Blog written by: Suchi Amalapurapu & Ronak Kothari from Bloomreach, 2015
Introduction
We use Solr to power Bloomreach’s multi-tenant search infrastructure. The multi-tenant search solution caters to diverse requirements/features for tenants belonging to different verticals like apparel, office supplies, flowers & gifts, toys, furniture, housewares, home furnishings, sporting goods, health & beauty. Bloomreach’s search platform provides high-quality search results with a merchandising service that supports a number of different configurations. Hence the need for a number of search features which are implemented as distributed Solr components in SolrCloud.
This blog goes over how Solr distributed requests work and includes an illustration of a custom autocorrect component design and discusses the various design considerations for implementing distributed search features.
Lifecycle of a Solr search query
Search requests in Solr are served via the SearchHandler, which internally invokes a set of callbacks as defined by SearchComponent. These components can be chained to create custom search functionality without actually defining new handlers. A typical search application uses several search components implementing custom search features in each component. Some sample examples are QueryComponent, FacetComponent, MoreLikeThis, Highlighting, Statistics, Debug, QueryElevation.
The lifecycle of a typical search query in Solr is as follows:

Request Flow
This section goes over the execution flow of requests in SearchHandler and how the callbacks are invoked for SearchComponent. Solr requests are of two types — single shard (non-distributed mode) and multi-shard (distributed mode).
Non-distributed or single shard mode
Architecture
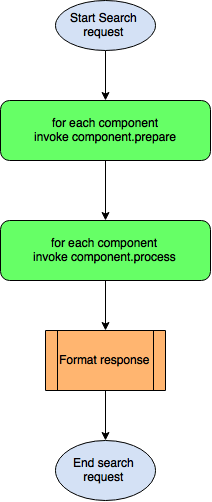
In Solr’s non-distributed mode (or single shard mode), the index data needed to serve a search request resides on a single shard. The following diagram describes the request flow for this scenario:
Implementation details
SearchHandler invokes each search component’s prepare methods in a loop followed by each component’s process methods. Components can work on the response of components invoked before itself.
Example – Autocorrect
Let’s consider the autocorrect feature wherein, the user query is spell-corrected when the query does not have any search results in the index. For example, user query “sheos” is autocorrected to “shoes”, since there are no search results for “sheos”.
This feature needs three components QueryComponent, SpellcheckComponent and AutocorrectComponent. QueryComponent is used for default search. If the user-defined query does not return any results from the index, SpellcheckComponent adds a spellcheck suggestion. AutocorrectComponent further uses the spellchecked query to return search results. If the user-defined query is spelled correctly, AutocorrectComponent does not modify the response. In this case, SpellcheckComponent and AutocorrectComponent are added as last components. The following are the key steps involved:
- A search request, response builder objects are created in SolrDispatcher.
- A distributed search request is initiated for query “sheos.”
- QueryComponent returns 0 numResults for the query.
- SpellcheckComponent, which gets invoked after QueryComponent, adds a spell-corrected suggestion, “shoes.”
- Based on numResults being 0 and SpellcheckComponent’s suggestion, AutocorrectComponent reissues the search request with corrected query “shoes”
- Response formatting.
Distributed or multi-shard mode
Architecture
A request is considered distributed (or multi-shard) when the index of a collection is partitioned into multiple sub-indexes called shards. The request could hit any node in the cluster. This node needn’t necessarily have data for the intended search request. The node that received the request executes the distributed request in multiple stages and on different shards that contain the actual index. The responses from each of these shards is further merged to get the final response for the query.
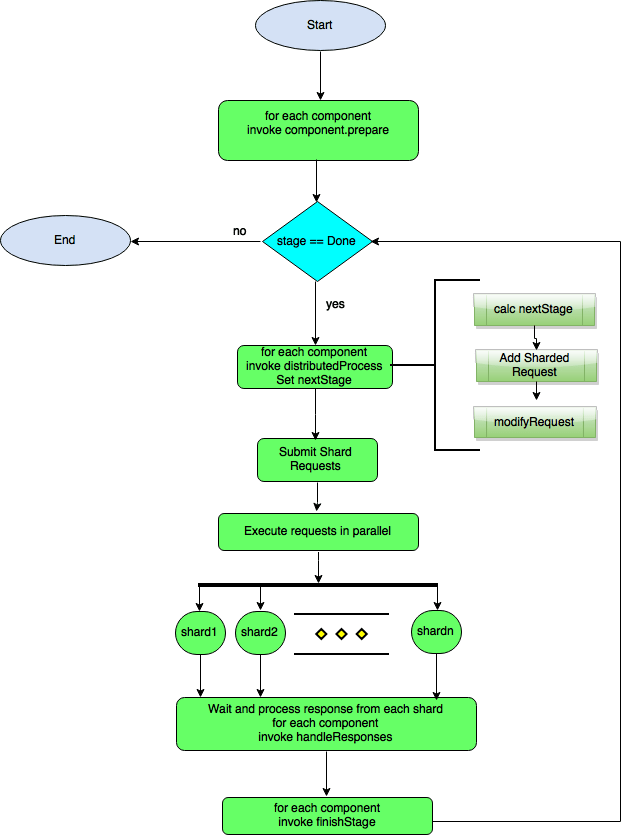
SearchComponent callbacks for a distributed search request differ from its non-distributed counterpart. A search request gets executed by the SearchHandler, which is distributed aware. The callback distributedProcess is used to determine the search component’s next stage across all search components. Search components have the ability to influence the next stage of a distributed request via this callback. Search components can spawn more requests in each stage and all these requests get added to a pending queue. Eventually non-distributed requests get spawned for each of these pending distributed requests, which in turn get executed on each shard. These responses are collated in handleResponses callback. Any post processing work can be further done in finishStage. Please refer to WritingDistributedSearchComponents for a detailed understanding of how distributed requests work.
The life cycle of a distributed Solr search request can be depicted as follows:
Example – Autocorrect
Let’s consider the functionality of autocorrect in distributed mode. The difference from its non-distributed counterpart is that the spell-corrected response could come from any shard and might not necessarily be present on each shard. So the autocorrect component that we had defined earlier has to process SpellcheckComponent’s response only after letting it collate the responses from all shards. (SpellcheckComponent in Solr is already distributed aware.)
Please note that this can be better achieved as two search requests instead of a single complicated request. However, the hypothetical implementation in this section illustrates a custom distributed autocorrect component.
The new autocorrect component has to be defined after the SpellcheckComponent in the list of search components defined in solrconfig.xml. This is to facilitate stage modification of the request by processing the response of SpellcheckComponent.
Implementation details
A new stage called STAGE_AUTOCORRECT is added right after STAGE_GET_FIELDS. This functionality goes in distributedProcess of AutocorrectComponent, which checks if the number of results for the given query are 0 and if SpellcheckComponent provides a suggestion for a corrected query. Autocorrect component modifies the request query to the spell suggestion and resets the stage to STAGE_START.
The new search request is then executed as a distributed search request. A couple of flags have to be used to avoid getting stuck in an infinite loop here, since we are actually resetting the stage. These steps can be listed as:
- A search request, response builder objects are created in SolrDispatcher.
- A distributed search request is initiated for query “sheos” on any node in the cluster with STAGE_START.
- The request goes smoothly till STAGE_GET_FIELDS, where the next stage is set to STAGE_AUTOCORRECT.
- STAGE_AUTOCORRECT is where the numResults condition and SpellcheckComponent suggestion is checked. If the query needs to be autocorrected, a new user query is set on the request and the stage set back to STAGE_START. Set an additional flag on the response to skip this stage next time.
- Search request goes through all the stages again with the spell-checked query.
- Response formatting.
Learnings
There are several key takeaways from our experiences with scaling distributed search features in Solr. These can be summarized as:
System Memory and resources
- Any additional search requests created in custom search components should be closed explicitly to avoid leaking resources. Otherwise, this could cause subtle memory leaks in the system. Many search features that we authored had to be tested thoroughly to avoid performance overheads.
- Solr components that load additional data in the form of external data will either need core reloads or ability to be updated via request handlers. Such components should avoid using locks to avoid performance issues when serving requests.
- The throughput of a multi-sharded Solr cluster is usually lower than a non-sharded one (depending on factors like number of shards and stages of a query).
Design practices
- Its better to split a complicated search request into multiple requests, rather than adding too many stages in the same request — more so in a multi-tenant architecture, where we can mix and match features, based on customer requirements via request-based params or collection-specific default settings.
- In some cases, moving this functionality out of Solr simplified the component design.
- One more caveat that we realized: The single shard collections hosted on SolrCloud do not follow the distributed request life cycle and instead use the non-distributed callbacks. So in general, Solr components should be designed to work in both modes, so that resharding or merging shards has no effect on search functionality later on.
Conclusion
Solr exposes interfaces to allow users to customize search components. Both the handlers, as well as search components, can be extended for custom functionality. However these components have to be carefully designed in a multi-shard mode to capture the intended functionality. Thorough testing and monitoring for a sustained period of time to detect any subtle leaks or performance degradation is essential in such production systems.
References
http://wiki.apache.org/solr/WritingDistributedSearchComponents
https://wiki.apache.org/solr/SolrCloud
https://wiki.apache.org/solr/SearchComponent
http://lifelongprogrammer.blogspot.in/2013/05/solr-refcounted-dont-forget-to-close.html

Top comments (0)