title: What is LLaVA and LLaVA-Interactive
published: false
date: 2023-11-03 00:00:00 UTC
tags:
canonical_url: http://www.evanlin.com/til-ai-LLaVA-Interactive/
---
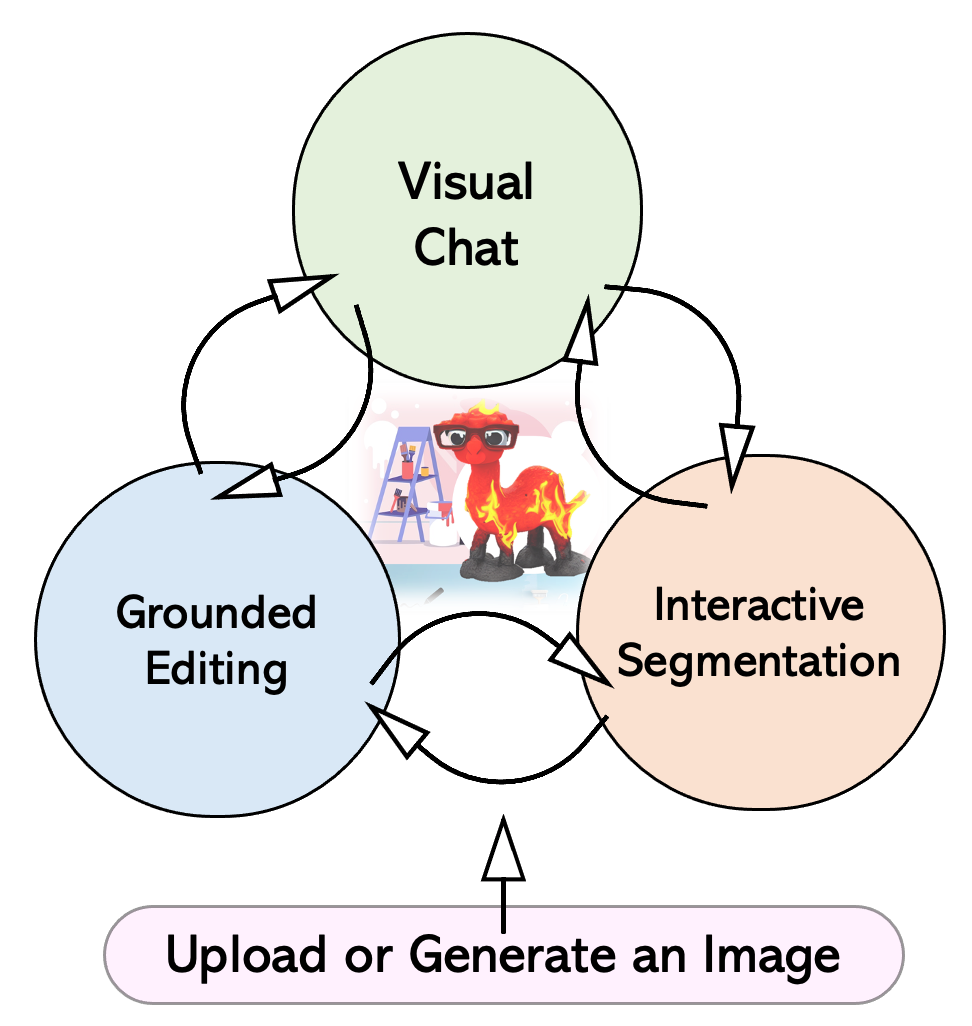
## Premise:
LLaVA-Interactive was looking at Microsoft's new POC (and paper) over the weekend. LLaVA (Large Language-and-Vision Assistant: allows you to have a conversation with an image through an LLM, reportedly the capability of GPT-4V), and Microsoft has built a golden triangle based on this:
- Visual Chat: for understanding images - Grounded Editing: for modifying existing images - Interactive Segmentation: through some interactive modifications
You can modify the image, regenerate it, and then understand and do Visual Chat on the newly generated image.
The paper, Github, and demo are all at https://llava-vl.github.io/llava-interactive/
Note: LLaVA is based on this repo https://github.com/haotian-liu/LLaVA
## Related Paper Abstract:
LLaVA-Interactive is a research prototype system for multimodal AI interaction. The system can engage in multi-round conversations with users by receiving multimodal user input and generating multimodal responses. LLaVA-Interactive is not limited to language prompts and can also align with human intentions through visual prompts. The development of this system is very cost-effective because it combines the three multimodal skills of LLaVA's visual chat, SEEM's image segmentation, and GLIGEN's image generation and editing, without the need for additional model training. By demonstrating various application scenarios, we showcase the potential of LLaVA-Interactive and inspire future research in multimodal interactive systems.
## Actual Demonstration:
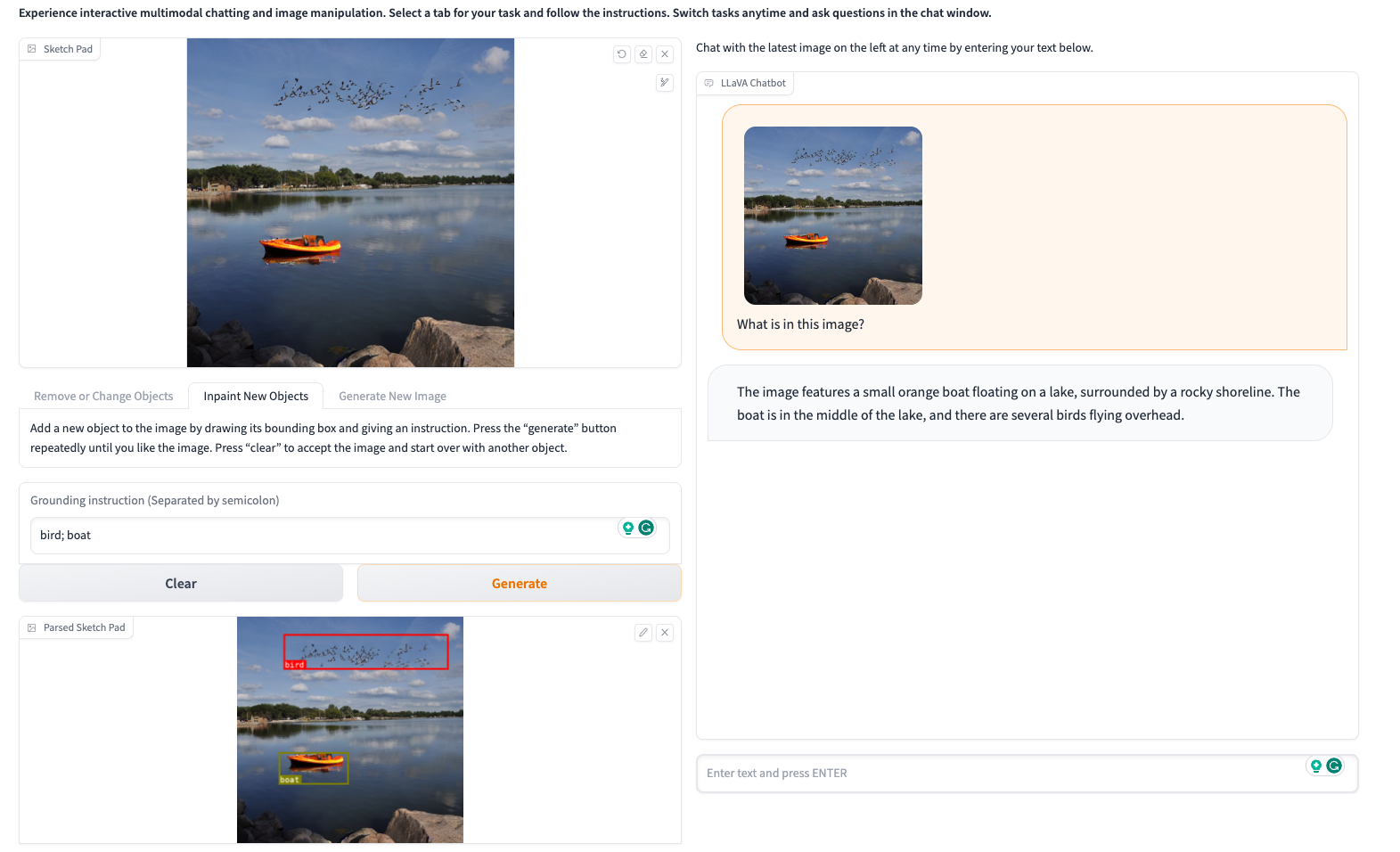
- Upload a picture of a lake on the left
- Modify it by drawing lines (add birds and boats).
- Then on the right, you can chat and understand based on the newly generated image.
Evan Lin
Posted on • Originally published at evanlin.com on
What are LLaVA and LLaVA-Interactive?
For further actions, you may consider blocking this person and/or reporting abuse

Top comments (0)