
Serverless is a design pattern which aims to remove many issues development teams typically face when maintaining servers or services, enabling them to focus on delivering value and benefit quickly and efficiently.
However using a large amount of serverless resources also has its drawbacks, in particular the difficulties in testing.
In this blog I aim to discuss some of these problems, and propose a solution for testing heavily serverless workflow’s through regression testing.
The Different Types of Testing
When building applications it’s important that we write comprehensive test coverage to ensure our application behaves as expected, and protects us from unexpected changes during iteration.
In both traditional and serverless development, when building apps and workflow’s that involve calls to other services, we need to test the boundaries.
But how do we do this when our boundaries are managed services?
Before continuing it’s important to understand the difference between unit, integration, and regression tests, as they are often easily mixed up:
Unit test
The smallest type of test, where we test a function. When following Test Driven Development these are the kind of tests we write first.
Given a function def addOne(input: Int): Int = input + 1 we would expect a corresponding test which may look something like:
addOne(-1) shouldEqual 0addOne(0) shouldEqual 1
Integration test
A larger test, where we test a workflow which may call many functions. These are more behaviour focused and target how our system expects to run given different inputs.
Given an application with an entrypoint def main(args: Seq[String]): Unit we may expect an integration test to look something like:
main(Seq("localhost:8000", "/fake-url", "30s")) shouldRaise 404main(Seq("localhost:8000", "/mocked-url", "30s")) shouldNotRaiseException
Regression test
The largest type of test, also thought of as a systems test. While unit and integration tests look to test how our application behaves during changes to it, regression tests look to test how our systems behave due to our application changing. They also prevent unexpected regressions due to development.
While integration testing of an api crawler may test what happens to the app when the api goes offline by utilising a local mock, regression testing should test what happens to downstream services should that api go offline.

Problems with Serverless
Let's work through a real world example where we will see that relying only on unit and integration tests is not enough for even simple serverless workflow’s.
Given this demo workflow:

- AWS Lambda runs some simple code to get data from an api, do some processing, and publish the results to an S3 bucket
- S3 bucket has an event trigger that sends an alert to an SNS topic when new data is published to it
- SNS topic sends an email to users letting them know that the data is available to download from a link
- Users access the link, which is an AWS API Gateway endpoint, to download the data
We'll assume the Lambda has unit and integration tests. These may use mocks and utilities to test how this simple code would handle the various response codes, and capture the messages being sent to S3. This is testing the boundaries of the Lambda, however this leaves much of our workflow untested.
In a traditional stack, where we would be self provisioning servers we could test these by running containers for them. However how do we do this with managed/cloud-native services which are not available in the form of local containers?
Serverless and self provisioned servers may bear similarities, but they’re not the same, and any tests using it as a replacement would provide little benefit. However if we only test the Lambda code then we are leaving much of our workflow untested.
What happens if someone logs into the console and changes the SNS topic name?
The Lambda will still pass it’s unit and integration tests, and it will still publish data to the S3 bucket. However the SNS topic will no longer receive the event, and won’t be able to pass on alert to our users - our workflow is broken, and even worse we’re not aware of it.

This is the catch-22 of testing managed/cloud-native serverless - as our workflow’s become more complicated, we need rigorous testing, but the more services we include the less tested our workflow becomes.
This is why regression/systems testing becomes more important with serverless workflow’s, and why it should become more of the norm.
Regression Testing Serverless Workflows
So now that we understand what we want to test, and why it's important, we need to find a way of testing it.
The traditional approach would be to deploy the stack onto an environment, where someone can manually trigger and evaluate the workflow. This is testing the happy path, as it doesn’t evaluate all the permutations of different components changing.
Additionally, due to the manual process involved we are unlikely to be able to evaluate this frequently, and instead may only do this once per release which could contain many changes. Should we find any regressions, it becomes harder to identify the root cause due to the multiple changes that have been implemented between releases.
This doesn’t scale well when we have more complex workflows that utilise parallel and diverging streams (for an example of such read my blog on building serverless data pipelines).
So, how do we do better?
Well, what we can do is take the same approach used for unit and integration tests, and look at how we can test our remit (in this case our entire workflow) as a black box.
We can achieve this by;
- Spinning up infrastructure around our workflow
- Running a suite of tests to start the workflow
- Asserting on the results at the end of the workflow
- Destroying our test infrastructure afterwards - to do which we need to leverage IaC (Infrastructure as Code) tools such as terraform.
For our demo workflow, we would achieve this by deploying managed/cloud-native services, which the Lambda at the start of our workflow will connect to, in lieu of the real external API.
We can then run a suite of tests to trigger the Lambda, and assert the expected results exist at the end of our workflow via the workflow API Gateway.
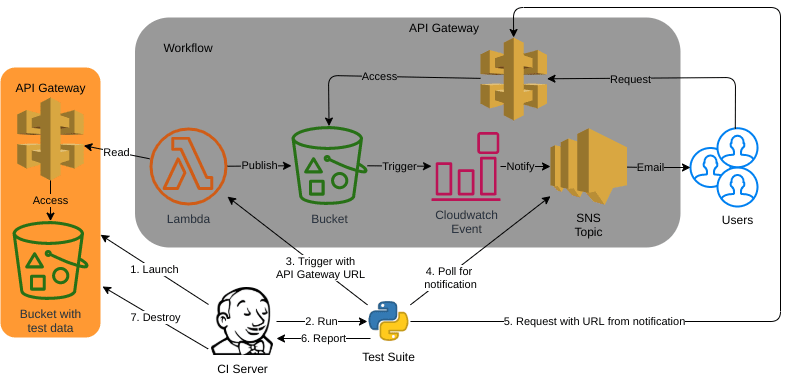
With this approach, we can now automate the traditional manual QA testing, and ensure we cover a much wider spectrum of BDD test cases, including scenarios such as “What alert do/should our users receive if the API is unavailable?”.
In traditional unit/integration testing we wouldn’t be able to answer or test for this, as this process is handled outside of the Lambda. We could test what happens to the Lambda in the event of the external API becoming unavailable, but not how downstream processes would react - we’d be reliant on someone manually trying to mimic this scenario, which doesn’t scale.
Furthermore, utilising IaC we can run a huge barrage of these larger workflow tests in parallel, and easily scale these up to incorporate elements of load and chaos testing.
Instead of being reactive to our workflow breaking, we can push the limits to establish our redundancy prior to experiencing event outages.
Conclusions
Hopefully I’ve sold you on the idea of regression/systems testing, and why as we move to a more serverless world, we need to establish a more holistic view on testing our systems as a whole, rather than only the components in isolation.
It’s not to say that we should abandon the faithful unit test in favour of systems testing, but why we should not fall into the fallacy that just because our “code” is tested, our systems and workflows are also tested.
This also highlights why Development, QA, and DevOps are not activities done in isolation by separate teams. Having a key understanding of each is required to implement and test such a workflow, and that ideally both the workflow and test framework should be implemented by a single cross functional team, rather than throwing tasks over the fence.
For more on AWS and serverless, feel free to check out my other blogs on Dev.to, and my website, Manta Innovations

Top comments (0)