
If you're an active internet user then you've probably been accused of being a robot, at least once. It's known as CAPTCHA.
In this article, you'll learn about Captcha, what it is, why it is used and why it keeps changing.
Captcha was created in 2000 and stands for Completely Automatic Public Turing Test to Tell Computers and Humans Apart. Baiscally, it is a program that protects websites against bots by generating and grading tests that humans can pass but current computer programs cannot.
Captchas are being used for
- protecting website registration
- protecting online polls by stopping robots to send in repeated responses
- stopping brute force attacks (where hackers/bots repeatedly try to log in using different passwords)
- preventing users/hackers from signing up for multiple email accounts
- stopping content spamming
- ...
Now let's talk about its history and development.
Back in 1990's people could write programs to sign up for millions of accounts. Those people were called spammers . Of course, tech companies needed a way to stop that. And that was one of the 10 Hardest Problems Yahoo Don't Know How To Solve.
Luis von Ahnwas (who is also co-founder and CEO of DuoLingo) was part of the CAPTCHA team. The team figured out that they need a test, which humans could pass, regardless of their age, education, etc.
In the main version of Captcha we were asked to read and type a distorted word from an image (things that humans could do but computers couldn't at that time).

But computers also had to be able to grade it. The solution was to put the right answer with the image into the database.
In 2005 a new version was released, called ReCaptcha.

This one used 2 words - the first one was a distorted text for which the computer had the right answer.
The second word was an image of a word from a book or an article. The computer didn't have the answer for the second word but if the user got the first word right, the computer assumed, that the second word is right as well and stored the data. The same image was used multiple times on different users and the most common answer was usually used as a right answer.
This all served as data, which helped computers to get smarter, smart enough to recognize letters and words from new images. In other words, we taught computers to read warped texts.
2014 Google computer learning study states, that a human could read most distorted CAPTHCAs with 33% accuracy. Meanwhile, their AI could do the same with ..... 99.8% accuracy. It's impressing, how we taught them to do something better than us, isn't it?
Since computers could do that better than humans, it was а time for а change.
The new version of ReCaptcha, ReCaptcha V2 was introduced in 2014, which featured images instead of distorted texts. The purpose is the same - to differentiate humans and computers.
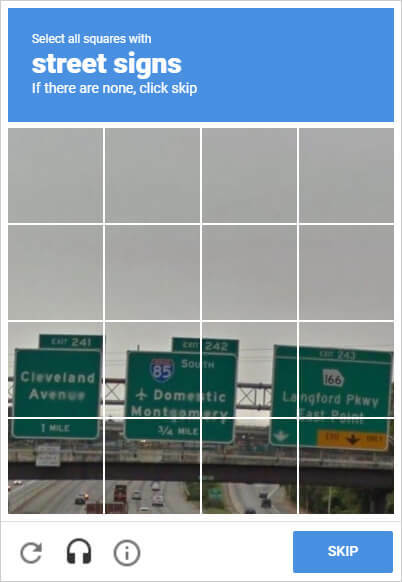
And we are still helping computers to get smarter.
Most of the time we have to select cars, crossroads, and traffic lights from images. Google uses this data to improve its self-driving cars, so they can see those objects. Data is also used for improving Google Maps.
But as before, during the time computers become smarter and they can recognize items better than humans and the time for changes came again and this time ReCaptcha V3 was introduced.

There is not much that can be said for this one because it's a guarded secret. All we know is that our actions are being tracked from the minute we enter a website, which is using ReCaptcha V3. And by the time we click the submit button, we have already gotten our human badge (well, at least most of us, haha) and we don't need to find items from images.
Websites, that use ReCaptcha V3 have their benefits (more protected, clean from bots, etc) but we have to sacrifice our privacy to stay safe from bots and scams. Whether you want it or not, you are being tracked 90% of the time.

Top comments (0)