When using AWS API Gateway and Lambda, you will probably reach a few limitations, in this article, I will explain how I created one workaround to overcome the 29 seconds of maximum API Gateway request and 6mb of maximum body payload size.
As an example, on our administrative dashboard, some data will be collected from MySQL and Elastic Search, that can be very slow in some cases.
On our front-end, an React app, the request can take up to 15 minutes (maximum lambda execution time), the usage will be simple as that:
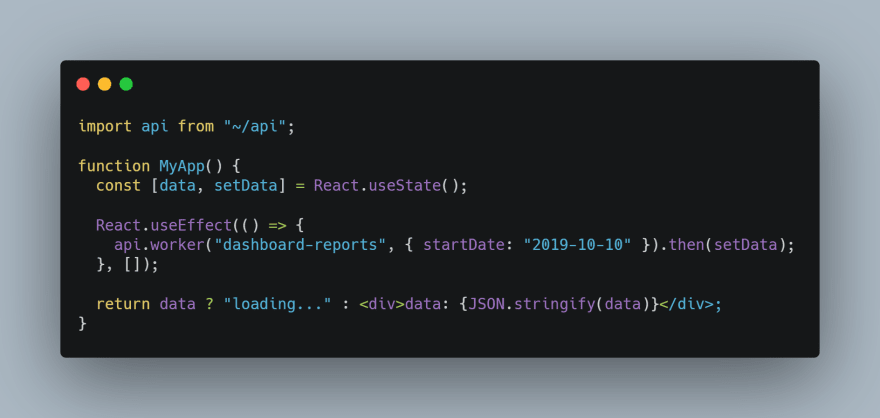
The api.js file will contain:

The resume of back-end architecture:
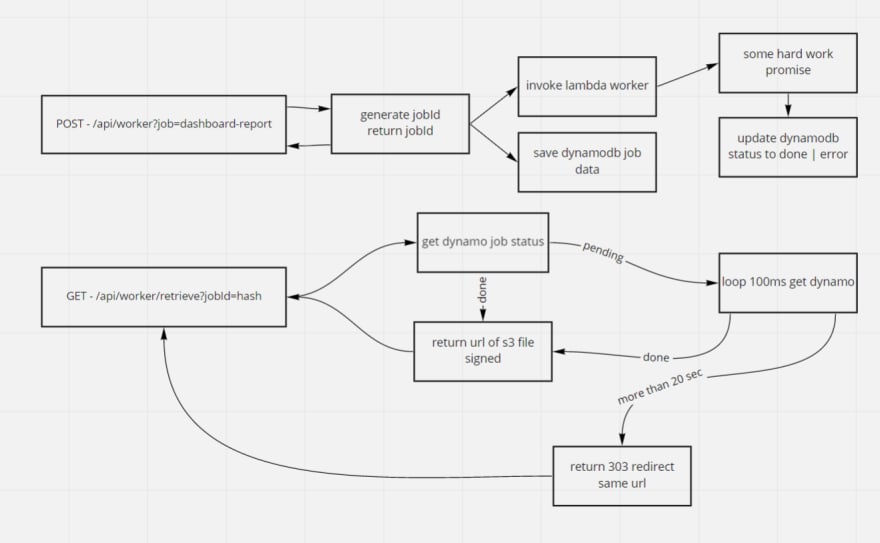
First, start de workflow sending a POST request, passing any necessary parameters in body. This request needs a “type” parameter to define what function will be executed in the lambda worker. That request return the jobId for future use.
An item is created in the DynamoDB workers table, with jobId as hashkey and status as “pending”.
When worker promise function is done, with error or not, that DynamoDB item will be updated with the new status and S3 key of the result, that can be a JSON, XLSX or any useful type.
On front-end, using the received jobId, we fire another request, GET /api/worker/retrieve, passing jobId as query parameter. This request starts a Lambda function that verify if worker is done.
Case status is done, get the URL of S3 that have been saved later, sign that url with 1 hour to expires, then return to front-end.
Case status is pending, make a loop to verify every 100ms if status have changed, if elapsed time is more than 21 seconds, return a 303 redirect with the same URL, so front-end doesn’t need to fire the request again, browser will handle that for us.
After all that, front-end will receive a URL to a S3 file, if type is JSON, I make a new request to it and parse, if not, just return the URL.

Top comments (0)