
I spent over a couple of weeks reading about data, big data, database, Relational database, Non-Relational database, Amazon Relational Database Service (RDS), Amazon Dynamo Database. I have started by explaining what do you mean by data and big data.
What do you mean by data?
Data is raw information. For example, your daily consumption of coffee. It is raw information about the amount of coffee you have consumed, but if you analyze it and gain insights from it.
- The brand of coffee you drink
- At what time do you prefer to drink coffee
- How much sugar do you put into the coffee

What do you mean by Big Data?
Big data can be described in terms of data management challenges that due to increasing volume, velocity and variety of data cannot be solved with traditional databases.
Some have defined big data as an amount of data that exceeds a petabyte one million gigabytes.
While there are plenty of definitions for big data, most of them include the concept of what’s commonly known as “four V’s” of big data,
- Volume: Volumes of data that can reach unprecedented heights in fact. The challenge with data volume is not so much storage as it is how to identify relevant data within gigantic data sets and make good use of it.
- Velocity: Some data will come in in real-time, whereas other will come in fits and starts, sent to us in batches. The challenge for data scientists is to find ways to collect, process, and make use of huge amounts of data as it comes in.
-
Variety: Data comes in different forms.
- Structured data is that which can be organized neatly within the columns of a database. This type of data is relatively easy to enter, store, query, and analyze.
- Unstructured data is more difficult to sort and extract value from. Examples of unstructured data include emails, social media posts, word-processing documents; audio, video and photo files; web pages, and more.
- Veracity: Quality of the collected data. If source data is not correct, analyses will be worthless.

For more information on Big Data,
What do you mean by a database?
A database is any type of mechanism used for storing, managing, and retrieving information. It is a repository or collection of data.
A database’s implementation and how data is structured will determine how well an application will perform as it scales. There are two primary types of databases, relational and non-relational.
- Relational databases(SQL databases): they use the Structured Query Language to manage information storage and retrieval.
- Non-relational databases(NoSQL databases): NoSQL databases are often distributed databases where data is stored on multiple computers or nodes.

Each database type is optimized to support a specific type of workload. Matching an application with the appropriate database type is essential for highly performant and cost-efficient operation.
While it is possible to make a general-purpose database manage just about any type of workload, it will not scale as demand increases. The reasons this is important are,
- The cloud has the promise of agility. That is, being able to respond to changes in a business environment as they happen. This includes the ability to grow as needed and it’s called scalability.
- It is done by partitioning tables, indexes into smaller pieces in order to manage and access the data at finer level.
- Another promise of the cloud is elasticity. That is, it’s great to be able to scale up to meet demand but, elasticity allows for the opposite to happen. When demand decreases, so does the scale and its related expenses. Who wants to pay for idle resources?

It’s important for application developers to examine the data and consider its size, shape, and computational requirements for processing and analysis. These three things determine what type of database is needed for a particular application to allow for scalability and elasticity.
The two primary workload types are operational and analytical,
- Online Transactional Processing applications (OLTP): A transaction is a record of an exchange. OLTP is centered around a set of common business processes that is regular, repeatable, and durable.
- OLTP, are usually powered by relational databases. The data is highly structured, controlled, and predictable.
- Online Analytics Processing applications (OLAP) are run as needed for things like business intelligence workloads and data analysis.
- The goal is to gain insight. Workloads are often Retrospective, Streaming, and Predictive.
- OLAP, are often powered on the backend using non-relational databases. The workloads are unpredictable, and the output is used to answer questions about the unknown.
Relational Database:
They provide an efficient, intuitive, and flexible way to store and report on highly-structured data. These structures, called schemas, are defined before any data can be entered into the database.
Once a schema has been defined, database administrators and programmers work backward from these requirements to define how data will be stored inside the database. Schema changes to existing databases are expensive in terms of time and compute power. It also has a risk of corrupting data and breaking existing reports.

Data integrity is of particular concern in a relational database, there are a number of constraints that ensure the data contained in tables is reliable and accurate. These reliability features commonly referred to as ACID transactions,
- Atomicity refers to the elements that make up a single database transaction. A transaction could have multiple parts. It is treated as a single unit that either succeeds completely or fails completely.
- Consistency refers to the database’s state. Transactions must take the database from one valid state to another valid state.
- Isolation prevents one transaction from interfering with another.
- Durability ensures that data changes become permanent once the transaction is committed to the database.
Data in a relational database must be kept in a known and stable state.
Relational database engines have built-in features for securing and protecting data but planning and effort are required to properly implement them. These features include user authentication, authorization, and audit logging.
As part of the structure, data stored in relational databases is highly normalized. Normalization is a process where information is organized efficiently and consistently before storing it.

Relational databases are not partition tolerant. A data partition, in this case, refers to the disk. Adding another disk would be like creating a second copy of the database. Because of this complexity, most of the time relational databases are scaled vertically.
1.Amazon Relational Database Service (RDS):
It is a relational database service that provides a simple way to provision, create, and scale a relational database within AWS.
It's a managed service, which takes many of the mundane administrative operations out of your hands, and it's instead managed by AWS, such as backups and the patching of both the underlying operating system in addition to the database engine software that you select.
Amazon RDS allows you to select from a range of different database engines.
- MySQL: considered the number one open source relational database management system.
- MariaDB: community-developed fork of MySQL.
- PostgreSQL: the preferred open source database.
- Amazon Aurora is AWS's own fork of MySQL, which provides ultrafast processing and availability, as it has its own cloud-native database engine.
- The Oracle database is a common platform in corporate environments.
- SQL Server, it is a Microsoft database with a number of different licensing options.

In addition to so many different database engines, you also have a wide choice when it comes to selecting which compute instance you'd like to run your database on.
You can deploy your RDS instance in a single availability zone. However, if high availability and resiliency is of importance when it comes to your database, then you might want to consider a feature known as Multi AZ. When Multi AZ is configured, a secondary RDS instance is deployed within a different availability zone within the same region as the primary instance.

When it comes to scaling your storage, you can use a feature called storage autoscaling.
- MySQL, PostgreSQL, MariaDB, Oracle, and SQL Server all use Elastic Block Store, EBS volumes, for both data and log storage.
- The database engines that use EBS support general purpose SSD storage, provisioned IOPS SSD storage, and magnetic storage.
- Amazon Aurora uses a shared cluster storage architecture and does not use EBS.
- Aurora doesn't use EBS and instead uses a shared cluster storage architecture which is managed by the service itself.
You can also perform manual backups anytime you need to, which are known as snapshots. Aurora database, you can also use a feature called backtrack, and this allows you to go back in time on the database to recover from an error or incident without having to perform a restore or create another database cluster.
Non Relational Database:
While relational databases are highly-structured repositories of information, non-relational databases do not use a fixed table structure. They are schema-less.
Since it doesn’t use a predefined schema that is enforced by a database engine, a non-relational database can use structured, semi-structured, and unstructured data without difficulty.

NoSQL databases are popular with developers because they do not require an upfront schema design; they are able to build code without waiting for a database to be designed and built.
NoSQL databases, in general, share a few basic characteristics.
- Most NoSQL databases access data using their own Application Programming Interface, API. However, some NoSQL databases use a subset of SQL for data management.
- Schemas can be created dynamically as data is accessed or embedded into the data itself.
- NoSQL databases have a reputation for being more flexible with the data they can accept and support agile and DevOps philosophies.
NoSQL databases are often run in clusters of computing nodes. Data is partitioned across multiple computers so that each computer can perform a specific task independently of the others. Each node performs its task without having to share CPU, memory, or storage with other nodes. This is known as a shared-nothing architecture.
Most NoSQL databases relax ACID constraints found in relational databases.
NoSQL solutions were developed around the purpose of providing high availability and scalability in a distributed environment. To do this, either consistency or durability has to be sacrificed according to CAP theorem.

By relaxing consistency, distributed systems can be highly available and durable. Using a NoSQL approach, inconsistent data is expected. There’s no problem as long as it’s recognized and managed appropriately. Currently, there is no standard query language that is supported by all NoSQL databases.
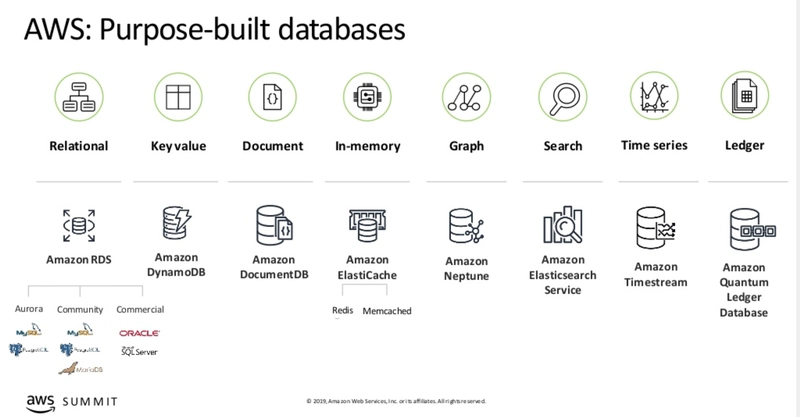
NoSQL databases are a family of non-relational databases that include
-
Key-Value databases are the simplest NoSQL data stores to use from an API perspective. Using a RESTful API, a client can get the value for the key, put a value for a key, or delete a key from the data store.
- They can be used for storing user session data or storing shopping cart data. Examples include Redis and Memcached.
-
Document Store Database is a database that uses a document-oriented model to store information. Each document contains semi-structured data that can be queried. Essentially, the schema for the data is built into the document, itself, and can change as needed.
- It's written in JavaScript Object Notation(JSON), what makes this different than a key-key value store is that, for some of the values, there are nested key-value pairs that can be indexed and retrieved.
- They can be used for E-commerce Platforms or Blogging platform data. Examples include Mongo DB.
-
Graph Store Graph databases store and analyze the relationships between things. Graph databases can visualize people in terms of a social network but they can also be used to see how systems and processes are connected.
- It has two primary components, Vertices(Nodes) and Edges(Relationship. Every vertice and edge has a unique identifier.
- They can be used for Network operation data or Social networking data. Examples include Amazon Neptune.
-
Column Data Stores is a database in which data is stored in cells grouped in columns of data rather than as rows of data. Columns are logically grouped into column families.
- They can be used for Content Management Systems or Blogging platform data. Examples include Apache Hadoop and Cassandra.
- ElastiCache is an in-memory store. The primary use case for an in-memory store is caching. A cache improves database performance by serving often requested data from memory instead of from a disk or from a memory-intensive calculation.
- Timestream is a Time Series database. Time series databases answer questions about trends and events. While it is a type of key-value store with the time as the key, a time series database looks at ranges of data points to calculate answers.
- Quantum Ledger Database is a ledger database. A ledger database uses cryptographic controls to ensure that the data stored is immutable. Records are not edited. Instead, when information changes, new versions of the record are created. It also uses a blockchain to ensure data integrity. When a hash is created to verify data integrity it uses the data along with the hash from the previous record. If the chain is tampered with, the chain will be broken.
- Elasicsearch Service is a search database. Search databases create indexes to help people find important information. Web searching is a common application but searching is also done in product catalogs, enterprise documentation, and in content management systems.
Scaling a NoSQL database is easier and less expensive than scaling a relational database because the scaling is horizontal instead of vertical. NoSQL databases generally trade consistency for performance and scalability.
With most NoSQL databases, it's possible for data to be inconsistent; a query might return old or stale data. You might hear this phenomenon described as being eventually consistent. Over time, data that is spread across storage nodes will replicate and become consistent. What makes this behavior acceptable is that developers can anticipate this eventual consistency and allow for it.

1.Amazon Dynamo DB:
Amazon DynamoDB is a NoSQL database, which means that it doesn't use the common Structured Query Language, SQL. It falls into a category of databases known as key-value stores.
- Amazon DynamoDB is designed to be used for ultra high performance, which could be maintained at any scale with single-digit latency.
- DynamoDB is also a fully managed service, taking many of the day-to-day administration operations out of your hands, giving you more time to focus on the business logic of your database.
- The creation of a DynamoDB database is very easy. All you have to do is set up your tables and configure the level of provision throughput that each table should have.
- You are charged for the total amount of throughput that you configure for your tables plus the total amount of storage space used by your data.
In its simplest form, you can just provide a table name and a primary key, which is used to partition data across hosts for scalability and availability. You can then accept any remaining defaults and create your database, it's as simple as that.
https://awscomputeblogimages.s3-us-west-2.amazonaws.com/IoTBackend_Picture2.png
The default option provides no secondary index. However, you can add them here if required. DynamoDB lets you create additional indexes so that you can run queries to search your data by other attributes. If you've worked with relational databases, you've probably used indexes with those, but there are a couple of big differences in how indexes operate in DynamoDB.
- Each query can only use one index. If you want to query and match on two different columns, you need to create an index that can do that properly.
- When you write your queries, you need to specify exactly which index should be used for each query. It's not like a relational database that has a query analyzer, which can decide which indexes to use for our query.
DynamoDB has two different kinds of secondary indexes,
- global indexes let you query across the entire table to find any record that matches a particular value
- local secondary indexes can only help find data within a single partition key.
When you create a table in DynamoDB, you need to tell AWS how much capacity you want to reserve for the table. You don't need to do this for disk space as DynamoDB will automatically allocate more space for your table as it grows. However, you do need to reserve capacity for input and output for reads and writes. Amazon charges you based on the number of read capacity units and write capacity units that you allocate.

By default, when you create a table in the AWS Console, Amazon will configure your table with five read capacity units and five write capacity units. There are two modes that you can choose from, provisioned and on-demand.
- Provisioned mode allows you to provision set read and writes allowed against your database per second by your application and is measured in capacity units, RCUs for reads and WCUs for writes. Depending on the transaction, each action will use one or more RCUs or WCUs. Provisioned mode is used generally when you have a predicted and forecasted workload of traffic.
- On-demand mode does not provision any RCUs or WCUs, instead they are scaled on demand. The downside is that it is not as cost effective as provisioned. This mode is generally used if you do not know how much workload you are expected to experience. Over time, you are likely to get more of an understanding of load and you can change your mode across to provisioned.
Through the use of the key management service, KMS, you are able to select either a customer managed or AWS managed CMK to use for the encryption of your table instead of the default keys used by DynamoDB.
Some of the advantages of DynamoDB
- It's fully managed by AWS, you don't have to worry about backups or redundancy.
- DynamoDB tables are schema less so you don't have to define the exact data model in advance.
- DynamoDB is designed to be highly available and your data is automatically replicated across three different availability zones within a geographic region.
- DynamoDB is designed to be fast, read and writes take just a few milliseconds to complete and DynamoDB will be fast no matter how large your table grows, unlike relational database, which can slow down as the table gets large.
Downsides to using DynamoDB too.
- Your data is automatically replicated. Three copies are stored in three different availability zones and that replication usually happens quickly in milliseconds, but sometimes it can take longer and this is known as eventual consistency. This happens transparently and many operations will make sure that they're always working on the latest copy of your data, but there are certain kinds of queries and table scans that may return older versions of data before the most recent copy.
- DynamoDB's queries aren't as flexible as what you can do with SQL. If you are used to writing advanced queries with joins and groupings and summaries, you won't be able to do that with DynamoDB. You'll have to do more of the computation in your application code.
- Although DynamoDB performance can scale up as your needs grow, your performance is limited to the amount of read and write throughput that you've provisioned for each table. If you expect a spike of the database use, you'll need to provision more throughput in advance or database requests will fail you can adjust throughput at any time and it only takes a couple of minutes to adjust.

Let me know where i could improve at?

Top comments (0)