
This article mainly introduces how to migrate your data from Neo4j to NebulaGraph with NebulaGraph Exchange (or Exchange for short), a data migration tool backed by the NebulaGraph team. Before introducing how to import data, let’s first take a look at how data migration is implemented inside NebulaGraph.
Data processing in NebulaGraph Exchange
The name of our data migration tool is NebulaGraph Exchange. It uses Spark as the import platform to support huge dataset import and ensure performance. The DataFrame, a distributed collection of data organized into named columns, provided by Spark supports a wide array of data sources. With DataFrame, to add new data source, you only need to provide the code for the configuration file to read and the Reader type returned by the DataFrame.
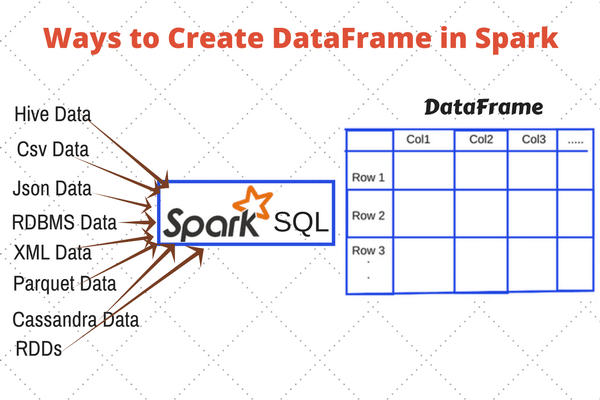
As mentioned above, a DataFrame is a distributed collection of data organized into rows and columns. A DataFrame can be stored in multiple partitions. The partitions are stored on different machines to support parallel operations. Besides, Spark also provides a set of APIs that allow users to operate DataFrames easily, just like operating locally. What’s more, most of the databases support exporting data into DataFrames. Even if a database does not provide such a function, you can manually build a DataFrame with the database driver.
After transforming data into a DataFrame, NebulaGraph Exchange traverses each row in the DataFrame, obtain the corresponding values by column names according to the fields mapping relationship in the configuration file. After traversing batchSize rows, Exchange writes the obtained data into NebulaGraph at one time. Currently, Exchange generates nGQL statements and then writes data asynchronously by the Nebula Client. We will support exporting the sst files stored in the underlying storage of Nebula Graph to acquire better performance. Next, let's move on to the implementation of Neo4j data import.
Implementing Data Import from Neo4j
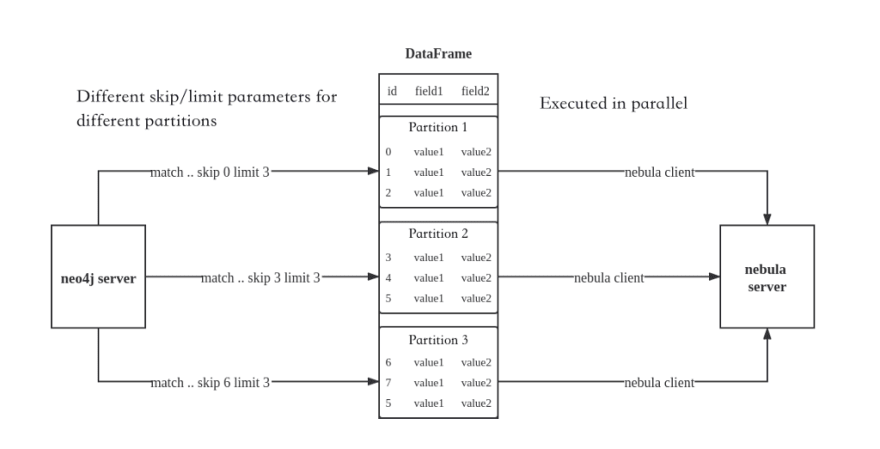
Neo4j provides an official library to export data directly as a DataFrame. However, it doesn’t support resumable downloads. Therefore, we did not use this library directly. Instead, we use the official Neo4j driver to read data. To obtain better performance, Exchange executes different skip and limit Cypher statements by calling Neo4j drivers on different partitions, and distributes data to different partitions. The number of partitions is specified by the configuration parameter partition.
Exchange imports the Neo4j data in the following steps: First, the Neo4jReader class in Exchange replaces the Cypher statement exec and statement after the return in the user configuration with count(*) and executes them to obtain the total data size. Second, the Exchange calculates the initial offset and size for each partition according to the partition number. If parameter check_point_path is configured, Exchange reads the file under this directory, too. If the download is in resumable status, Exchange calculates the initial offset and size for each partition, then adds different skip and limit after the Cypher statements in each partition and calls the driver to execute. Last, Exchange transforms the returned data to DataFrame.
The procedure is demonstrated in the following picture:
Practice Data Importing from Neo4j to Nebula Graph
We use the following system environment to demonstrate the import here:
Hardware:
- CPU name: Intel(R) Xeon(R) CPU E5–2697 v3 @ 2.60GHz
- CPU cores: 14
- memory size: 251G
Software:
- Neo4j version: 3.5.20 community
- Nebula Graph: Deployed with Docker Compose. We use the default configurations and deploy Nebula Graph on the preceding machine.
- Spark: Single node. Version: 2.4.6 pre-build for hadoop2.7.
Since Nebula Graph is a strongly-typed schema database, you need to create a space, tags, and edges types before importing data. For more information, see Create space syntax.
Here we create a space named test, with the replication number as one. We create two types of tags: tagA and tagB. Both have four properties. In addition, we create an edge type edgeAB, which also has four properties. The nGQL queries are as follows:
# Create graph space test
CREATE SPACE test(replica\_factor= 1);
# Use graph space test
USE test;
# Create tag tagA
CREATE TAG tagA(idInt int, idString string, tboolean bool, tdouble double);
# Create tag tagB
CREATE TAG tagB(idInt int, idString string, tboolean bool, tdouble double);
# Create edge type edgeAB
CREATE EDGE edgeAB(idInt int, idString string, tboolean bool, tdouble double);
Now let’s import the Mock data to Neo4j. The Mock data contains one million vertices labeled with tagA and tagB, ten million edges labeled with edgeAB. Note that data exported from Neo4j must have properties, the data type must be exactly the same as that of Nebula Graph.
Finally, to speed up the Mock data importing to Neo4j and improve the read performance, we created indexes for the property idInt both in tagA and tagB. Attention here, Exchange does not import indexes and constraints to Nebula Graph. So do remember to create and rebuild index.
Then we import the data from Neo4j to Nebula Graph. First let’s download and pack the project. You can find the project in the tools/exchange directory of the nebula-java repository. Run the following commands:
git clone https://github.com/vesoft-inc/nebula-java.git
cd nebula-java/tools/exchange mvn package -DskipTests
Then you see the target/exchange-1.0.1.jar file.
Next, we move to the configuration file. The format of the configuration file is HOCON (Human-Optimized Config Object Notation). Let’s modify based on the src/main/resources/server_application.conf file. First, configure address, user, pswd, and space for Nebula Graph. We use the default test environment here so we don't modify anything here. Next, configure the tags. We only demonstrate configurations for tagA because configurations for tagB are the same as that of tagA.
{
# ====== connection configuration for neo4j=======
name: tagA
# Must be exactly the same as the tag name in Nebula Graph. Must be created before importing.
server: "bolt://127.0.0.1:7687"
# address configuration for neo4j
user: neo4j
# neo4j username
password: neo4j
# neo4j password
encryption: false
# (Optional): Whether to encrypt the transformation. The default value is false.
database: graph.db
# (Optional): neo4j databases name, not supported in the Community version
# ======import configurations============
type: {
source: neo4j
# PARQUET, ORC, JSON, CSV, HIVE, MYSQL, PULSAR, KAFKA...
sink: client
# Write method to Nebula Graph, only client is supported at present. We will support direct export from Nebula Graph in the future.
}
nebula.fields: [idInt, idString, tdouble, tboolean]
fields : [idInt, idString, tdouble, tboolean]
# Mapping relationship fields. The upper is the nebula property names, the lower is the neo4j property names. All the property names are correspondent with each other.
# We use the List instead of the Map to configure the mapping relationship to keep the field order, which is needed when exporting nebula storage files.
vertex: idInt
# The neo4j field corresponds to the nebula vid field. The type must be int.
partition: 10
# Partition number. batch: 2000 # Max data write limit.
check\_point\_path: "file:///tmp/test"
# (Optional): Save the import information directory, used for resumable downloads.
exec: "match (n:tagA) return n.idInt as idInt, n.idString as idString, n.tdouble as tdouble, n.tboolean as tboolean order by n.idInt"
}
The configurations for edges are similar to that of vertices. However, you need to configure source vid and destination vid for edges because a Nebula Graph edge contains source vid and destination vid. The edge configurations are as follows:
source: {
field: a.idInt
# policy: "hash"
}
# configuration for source vertex ID
target: {
field: b.idInt
# policy: "uuid"
}
# configuration for destination vertex ID
ranking: idInt
# (Optional): The rank field.
partition: 1
# Set partition number as 1. We set it to one here. We will talk about the reason later.
exec: "match (a:tagA)-[r:edgeAB]->(b:tagB) return a.idInt, b.idInt, r.idInt as idInt, r.idString as idString, r.tdouble as tdouble, r.tboolean as tboolean order by id(r)"
You can use the hash policy or the UUID policy for vertices, edge source vertices, and edge destination vertices. The hash/uuid function maps the string type fields into the integer type fields.
Because the preceding example uses integer VIDs, no policy setting is needed. See here to know the difference between hash and uuid.
In Cypher, we use keywords ORDER BY to ensure the same order for the same query. Although the returned data order seems the same without ORDER BY, to avoid data loss in data importing, we strongly suggest using ORDER BY in Cypher, though the importing speed is sacrificed to some extent. To raise the importing speed, you'd better sort the indexed properties. If there aren't any indexes, check the default order and choose a suitable one to improve performance. If you can't find any sorting rules in the default returned data, you can sort the data by the vertex/edge ID, and set the partition value as small as possible to reduce the sorting pressure for Neo4j. That's why we set the partition number to one in this example.
In addition, Nebula Graph uses ID as the unique primary key when creating vertices and edges. If the primary key exists before inserting new data, the old data under the primary key will be overwritten. Therefore, using repetitive Neo4j property values as the Nebula Graph ID will lead to data loss because vertices with the same ID are regarded as one vertex and only the last write is saved. Since the data importing to Nebula Graph is parallel, we don’t guarantee that the final data is the latest data in Neo4j.
Another thing you need to pay attention to is the resumable download. Between the breakpoint and the resume, the database must not change status, for example inserting or deleting data is not allowed. The partition number mustn't be modified or data loss can occur.
Finally, because Exchange executes different skip and limit Cypher queries on different partitions, the users mustn't provide queries including skip and limit.
Next, run the Exchange to import data. Execute the following commands:
$SPARK\_HOME/bin/spark-submit --class com.vesoft.nebula.tools.importer.Exchange --master "local[10]" target/exchange-1.0.1.jar -c /path/to/conf/neo4j\_application.conf
Under the preceding configurations, importing one million vertices takes 13 seconds, importing ten million edges takes 213 seconds. Thus the total importing takes 226 seconds.
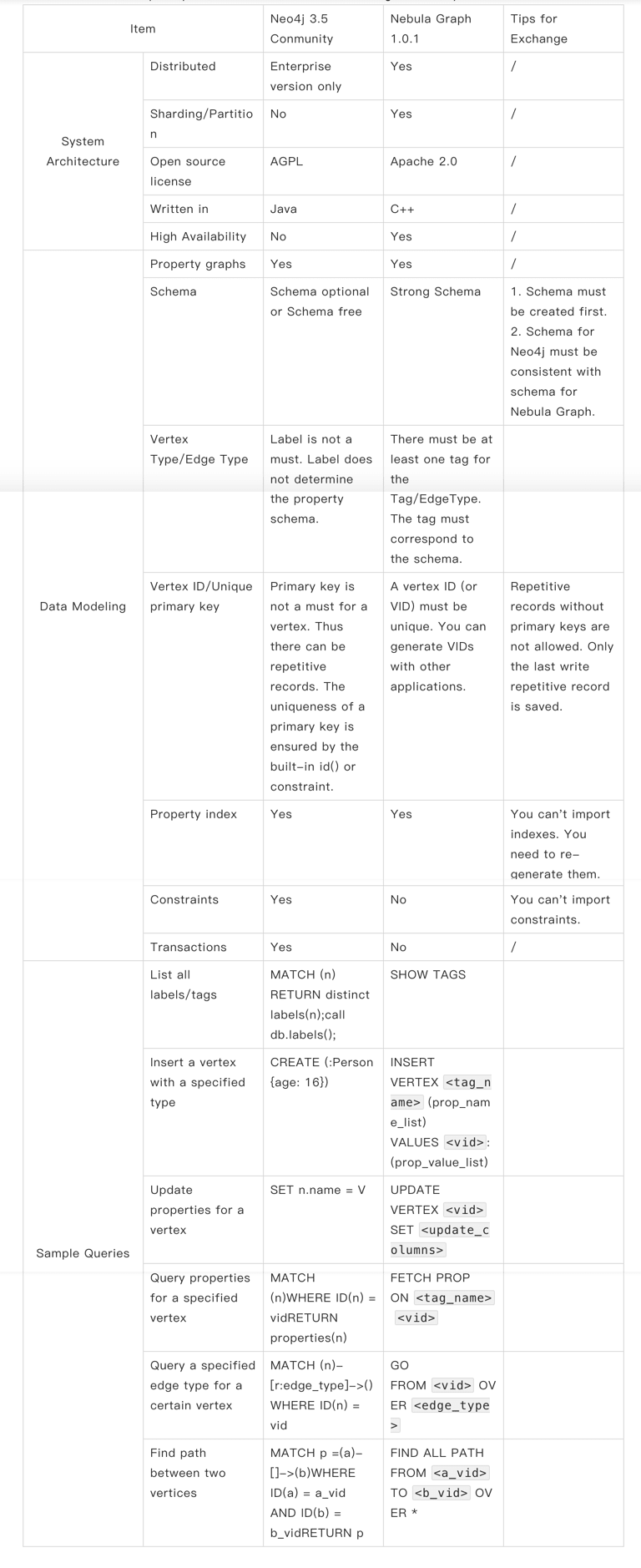
Appendix: Comparisons between Neo4j 3.5 Community and Nebula Graph 1.0.1
Neo4j and Nebula Graph are different in system architecture, data model, and access method. So we have listed some frequently-seen differences in the following table for your reference:
Hi, I’m Mengjie Li, the software engineer in Nebula Graph. Currently I am involved in storage engine development. I hope this article is helpful and let me know if you have any thoughts and suggestions. Thanks!
You might also like
- New Players: Something You Should Know When Reading Nebula Graph Source Code
- Performance Comparison: Neo4j vs Nebula Graph vs JanusGraph
Like what we do ? Star us on GitHub. https://github.com/vesoft-inc/nebula
Originally published at https://nebula-graph.io on September 17, 2020.

Top comments (0)