
Abstract:
Money Laundering is the biggest crime in Banking and Non-Banking sectors, that affects countries economies. Most of the developing Asian countries are facing this money laundering issue due to lack of technology adoption. There are several ways to do money laundering activities, one of them using transactions. In 21st century, money laundering activities are very difficult to detect using manual measures. In this machine learning and artificial intelligence era we can detect or predict estimates on money laundering fraudulent activities through transactions using the ‘SAS AI’ and ‘Machine learning’. These two elements are redefining anti-money laundering (AML hereafter) [02]. After 2015 many companies are closed due to various reasons initiated by Minister of Commerce Affairs (MCA). [5]The effect of Master data unavailability wouldn’t justify the reason why companies are closed by MCA, but it’s significant that Money laundering would have been a major cause.
The main objective of this research is a ML/AI method of detecting money laundering activities using company profiles. Therefore, through these factors: 1) Company profile; 2) Directorships 3) Frequent change of directors in companies; 4) Same directors having multiple directorship 5) Address change; 6) Non Tax filing; 7) Company status (Active, Amalgamation, Strike Off) 5) Authorised Capital; 6) Paid up capital and others may indicate money laundering activities in the businesses. Through machine learning and artificial intelligence supervised, using algorithms with logistics regression, decision tree, Naive Bayes, KNN(K-Nearest Neighbour) and statistical inferential technique MANOVA(multivariate analysis of variance), we can estimate and detect probable fraudulent Money laundering activity [44].
Keywords: Money laundering, Company profiles, Machine Learning/AI Decision Tree MANOVA
Literature Review:
In our research, we followed secondary data review and literature. Sharman (2012) says that shell companies cannot be found to be real authorized owners acted as a corporate veil to proceeds of crime and fraud. The corporate transparency would help law enforcement agents to catch misusing and mismatching owners. As per Sharman (2012), the information on beneficial owners could be accessed in two ways[31]. First, the corporate registry or Know your customer questionnaire (KYC hereafter) information is required to be collected and hold together with proofs about the identity of beneficial owners. Second way is to regulate the company service providers (CSPs hereafter), who could collect information about the beneficial owners of entities and provide the same to regulators upon request. The CSPs may be individuals, law firms or other firms with the sole purpose of incorporating companies [16].
Technologies and anti-money laundering: To find the right Flavour of machine learning approach for predicting ML/CFT(Combating the Financing of Terrorism)[9] depends on the input available for training the model and research objectives. A supervised machine learning model is presented with sample inputs and their associated outputs. The goal is to devise a general rule that maps those inputs to outputs. For example, what attributes were associated with cases that were turned into[11] findings that are associated with false positives or false negatives? The model learns how to predict better the outcome, when it is applied to new data. Some of the more advanced early adopters of AI are getting those pilot projects over the line, and doing so with great results.
Objective of Research:
The objective of the research articles based on the company profile and company financial activities describe and validate ML models for estimating and detecting money laundering issues as these are very difficult to detect using manual investigation methods. After establishment of many start-up companies in many parts of India, increase the need of automated solutions that may detect money laundering activities. They could adopt ML/AI to control money laundering True Positive and False Positive ratings. Factors such as 1) Company profile; 2) Directorships 3) Frequent change of directors in companies; 4) Same directors having multiple directorship 5) Address change; 6) Non Tax filing; 7) Company status (Active, Amalgamation, Strike Off) 5) Authorized Capital; 6) Paid up capital and other criteria may indicate money laundering activities in the businesses.
In general Anti Money Laundering is hypothetical, in this research we tried proving it by applying the theory on the available data by measuring the features of available sample data, presuming that this can be proven using the “statistical inferential experiment”[51] and using special observations. This is subjected to extended investigation, which has resulted that the research has led to a tenable meaning of full information.
When large data is available, we can apply ML algorithms for predicting and estimating future outcome. When data is not sufficient or only small sample is available, we can use inferential statistics for future predictions. Minimum of 30 samples is enough [23] for inferential statistics of future predictions as per the statistical evidence. In our research we have limited data, so with hypothesis assumption we can predict or interfere the default companies list.
Section A:
H0: Company profile & KYC may lead to Money laundering significantly 0.05
H1: it may not s lead to Money laundering .95
Section B:
H0: Based on company profiles we can estimates Fraudulent Detection of Money laundering 0.05
H1: Based on company profiles we can estimates Fraudulent Detection of Money laundering 0.05
Methodologies & Analysis:
As per the above objectives and hypothesis, we intend to implement Statistical Inferential techniques like MANOVA and Machine Learning Supervised, to estimate fraudulent activity with Logistics regression, Decision Tree, Naive Bayes, KNN and Confusion matrix. Confusion matrix will conclude True positive and False positive rating accuracy of future outcome.
Source of Data: ED(Enforcement Directory) and SEBI(Securities and Exchange Board of India) have posted a list of 331 suspected shell companies list. The Ministry of Corporate Affairs[5] and Government of India have built this list of shell companies declared by SEBI. Many of these companies are already listed on the stock exchanges. We randomly collected companies that are not involved in money laundering activities and shell companies for detecting fraudulent activity declared by Government of India[8].
Tools & Techniques. For implementing ML/AI and MANOVA statistical techniques, we used Python, R rattle, SPSS software packages[37]. MANOVA ANALYSIS finding association correlations of the dependent variables and by the effect of sample sizes associated with those independent variables[34]. MANOVA’s power is lowest when the correlation equals the ratio of the smaller to the larger standardized effect size.[10]. In our case, Dependent Variables on Target, which has 1-Fraud and 0-Good.

Data Analysis:
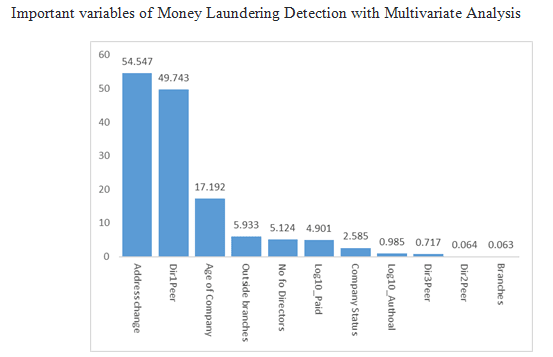
Data Analysis- MANOVA analysis for conducting money laundering is followed by the below MANOVA Inferential Tables. Overall coefficient of effect with Money laundering R Squared = .666 (Adjusted R Squared = .647). No of Directors, F value 5.124, 0.025 sign, Dir1Peer_company 49.743, 0.001 sign, Age of Company F value 17.192 and 0.0001 sign , Address change F value 54.547 sign 0.000, Outside branches F value 5.933, 0.016 sign. Variables are significant with 0.05 [39]. Remaining variables are not significant. For money laundering detection, this significant variable is more influencing.
H0: Company history profile factors leads to money laundering significantly 0.05,
H1: may not Company history profile factors leads to Money laundering. 95% alternate hypothesis are accepted.

ML/AI: For current generation ML is new computing technology [10]. It was born from the theory that computers can learn with training data to perform specific events and tasks. Computers can learn from historical computations to predict reliable information, but one that has gained fresh momentum. To prove hypothesis that it is possible to estimate money laundering activities using company profile with Machine Learning Algorithms such as Logistic regression, Naive Bayes [45], KNN, SVM and model validation techniques such as Confusion matrix, ROC (receiver operating characteristic curve), AUC precision [41]. True positive and false negative cases models’ are explained below:
H0: Based on company profiles we can estimates Fraudulent Detection of Money laundering 0.05
H1: Based on company profiles we can estimates Fraudulent Detection of Money laundering 0.05

Above summary table shows the ML models with prediction rates. From this table we can conclude the possible ML algorithms that has the best prediction of money laundering companies. Using methodologies like confusion matrix, precision and recall, we can derive the binary prediction for the probabilities.
The below shown are the Individual model results:
Logistic regression: Logistic regression will measure relationship of the classification or grouping target variable and multiple independent exploratory variables by estimating probabilities using a logistic function[23], which is the cumulative distribution function of logistic distribution[2]. After building logistics regression models and as the validation table states below, logistic regression estimates 40 companies as True positive (91%) out of 44 Companies not involved in the Money Laundering. Fraudulent False negative (74%) out of 38 companies, is the recall. Overall validation is performed on 87% of companies which are in total 82 companies. So when we applied logistics regression for this data, money laundering companies could be estimated with 87% accuracy [25].
Naive-Bayes Model: This is one of the most prier and posteriors algorithms for most accurate predictions. Model validation table suggest that out of total 82 companies, it is estimated that 40 companies are True positive (91%) out of 44 companies not involved in Money Laundering, Fraudulent False negative (74%) out of 38 companies is the recall. Overall 83%, validation companies total 82 companies.
KNN model: is used for finding nearest variables to predict the future. This model validation table suggests that out of total 82 companies 41 companies are marked as True positive (93%), while out of 44 Companies not involved in the Money Laundering companies, Fraudulent False negatives are 3. Out of 38 companies, 33 are predicted correctly as Fraudulent True negative (87%) and 5 companies as False Negative and it’s called as recall. The overall model accuracy is 90%, resulting in identifying/validating 82 companies that are possible fraudulent.
Decision Tree CHAID model: it is a classified model followed by rules and goals. This models validation table suggests, that out of total 82 companies, 41 companies are predicted as True positive (93%). resulting in 44 companies not involved in Money Laundering, 3 companies are False negative. Fraudulent True negative (92%) out of 38 companies 35 predicted correctly and 3 companies as False Negative and it’s called as recall. The overall model accuracy is 93%, resulting in identifying/validating 82 companies that are possible fraudulent.
Model comparison: while we compare among the models, KNN (k-nearest neighbours algorithm (k-NN) is the best model to predict companies involved in money laundering activities using company profiles. Other models, mentioned in the research, provide similar estimates.

Research Findings:
I. No of Directors: if any company has changed the directors in short span of time on more occasions, that indicates some unusual activity is happening. If the same director is having ties with other companies then that is also alarming. As per the historic data analysis, it is considered if a company changed it’s directors frequently and the directors have ties with some fraudulent companies then such scenarios have led the company towards the money laundering. As per Indian MCA, .025, with 97.75%. Companies, which have more than one director or a director who has worked in more than 3 companies, are strike off and amalgamated. As per our data 75% of companies which had involved in Money Laundering has more than 3 directors and every director was linked with multiple companies.
II. Dir1Peer_company: significant .000 with 99.99% association with dependent variable this is high associated with our target variable followed by the above “No of Directors” variable — if one company has more than three directors, who are associated with other companies, it leads to strike off or amalgamated . This is one of the major causes for money laundering.
III. Age of Company: is one of the major causes for Money Laundering, old companies are non-fraudulent and new companies are Significant .000 with 99.9% fraudulent as per the above result stating. The age of the company since the establishment, has an impact when detecting money laundering activities and old-age companies are more trusted companies with proper and constant auditing. New companies may be shell companies with no proper auditing, therefore, their transparency cannot be judged.
IV. Address change: frequently changing company registration addresses are more fraudulent with significance of .00001 (99.99%). It means that such companies might have no stability and consistency and this might influence the money laundering. Our research data in the bar chart above shows the same.
V. Outside branches: if any company has more branches outside the country, this can be one of the cause for money laundering with significance of .016, with 95% of confidential interval. It is easier to process bulk money transactions through difference channels when having many branches, because company KYC shows and proves legalities.
VI. Paid-up capital: company Paid-up capital is one of the contributors for deciding money laundering activities with significance of .028. If paid-up capital is less, then the authorized capital, which means company has no improvement activities and no developments, when paid-up capital is more which indicating there is a good grout in companies.
Conclusion. Based on our research, we conclude that company’s KYC information and profile are major contributors for detection of money laundering. The statistical inferential method, MANOVA theories are stating that the associating list of significance variables are identified by MANOVA whereas all other significant variables are analysed in the Research. Finding a section of companies with the following attributes: No of Directors, Dir1Peer_company, Age of Company, Address change, outside branches, Paidup_Capital. Are most influential factors / variables influencing/determining in identifying the potential money laundering companies.
ML/AI algorithms suggested that when there is a need to predict possible money laundering companies using Logistics regression, Decision Tree, KNN, SVM, Naive Bayes, we can estimate those companies in model comparisons. KNN is the best model to estimate with all company KYC variables, which are available in MCA[5]. Machine Learning Algorithms are quite capable in predicting Money Laundering activities.
References:
Vaughan, G. (2018), “Shell companies, the role of company and trust service providers, and alternative banking platforms highlighted in NZ Police money laundering report”.
SAS Corporation Articles
Luna, D. K., Palshikar, G. K., Apte, M. and Bhattacharya, A. (2018), “Finding shell company accounts using anomaly detection”, Proceedings of the ACM India Joint International Conference on Data Science and Management of Data, Goa, India, ACM pp. 167- 174
Lee, A. and Palstra, N. (2018), “The Companies We Keep: What The UK’s Open Data Register Actually Tells Us About Company Ownership”, United Kingdom, Global Witness.
Chen, T. and Guestrin, C. (2016), “Xgboost: a scalable tree boosting system”, Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ACM, pp. 785–794
DeLong, E.R., DeLong, D.M. and Clarke-Pearson, D.L. (1988), “Comparing the areas under two or more correlated receiver operating
Zauba Corp is India’s leading provider of commercial information and insight on businesses.
Learn more at sas.com/en_us/software/anti-money-laundering.
Grint, R. O’Driscoll, C. and Patton, S. (2017), “New technologies and anti-money laundering compliance report”
Machine Learning: Algorithms, Real-World Applications and Research Directions Iqbal H. Sarker1,2 Received: 27 January 2021 / Accepted: 12 March 2021 / Published online: 22 March 2021 © The Author(s), under exclusive licence to Springer Nature Singapore Pte Ltd 2021
kokrim (2016), Annual Report. The National Authority for Investigation and Prosecution of Economic and Environmental Crime
Lopez-Rojas, E.A. and Axelsson, S. (2012), Money Laundering Detection Using Synthetic Data, the 27th Annual Workshop of the Swedish Artificial Intelligence Society (SAIS), 14–15 May 2012, Link«oping University Electronic Press, Örebro, pp. 33–40
Whitrow, C., Hand, D.J., Juszczak, P., Weston, D. and Adams, N.M. (2009), “Transaction aggregation as a strategy for credit card fraud detection”, Data Mining and Knowledge Discovery, Vol. 18 №1, pp. 30–55.
Regulatory Reform On The Company Service Providers Regime
The Norwegian Money Laundering Act, Chapter 3 (2009), “The Norwegian money laundering act, chapter 3”, In Norwegian
US Congress (1995), “Office of Technology Assessment, Information Tech- neologies for Control of Money
Whitrow, C., Hand, D.J., Juszczak, P., Weston, D. and Adams, N.M. (2009), “Transaction aggregation as a strategy for credit card fraud detection”, Data Mining and Knowledge Discovery, Vol. 18 №1, pp. 30–55.
Singh, K. and Best, P. (2019), “Anti-Money Laundering: Using data visualization to identify suspicious activity”, International Journal of Accounting Information Systems.
Song, X., Hu, Z., Du, J. and Sheng, Z. (2014), “Application of Machine Learning Methods to Risk Assessment of Financial Statement Fraud: Evidence from China”, Journal of Forecasting, Vol. 33 №8, pp. 611–626
Sample size estimation and power analysis for clinical research studies.
UNODC (2004), “United Nations Convention Against Transnational Organized Crime and the Protocols Thereto”, Vienna, United Nations
Vaughan, G. (2018), “Shell companies, the role of company and trust service providers, and alternative banking platforms highlighted in NZ Police money laundering report”.
Walker, J. (1999), “How Big is Global Money Laundering?”, Journal of Money Laundering Control, Vol. 3 №1, pp. 25–37.
Wedge, R., Kanter, J. M., Rubio, S. M., Perez, S. I. and Veeramachaneni, K. (2017), “Solving the” false positives” problem in fraud prediction”, arXiv preprint arXiv:1710.07709.
Zdanowicz, J. S. (2004a), “Detecting money laundering and terrorist financing via data mining”, Communications of the ACM, Vol. 47 №5, pp. 53–55.
Zdanowicz, J. S. (2004b), “U.S. Trade with the World and Al Qaeda Watch List Countries — 2001: An Estimate of Money Moved Out of and Into the U.S. Due to Suspicious Pricing in International Trade”
Yujin O, Park S, Ye JC. Deep learning covid-19 features on cxr using limited training data sets. IEEE Trans Med Imaging. 2020;39(8):2688–700.
Otter DW, Medina JR , Kalita JK. A survey of the usages of deep learning for natural language processing. IEEE Trans Neural Netw Learn Syst. 2020.
Park H-S, Jun C-H. A simple and fast algorithm for k-medoids clustering. Expert Syst Appl. 2009;36(2):3336–41.
Liii Pearson K. on lines and planes of closest ft to systems of points in space. Lond Edinb Dublin Philos Mag J Sci. 1901;2(11):559–72.
Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, Blondel M, Prettenhofer P, Weiss R, Dubourg V, et al. Scikit-learn: machine learning in python. J Mach Learn Res. 2011;12:2825–30.
Perveen S, Shahbaz M, Keshavjee K, Guergachi A. Metabolic syndrome and development of diabetes mellitus: predictive modeling based on machine learning techniques. IEEE Access. 2018;7:1365–75.
Santi P, Ram D, Rob C, Nathan E. Behavior-based adaptive call predictor. ACM Trans Auton Adapt Syst. 2011;6(3):21:1–21:28.
Polydoros AS, Nalpantidis L. Survey of model-based reinforcement learning: applications on robotics. J Intell Robot Syst. 2017;86(2):153–73.
Puterman ML. Markov decision processes: discrete stochastic dynamic programming. John Wiley & Sons; 2014.
Wasserstein RL, Lazar NA. The ASA’s statement on P values: Context, process, and purpose. Am Stat. 2016;70:129–33.
Zhu H, Chen E, Xiong H, Kuifei Y, Cao H, Tian J. Mining mobile user preferences for personalized context-aware recommendation. ACM Trans Intell Syst Technol (TIST). 2014;5(4):58.
Zikang H, Yong Y, Guofeng Y, Xinyu Z. Sentiment analysis of agricultural product ecommerce review data based on deep learning. In: 2020 International Conference on Internet of Things and Intelligent Applications (ITIA), IEEE, 2020; pages 1–7
Zulkernain S, Madiraju P, Ahamed SI. A context aware interruption management system for mobile devices. In: Mobile Wireless Middleware, Operating Systems, and Applications. Springer. 2010; pages 221–234 140. Zulkernain S, Madiraju P, Ahamed S, Stamm K. A mobile intelligent interruption management system. J UCS. 2010;16(15):2060–80.
Tsagkias M. Tracy HK, Surya K, Vanessa M, de Rijke M. Challenges and research opportunities in ecommerce search and recommendations. In: ACM SIGIR Forum. volume 54. NY, USA: ACM New York; 2021. p. 1–23.
Srinivasan V, Moghaddam S, Mukherji A. Mobileminer: mining your frequent patterns on your phone. In: Proceedings of the International Joint Conference on Pervasive and Ubiquitous Computing, Seattle, WA, USA, 13–17 September, pp. 389–400. ACM, New York, USA. 201Rasmussen C. The infnite gaussian mixture model. Adv Neural Inform Process Syst. 1999;12:554–60.
Ravi K, Ravi V. A survey on opinion mining and sentiment analysis: tasks, approaches and applications. Knowl Syst. 2015;89:14–46.
Rokach L. A survey of clustering algorithms. In: Data mining and knowledge discovery handbook, pages 269–298. Springer, 2010.
Safdar S, Zafar S, Zafar N, Khan NF. Machine learning based decision support systems (dss) for heart disease diagnosis: a review. Artif Intell Rev. 2018;50(4):597–623.
Sarker IH. Context-aware rule learning from smartphone data: survey, challenges and future directions. J Big Data. 2019;6(1):1–25.
Szegedy C, Liu W, Jia Y, Sermanet P, Reed S, Anguelov D, Erhan D, Vanhoucke V, Rabinovich A. Going deeper with convolutions. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2015; pages 1–9.
Tavallaee M, Bagheri E, Lu W, Ghorbani AA. A detailed analysis of the kdd cup 99 data set. In. IEEE symposium on computational intelligence for security and defense applications. IEEE. 2009;2009:1–6
Thornton, Wayne (2000). Applied Research Projects, Texas State University.
Hypothesis testing and earthquake prediction (probability/significance/likelihood/simulation/Poisson) DAVID D. JACKSON Southern California Earthquake Center, University of California, Los Angeles, CA 90095–1567

Top comments (0)