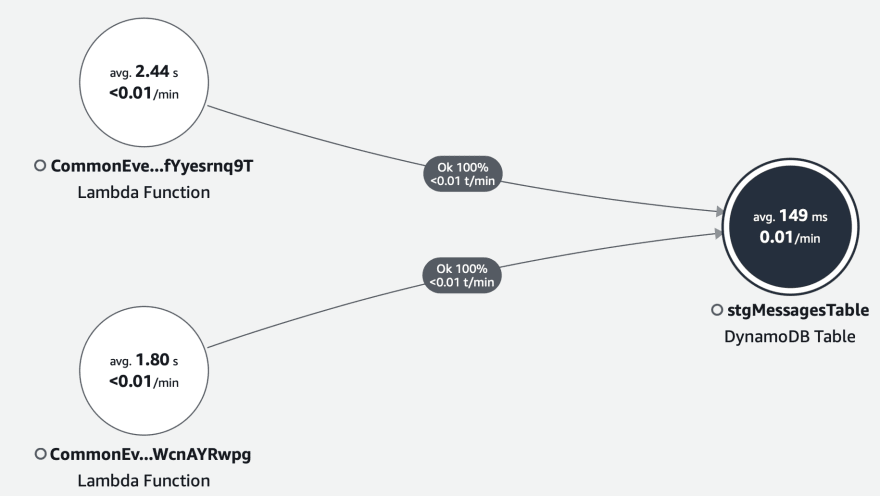
Benefits of fetching JSON from dynamodb vs S3 🏀
- In simple words, the first benefit of using dynamodb in place of S3 is a reduction in time taken for the I/O operation.
- S3 takes more time than the similar dynamodb operation.
- Though dynamodb is costlier compared to the s3 storage, when we use have a good archival setup this can be taken to our advantage.
- Further S3 operation is an external request which has overhead like DNS lookup and httpAgent creation.
- While dynamodb is treated as a database transaction and is faster.
- Moreover you can move your S3 metadata into fields in dynamodb for easier manipulation.
- This will also help with an opportunity to query and extract only the required field in each step of processing without downloading the full object contents as in S3.
- Also S3 will have better throughput when we have more prefixes, which can change the key path. Whereas in dynamodb we have good leverage over the throughput by making use of the provisioned and pay per request model.
- We can also fine-tune our read and write capacity based on the requests which could be throttled for efficient cost management and reliability with full control of the reservation.
- And by the way why we wanted to reduce the I/O time, this is because we always trigger this from a compute resource which is capacity and runtime metered, which will be waiting for longer idle.
- Data is dynamodb, can we efficiently archive like S3 with various service integration, besides the special TTL property we have with dynamodb, which can be used to delete the temporary objects like in our case.
Final results from analysis 🏭
I tried to trace this using x-ray and newrelic traces and find the below observations.
And do understand there could be some difference since both the traces from x-ray and newrelic track the timings differently.
Yet the point to note here would be that both convey that S3 could be a bit slower compared to dynamodb when we have high throughput transactions without any fine-tuning in the resource specifications.
Some trace results from xray for putObject ⛲

In-depth trace from newrelic for putItem 🎠

Some trace results from xray for getObject ⛵
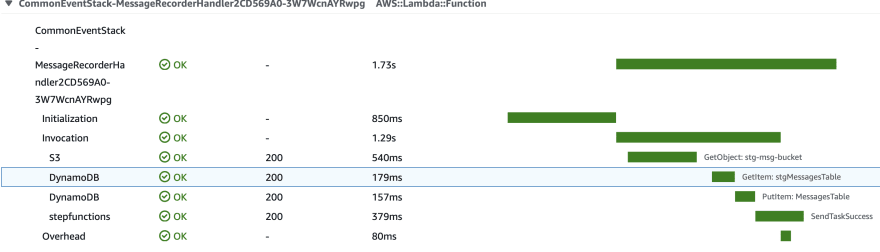
In-depth trace from newrelic for getItem ⛺

Construction 🚢
Here let us start by creating a new table as shown below in our main stack.
const stgMessages = new dynamodb.Table(this, "stgMessagesTable", {
tableName: process.env.stgMessagesTable,
sortKey: { name: "createdAt", type: dynamodb.AttributeType.NUMBER },
partitionKey: { name: "messageId", type: dynamodb.AttributeType.STRING },
encryption: dynamodb.TableEncryption.AWS_MANAGED,
readCapacity: 5,
writeCapacity: 5,
});
And grant access to both the entry handler and the backend step-function indirectly invoked handler.
stgMessages.grantWriteData(eventCounterBus.handler);
stgMessages.grantReadData(messageRecorder);
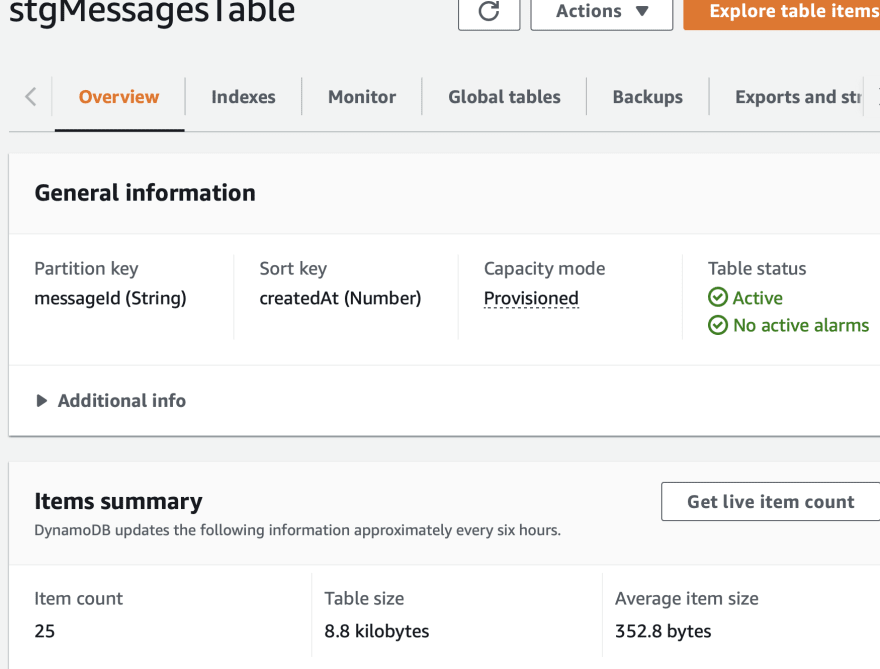
Refactoring the message entry handler 🎪
The existing message entry handler previously used to save to S3 will be now enhanced as shown below.
Helper function putItem
const dbPut: any = async (msg: any) => {
const dynamo = new DynamoDB();
const crt_time: number = new Date(msg.Metadata?.timestamp).getTime();
const putData: PutItemInput = {
TableName: process.env.STAGING_MESSAGES_TABLE_NAME || "",
Item: {
messageId: { S: msg.Metadata?.UUID },
createdAt: { N: `${crt_time}` },
content: { S: JSON.stringify(msg) },
},
ReturnConsumedCapacity: "TOTAL",
};
await dynamo.putItem(putData).promise();
};
Appending putItem once after putObject 🔱
Adding this as an additional set in the save helper function, so that we can use this as our successive step. This will help us understand the I/O timing information as we have demonstrated above.
const save = async (uploadParams: PutObjectRequest) => {
let putResult: PromiseResult<PutObjectOutput, AWSError> | undefined =
undefined;
let putDBResult: PromiseResult<PutObjectOutput, AWSError> | undefined =
undefined;
try {
putResult = await s3.putObject(uploadParams).promise();
putDBResult = await dbPut(uploadParams);
} catch (e) {
console.log(e);
} finally {
console.log(putResult);
console.log(putDBResult);
}
return putResult;
};
Creating additional properties in the JSON 🚥
In this step, we will add additional data into the JSON which will can help us in retrieving from the dynamodb.
message.uuid = getUuid();
message.handler = context.awsRequestId;
message.key = `uploads/${message.uuid}.json`;
message.bucket = process.env.BucketName || "";
message.table = process.env.STAGING_MESSAGES_TABLE_NAME || "";
message.timestamp = new Date().toUTCString();
Changes to step-function payload 🚀
The existing payload for the step function will now be enhanced with more property data as follows to extract the additional message coming from the event bridge detail post JSON parsing.
const sfnTaskPayload = sfn.TaskInput.fromObject({
MyTaskToken: sfn.JsonPath.taskToken,
Record: {
"messageId.$": "$.detail.message.uuid",
"createdAt.$": "$.detail.message.timestamp",
"bucket.$": "$.detail.message.bucket",
"key.$": "$.detail.message.key",
"table.$": "$.detail.message.table",
"uuid.$": "$.detail.message.uuid",
"timestamp.$": "$.detail.message.timestamp"
},
});
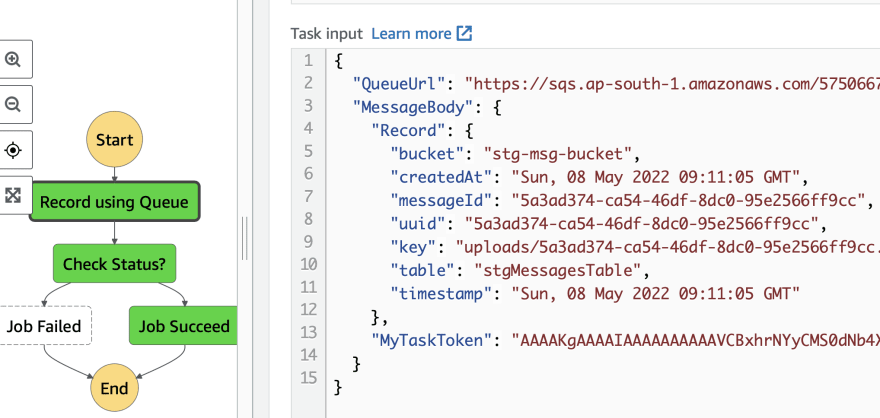
Refactoring the message recorder handler 🎁
Once retrieving the data from S3 from the previous article from inside the message recorder function, let us now add the new step to fetch directly from dynamo ignoring the getObject as follows.
Once the s3Get call is completed, we have used the dbGet which will is mentioned in the trace shown above.
try {
const crt_time: number = new Date(msg.timestamp).getTime();
const getData: GetItemInput = {
TableName: msg.table,
Key: {
messageId: { S: msg.uuid },
createdAt: { N: `${crt_time}` },
},
ProjectionExpression: "messageId, createdAt, content",
ConsistentRead: true,
ReturnConsumedCapacity: "TOTAL",
};
const dbGet = await dynamo.getItem(getData).promise();
data = JSON.parse(dbGet.Item.content.S).Body;
//OLD code with S3
if (data) {
msg.event = data;
const token = JSON.parse(Record.body).MyTaskToken;
await dbPut(msg)
.then(async (data: any) => {
await funcSuccess(data, msg.messageId, token);
})
.catch(async (err: any) => {
await funcFailure(err, msg.messageId, token);
});
}
} catch (err) {
console.log(err);
}

Thus we can add a new step to record to dynamodb and fetch from dynamo and performance our timing checks.
In the next article, we will completely ignore the direct S3 operations which are not used here and do that indirectly.
We will be adding more connections to our stack and making it more usable in the upcoming articles by creating new constructs, so do consider following and subscribing to my newsletter.
⏭ We have our next article in serverless, do check out
🎉 Thanks for supporting! 🙏
Would be great if you like to ☕ Buy Me a Coffee, to help boost my efforts.


🔁 Original post at 🔗 Dev Post
🔁 Reposted at 🔗 dev to @aravindvcyber

Latest comments (0)