
The way from a cool POC (proof of concept), like a walk in monets garden, to a production-ready application for an RAG (Retrieval Augmented Generation) application with Amazon Bedrock and Amazon Kendra is paved with some work. Let`s get our hands dirty.
With streamlit and langchain, you can quickly build a cool POC. This two-part blog is about what comes after that.
See this AWS blog post here as an example of a POC. The github repo uses streamlit and langchain to build a POC.
The story
Let's assume you are an AWS architect in the “fancy GO knowledge company. You have shown the example above to the board, and they are excited.
Hugo, is the CEO and says:
"Well this is really cool stuff. We will really enhance the way we share knowledge in our company."
You know what comes next: the BUT.
"But, ... it will be used by many people, so it should scale really well. Can you do that?
You begin to remember a video you saw a while ago on youtube: The expert.
"And of cause, it should be fast, secure and cost-effective at the same time"
OK, you think 3 BUTs. I can handle that.
"I also might have a few ideas about some more features. To start with, give us the text snippets from the documents and page numbers also."
You begin to sweat. You look to your boss Gordon (the CIO), for help. He may have slightly misinterpreted your look and added some more wishes: "And it should be serverless and have fast development cycles. And it should be easy to maintain."
Time to think
You remember what the expert in the video said: "I can do anything, I can do absolutely anything." and start.
The POC architecture

The new requirements are:
0) Make the server available as a web app
1) Scale fast
2) Secure
3) cost-effective
4) features page numbers, excerpts
5) serverless (this is not really a requirement, but a solution architecture hint)
6) easy to maintain
7) fast development cycles
Solution architecture
0) Make the server available as a web app
You decide to deploy the streamlit server as a fargate container. You use AWS CDK ApplicationLoadBalancedFargateService as a fast way to deploy a web server.
Containerization of the application is relatively easy. Here is the dockerfile:
`
FROM --platform=linux/amd64 python:3.11-slim
WORKDIR /app
RUN apt-get update && apt-get install -y \
build-essential \
&& rm -rf /var/lib/apt/lists/*
COPY streamlit/ streamlit/
WORKDIR /app/streamlit
RUN pip install --no-cache-dir -r requirements.txt
EXPOSE 8501
HEALTHCHECK CMD curl --fail http://localhost:8501/_stcore/health
ENTRYPOINT ["streamlit", "run", "app.py", "openai", "--server.port=8501", "--server.address=0.0.0.0"]
`
However, the monolithic architecture needs to scale better. So, you decide to split the application into two parts: the frontend and the backend.
The frontend can run streamlit now, but it could be changed afterwards. To have a clean separation, the backend is an API Gateway with a Lambda function.
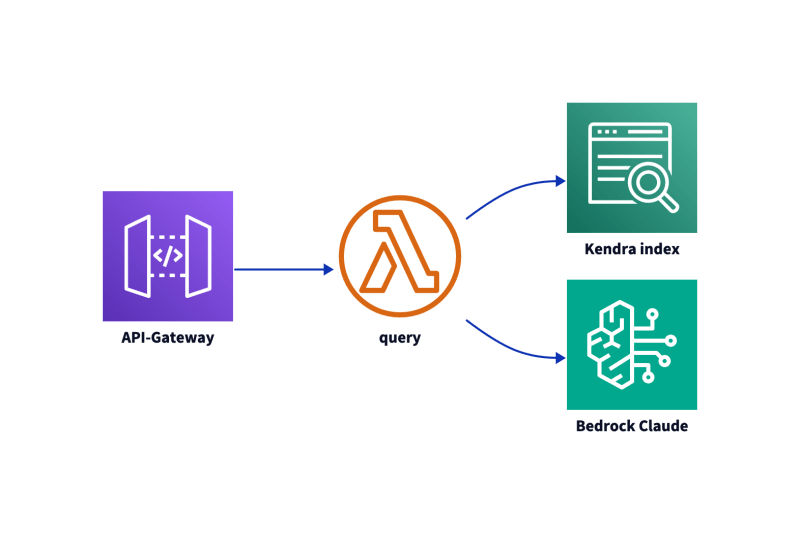
1) Scale fast
With AWS Lambda now scaling 12 times faster, this part is covered. You are aware of the bedrock runtime scaling limits but you decide to deal with that later. Maybe with the throttling feature of API Gateway. You think of a SQS to decouple, but decide against premature optimization, because it is the root of all evil.
2) Secure
You know that with lambda you have checked many boxes of an AWS Well-Architected Framework.
A short commercial break:
You decide to do an Well Architected Review with tecRacer later.
The API gateway will run in a private subnet, and the lambda function will have no internet access. To secure development, you use API Keys.
3) cost effective
Lambda is a good choice to run unpredicted workloads. After reading a comparism about the storage requirements of Python vs GO in the article Stop LLM/GenAI hallucination fast: Serverless Kendra RAG with GO
, you decide to try GO as Lambda development language. This step will reduce storage and Lambda execution costs, especially cold starts.
4) features page numbers, excerpts
To analyse the POC, you look at the code of the langchain. In the langchain you look at the results given back from the Kendra query. They are created by site-packages/langchain/retrievers/kendra.py
json
{
"question": "my question",
"chat_history": [],
"answer": "some god answer",
"source_documents": [
{
"Document": "page_content= Document Title: ... Document Excerpt: ...",
"metadata": {
"source": "https: //s3.eu-west-1.amazonaws.com/a_bucket/a_document.pdf",
"title": "a title",
"excerpt": "...\n"
}
}
]
}
No page numbers are returned. You decide not to change the langchain, but to code the calls directly. For bedrock, you find many examples in Python, Javascript and GO, e.g. here.
As you have to recode the logic anyway, you decide the fastest language, GO. See comparism.
5) serverless (this is not really a requirement, but a solution architecture hint)
Yes.
6) easy to maintain
The Lambda constructs implementations are good, but you decide to give AWS SAM a try. As it is focused on Serverless, it is less complex than AWS CDK. That means it is easier to learn and maintain.
The monolithic architecture will be split into two parts in the solution architecture: frontend and backend. This decoupled solution architecture is also easier to maintain.
7) fast development cycles
Frontend
The deployment of the Streamlit server as fargate container with CDK takes a few minutes. As you can fully develop the streamlit application locally, this is not a problem. You develop and do integration tests locally.
You can change the app.py code and with a refresh of the browser see the changes.
Backend
AWS Hero Yan Cui has pointed out in "Test Honeycomb", that with serverless environments, you should focus on integration tests. Although this is a ongoing discussion, you decide to focus on integration tests.
That means you must deploy the lambda function to AWS to test it. Because you test hundreds of times a day, you need a fast deployment.
The great thing is that you do not have to implement this yourself, as described in sub seconds deployment.
You give the new AWS SAM feature sync a try. So you may do a full deployment with sam deploy if resources change, or a fast `sync for code changes.
With sam sync --code --stack-name mystackname --watch code changes are deployed to AWS in a few seconds in the background.
So in the time it takes you to switch the programm from editor to postman, the code is deployed. So the question now is: Is "no time" fast enough?
On the terminal it looks like:
task sync
task: [sync] sam sync --code --stack-name godemo --watch
The SAM CLI will use the AWS Lambda, Amazon API Gateway, and AWS StepFunctions APIs to upload your code without
performing a CloudFormation deployment. This will cause drift in your CloudFormation stack.
**The sync command should only be used against a development stack**.
You have enabled the --code flag, which limits sam sync updates to code changes only. To do a complete infrastructure and code sync, remove the --code flag.
CodeTrigger not created as CodeUri or DefinitionUri is missing for RagAPIGateway.
Sync watch started.
Syncing Lambda Function RagFunction...
Cache is invalid, running build and copying resources for following functions (RagFunction)
Building codeuri: /Users/gglawe/letsbuild/git-megaproaktiv/go-rag-kendra-bedrock/lambda/query runtime: provided.al2 metadata: {'BuildMethod': 'makefile'} architecture: arm64 functions: RagFunction
RagFunction: Running CustomMakeBuilder:CopySource
RagFunction: Running CustomMakeBuilder:MakeBuild
RagFunction: Current Artifacts Directory : /Users/gglawe/letsbuild/git-megaproaktiv/go-rag-kendra-bedrock/.aws-sam/auto-dependency-layer/RagFunction
env GOOS=linux GOARCH=arm64 CGO_ENABLED=0 go build -tags lambda.norpc -ldflags="-s -w" -o bootstrap
cp ./bootstrap /Users/gglawe/letsbuild/git-megaproaktiv/go-rag-kendra-bedrock/.aws-sam/auto-dependency-layer/RagFunction/.
cp ./prompt.tmpl /Users/gglawe/letsbuild/git-megaproaktiv/go-rag-kendra-bedrock/.aws-sam/auto-dependency-layer/RagFunction/.
Missing physical resource. Infra sync will be started.
You have enabled the --code flag, which limits sam sync updates to code changes only. To do a complete infrastructure and code sync, remove the --code flag.
SAM calles the Makefile in the lambda directory. It takes less than a second to build the bootstrap file. You decide to go with this architecture concept. In Part 2 I will talk about how to implement it.
Conclusion
You are happy with your architecture. You start to implement it. - This is the cliffhanger for part 2.

Disclaimer
The characters in this post are fictitious. Any resemblance to persons living or dead is purely coincidental.
What I have learned
In the last half year, my focus was on Generative AI and the RAG approach. It is a great way to enhance knowledge base access for larger companies or compleyx topics.
This story shall entertain you and give you some ideas how to implement a RAG architecture and to think outside the "its all python/langchain" box. For your project it could also be JavaScript, but as you have seen, GO has some advantages too.
Second part
The backend implementation will be covered in the second part of this blog post. All source code will be available on github and with some basic AWS knowledge you are ready to try it out yourself in minutes.
Enjoy building!
If you need developers and consulting for your next GenAI project, don't hesitate to contact the sponsor of this blog, tecRacer.
For more AWS development stuff, follow me on dev https://dev.to/megaproaktiv.
Want to learn GO on AWS? GO here

Top comments (0)