Blog written by: Nitin Sharma & Li Ding from Bloomreach, 2015
Introduction
Scaling a multi-tenant search platform that has high availability while maintaining low latency is a hard problem to solve. It’s especially hard when the platform is running a heterogeneous workload on hundreds of millions of documents and hundreds of collections in SolrCloud.
Typically search platforms have a shared cluster setup. It does not scale out of the box for heterogenous use cases. A few of the shortcomings are listed below.
- Uneven workload distribution causing noisy neighbor problem. One search pipeline affects another pipeline’s performance. (especially if they are running against the same Solr collection).
- Impossible to tune Solr cache for the same collection for different query patterns.
- Commit Frequency varies across indexing jobs causing unpredictable write load in the SolrCloud cluster.
- Bad clients leaking connections that could potentially bring down the cluster.
- Provisioning for the peak causes un-optimal resource utilization.
The key to solve these problems is isolation. We isolate the write and read of each the collections. At Bloomreach, we have implemented an Elastic Solr Infrastructure that dynamically grows/shrinks. It helps provide the right amount of isolation among pipelines while improving resource utilization.The SC2 API and HAFT services ( built in house) give us the ability to do the isolation and scale the platform in an elastic manner while guaranteeing high availability, low latency and low operational cost.
This blog describes our innovative solution in greater detail and how we scaled our infrastructure to be truly elastic and cost optimized. We plan to open source HAFT Service in the future for anyone who is interested in building their own highly available Solr search platform.
Problem Statement
Below is a diagram that describes our workload.

In this scheme, our production Solr cluster is the center for everything. As for the other elements:
- At the bottom, the public API is serving an average of 100 QPS (query per second).
- The blue boxes labeled indexing will commit index updates (full and partial indexing) to the system. Every indexing job represents a different customer’s data, which commit at different frequencies from everyday to every hour to every half hour.
- The red boxes labeled pipeline are jobs to run ranking and relevance queries. The pipelines represent various types of read/analytical workload issued against customer data. Two or more pipelines can run against the same collections at the same time, which increases the complexity.
With this kind of workload, we are facing several key challenges with each client we serve. The graph below illustrates some the challenges with this architecture:
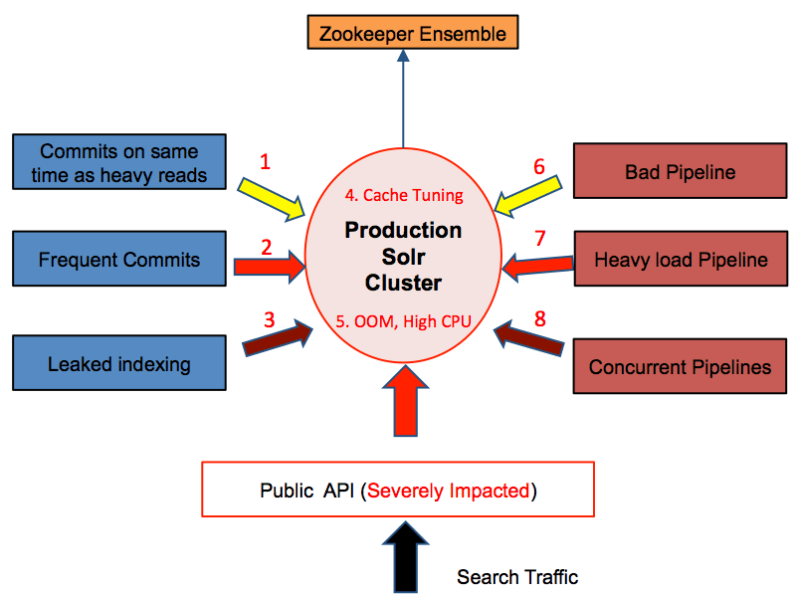
For indexing jobs:
- Commits at same time as heavy reads: Indexing jobs running at the same time as pipelines and customer queries, which impact both pipelines and the latency of customer queries.
- Frequent commits: Frequent commits and non-batched updates cause performance issues in Solr.
- Leaked indexing: Indexing jobs might fail resulting in leaked clients, which get accumulated over time.
For the pipeline jobs:
- Cache tuning: Impossible for Solr to tune the cache. The query pattern varies between pipeline jobs when working on the same collections.
- OOM and high CPU usage: Unevenly distributed workload among Solr hosts in the clusters. Some nodes might have OOM error while other nodes have high CPU usage.
- Bad pipeline: One bad client or query could bring down the performance of the entire cluster or make one node unresponsive.
- Heavy load pipeline: One heavy load pipeline would affect other smaller pipelines.
- Concurrent pipelines: The more concurrent pipeline jobs we ran, the more failures we saw.
Bloomreach Search Architecture
Left unchecked, these problems would eventually affect the availability and latency SLA with our customers. The key to solving these problems is isolation. Imagine if every pipeline and indexing job had its own Solr cluster, containing the collections they need, and every cluster was optimized for that job in terms of system, application and cache requirements. The production Solr cluster wouldn’t have any impact from those workloads. At Bloomreach, we designed and implemented a system we call Solr Compute Cloud (SC2) to isolate all the workload to scale the Solr search platform.
The architecture overview of SC2 is shown in the diagram below:
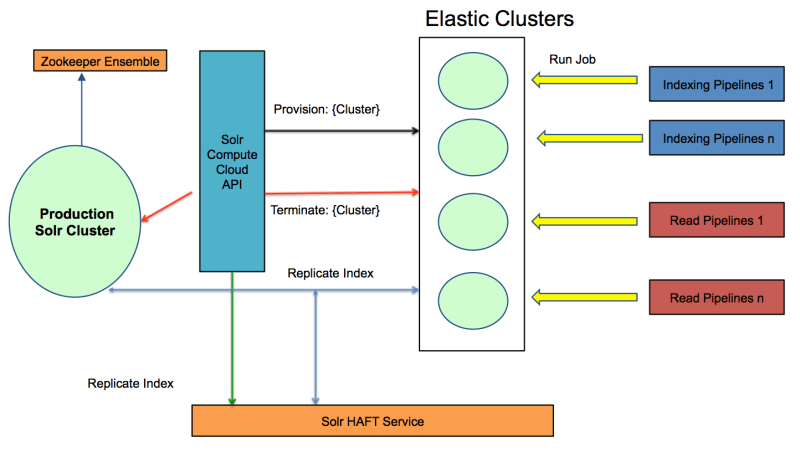
We have an elastic layer of clusters which is the primary source of data for large indexing and analysis MapReduce pipelines. This prevents direct access to production clusters from any pipelines. Only search queries from customers are allowed to access production clusters. The technologies behind elastic layer are SC2 API and Solr HAFT (High Availability and Fault Tolerance) Service (both built in-house).
SC2 API features include:
- Provisioning and dynamic resource allocation: Fulfill client requests by creating SC2 clusters using cost-optimized instances that match resources necessary for requested collections.
- Garbage collection: Will automatically terminate the SC2 clusters that exceed an allowed lifetime setting or idle for a certain amount of time.
- Pipeline and indexing job performance monitoring: Monitor the cost and performance of each running job.
- Reusability: Create an instance pool based on the request type to provision clusters faster. The API will also find an existing cluster based on the request data for read pipelines instead of provisioning a new cluster. Those clusters are at low utilization.
Solr HAFT Service provides several key features to support our SC2 infrastructure.
- Replace node: When one node is down in a Solr cluster, this feature automatically adds a new node to replace that node.
- Add replicas: Add extra replicas to existing collections if the query performance is getting worse.
- Repair collection: When a collection is down, this feature repairs the collection by deleting the existing collection. Then it re-creates and streams data from backup Solr clusters.
- Collection versioning: Config of each collection can be versioned and rolled back to previous known healthy config if a bad config was uploaded to Solr.
- Dynamic replica creation: Creates and streams data to a new collection based on the replica requirement of the new collection.
- Cluster clone: Automatically creates a new cluster based on existing serving cluster setup and streaming data from backup cluster.
- Cluster swap: Automatically switches Solr clusters so that the bad Solr cluster can be moved out of serving traffic and the good or newly cloned cluster can be moved in to serve traffic.
- Cluster state reconstruction: Reconstructs the state of newly cloned Solr cluster from existing serving cluster.
Read Workflow

We will describe the detailed steps of how read pipeline jobs work in SC2:
- Read pipeline requests collection and desired replicas from SC2 API.
- SC2 API provisions SC2 cluster dynamically with needed setup (and streams Solr data).
- SC2 calls HAFT service to request data replication.
- HAFT service replicate data from production to provisioned cluster.
- Pipeline uses this cluster to run job.
- After pipeline job finishes, call SC2 API to terminate the cluster.
Indexing Workflow
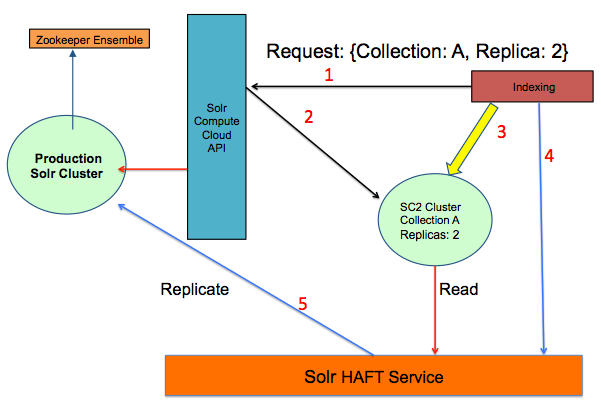
Below are detailed steps describing how an indexing job works in SC2.
- The indexing job uses SC2 API to create a SC2 cluster of collection A with two replicas.
- SC2 API provisions SC2 cluster dynamically with needed setup (and streams Solr data).
- Indexer uses this cluster to index the data.
- Indexer calls HAFT service to replicate the index from SC2 cluster to production.
- HAFT service reads data from dynamic cluster and replicates to production Solr.
After the job finishes, it will call SC2 API to terminate the SC2 cluster.
Solr/Lucene Revolution Talk 2014 at Washington, D.C.
We spoke in detail about the Elastic Infrastructure at Bloomreach in last year’s Solr Conference. The link to the video of the talk and the slides are below.
- Talk: https://www.youtube.com/watch?v=1sxBiXsW6BQ
- Slides: http://www.slideshare.net/nitinssn/solr-compute-cloud-an-elastic-solrcloud-infrastructure
Conclusion
Scaling a search platform with heterogeneous workload for hundreds of millions of documents and a massive number of collections in SolrCloud is nontrivial. A kitchen-sink shared cluster approach does not scale well and has a lot of shortcomings such as uneven workload distribution, sub-optimal cache tuning, unpredictable commit frequency and misbehaving clients leaking connections.
The key to solve these problems is isolation. Not only do we isolate the read and write jobs as a whole but also isolate write and read of each the collection. The in-house built SC2 API and HAFT services give us the ability to do the isolation and scale the platform in an elastic manner.
The SC2 infrastructure gives us high availability and low latency with low cost by isolating heterogeneous workloads from production clusters. We plan to open source HAFT Service in the future for anyone who is interested in building their own highly available Solr search platform.

Top comments (0)